

Python 正则表达式:re.match()、re.search()、re.findall() 和示例
什么是 Python 中的正则表达式?
A 正则表达式 (RE) 在编程语言中是用于描述搜索模式的特殊文本字符串。它对于从代码、文件、日志、电子表格甚至文档等文本中提取信息非常有用。
在使用 Python 正则表达式时,首先要认识到一切本质上都是一个字符,我们正在编写模式来匹配特定的字符序列,也称为字符串。 Ascii 或拉丁字母是键盘上的字母,Unicode 用于匹配外来文本。它包括数字和标点符号以及 $#@!% 等所有特殊字符。
在这个 Python RegEx 教程中,我们将学习-
- 正则表达式语法
- w+ 和 ^ 表达式示例
- re.split 函数中的\s 表达式示例
- 使用正则表达式方法
- 使用 re.match()
- 在文本中查找模式 (re.search())
- 对文本使用 re.findall
- Python 标志
- re.M 或多行标志示例
例如,Python 正则表达式可以告诉程序从字符串中搜索特定文本,然后相应地打印出结果。表达式可以包含
- 文本匹配
- 重复
- 分支
- 图案组合等
Python中的正则表达式或RegEx表示为RE(REs,regexes或regex pattern)通过re模块导入 . Python 通过库支持正则表达式。 Python 中的 RegEx 支持各种内容,例如 修饰符、标识符和空白字符 .
| 标识符 | 修饰符 | 空白字符 | 需要转义 |
|---|---|---|---|
| \d=任意数字(一个数字) | \d 代表一个数字。例如:\d{1,5} 它将声明 1,5 之间的数字,例如 424,444,545 等。 | \n =换行 | 。 + * ? [] $ ^ () {} | \ |
| \D