

支持 AI 的 SoC 处理多个视频流
Ambarella 推出两款用于计算机视觉和 AI 处理的设备,来自多个或安全摄像头和智慧城市系统的单一输入。
图像处理专家 Ambarella 推出了两款用于单传感器和多传感器安全摄像头的新 SoC,每款都具有由公司的 CVflow AI 加速器引擎支持的新 AI 功能。两者都支持4K视频编码和高级AI处理,例如面部识别或车牌识别。
CV5S SoC 面向多传感器相机系统,可对四个分辨率高达 8MP/4K 的成像器通道进行编码,每个通道的速度为每秒 30 帧 (fps),同时对每个 4K 图像流执行高级 AI。它最多可以处理 14 个输入。 SoC 系列将 Ambarella 上一代产品的编码分辨率和内存带宽提高了一倍,同时功耗降低了 30%。它消耗 <5W 并提供 12 eTOPS(相当于 GPU 的 TOPS,Ambarella 衡量运行相同 AI 处理任务所需的 GPU 马力量)。
另一款新 SoC CV52S 面向单传感器相机,支持 60 fps 的 4K 分辨率。与前几代 Ambarella SoC 相比,这款新设备的 AI 性能提高了四倍,CPU 吞吐量提高了一倍,内存带宽提高了 50%。它消耗 <3 W 并提供 6 eTOPS。
性能提升源于向 5 纳米工艺节点的迁移以及对 Ambarella 内部 CVflow AI 加速器块的改进和扩大。
Ambarella 的高级营销总监杰罗姆·吉戈特 (Jerome Gigot) 说:“你看到所有这些初创公司都来自世界各地,都说他们的每瓦特人工智能性能最好,而且他们可能是对的。” “但这并不能制造相机,也不能制造产品。如果你只有一个人工智能加速器,你就只有一个人工智能加速器。”
Gigot 指出,4K 或 8K 视频的成像管道很复杂,需要处理大量数据,编码大量数据,将这些数据传输到一个特殊的块进行 AI 处理,同时可能在顶部运行 Linux 堆栈。在保持视频质量的同时,在低功耗预算下很难实现这一目标。
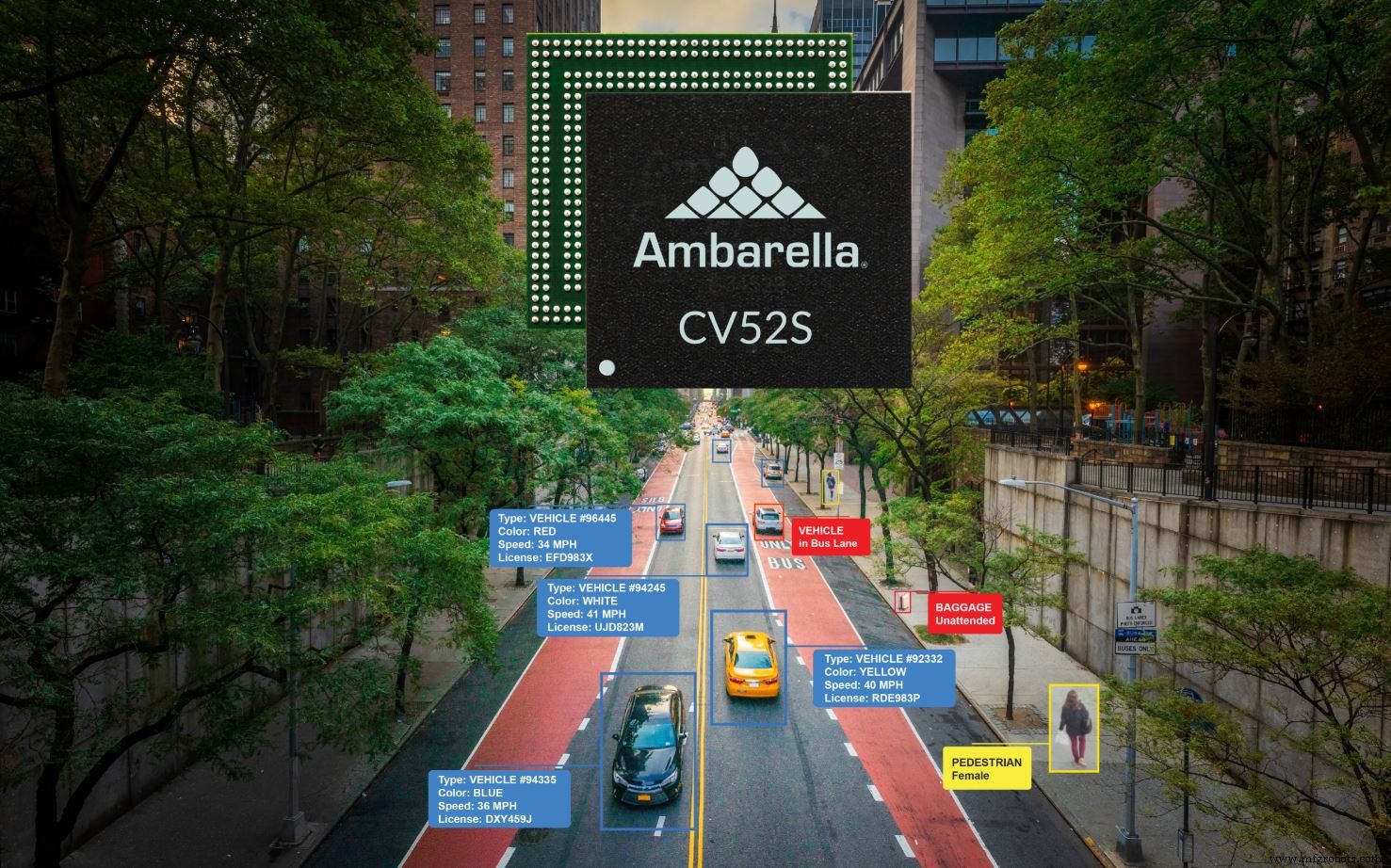
CV52S 的目标是单传感器设计,如交通监控和其他智慧城市应用中的设计(来源:Ambarella)
除了 CVflow AI 加速器,两款新 SoC 还包括 Ambarella 的图像信号处理器 (ISP),可处理色彩处理、自动曝光、自动白平衡和噪声过滤等功能。
“这个街区我们已经开发了 16 年,”Gigot 说。 “这就是为什么我们认为初创公司还有很长的路要走。他们可以许可 [来自其他地方的 ISP 块],但就内存访问和其他一切而言,它并没有真正与系统的其余部分集成。”
内存系统是公司的关键IP之一。
“我们有一个内存控制器,我们协调整个过程,以便我们在片上获取数据。我们尽量不制作任何副本,”Gigot 说。 “我们移动指针,我们不移动数据。只有从头开始设计整个架构,并确切知道芯片将要做什么,这才有可能。”
加速器引擎
AI 加速器是一种矢量处理器,可以加速卷积和其他常见的 AI 功能,或用于经典的计算机视觉工作负载。用户还可以选择运行部分神经网络(例如单次检测器网络中的排序算法)或通过片上双核 Arm Cortex-A76 CPU。
软件堆栈允许应用程序利用系数稀疏性,这是一种将值接近零的网络系数向下舍入为零的技术。该方法可以从算法中“修剪”整个计算“分支”,从而大大降低计算需求。
稀疏化“对我们来说是一种非常有效的技术,因为当系数为零时,在我们的架构中我们不进行操作,我们有一个跳过 [函数],”他说。 “所以我们不计算该系数的结果。我们几乎需要零周期。”
Gigot 说,该过程通常会将 50% 到 80% 的系数确定为稀疏化目标。稀疏化后通常需要进行一些小的再训练,以重新获得过程中丢失的预测精度。根据 Gigot 的说法,重新训练通常可以将准确率降低到原始模型的 1% 以内——对于大多数客户来说这是一个可以接受的折衷,尤其是在模型尺寸减少 5 倍的情况下。 Ambarella 还致力于开发更具有架构意识的稀疏化和量化工具。
点击查看全尺寸图片
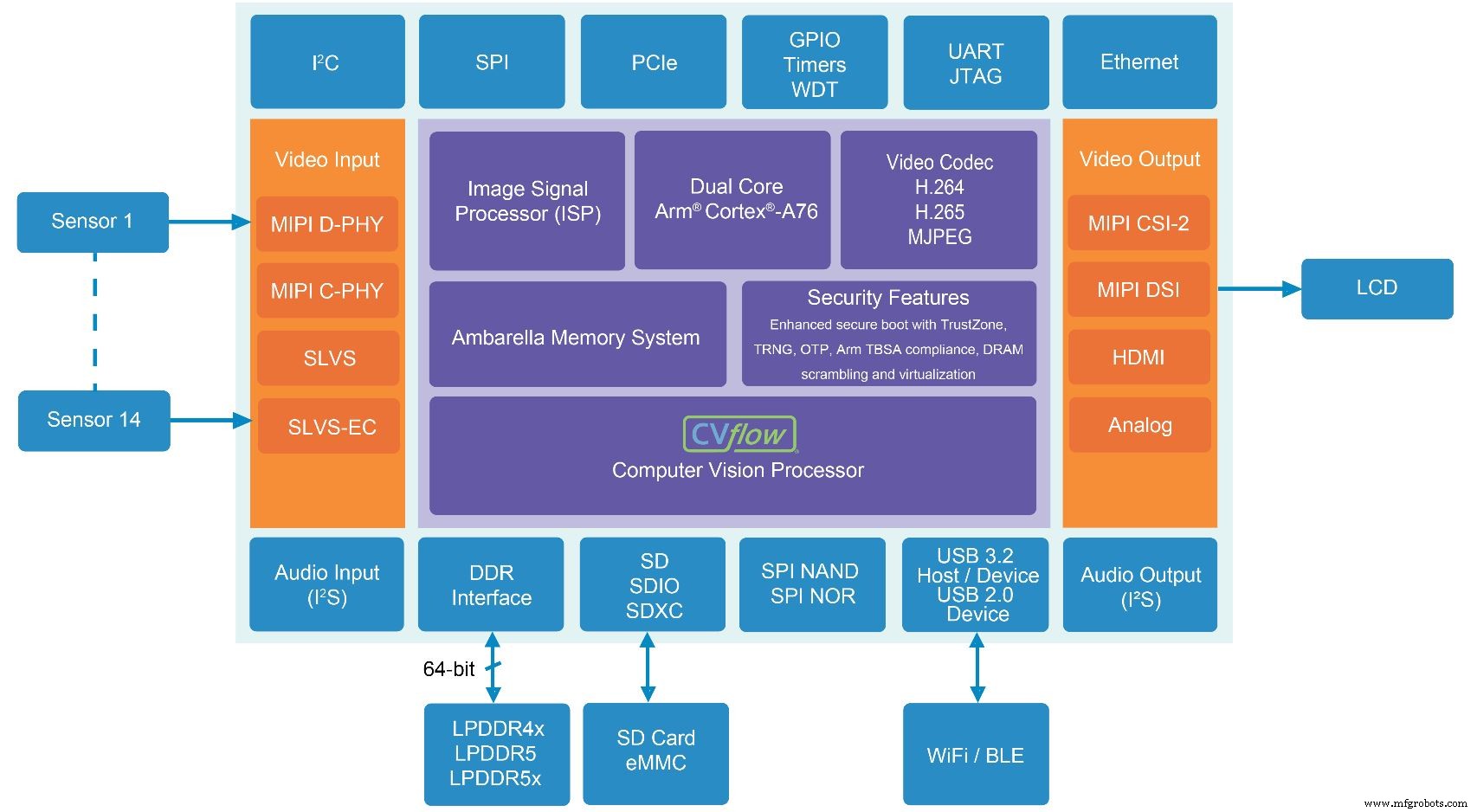
用于多传感器相机系统的 CV5S SoC 包括最新一代 Ambarella 的 CVflow AI 和计算机视觉加速器(来源:Ambarella)
能够接受多达 14 个视频流,然后同时对这些流执行 AI,客户是否会同时运行多个神经网络?是否需要某种多路复用方案?

Jerome Gigot(来源:Ambarella)
Gigot回答说是的。 “CVflow 是一个非常快的矢量引擎,一个非常快的卷积引擎。一切都是时分复用的。我们在硬件中有不同的路径,因此我们可以并行化操作,但我们不会将其绑定到特定网络 [这] 与 GPU 上的批处理完全不同。”
批处理是大型 GPU 经常采用的一种技术,它将图像分组并发送它们以进行并行处理。 GPU 已经加载了其他参数。这种方法不必在操作之间切换,从而降低了计算成本。
对于像 CVflow 这样的小型引擎,更大的神经网络必须分解成块进行处理,因为芯片的内存不能一次存储所有参数。连续的块可能来自同一个神经网络,或另一个网络,或另一个通道输入。 Gigot 说,CVflow 上的典型硬件利用率在 70% 到 80% 之间,并补充说切换网络/频道不会影响效率。
CV5S 和 CV52S 预计将于 2021 年 10 月开始出样。
>> 本文最初发表在我们的姊妹网站 EE次。
相关内容:
- AI 视觉处理器可在 2W 下以 30fps 的速度播放 8K 视频
- Ambarella 使用新型相机 SoC 实现智能边缘感应
- FPGA 取代了 Subaru Eyesight 基于视觉的 ADAS 中的 ASIC
- Arm 增加了 CPU、GPU 和 ISP 以实现自主和视觉安全
- 低功耗 AI 视觉板使用单节电池可持续使用“数年”
有关 Embedded 的更多信息,请订阅 Embedded 的每周电子邮件通讯。
嵌入式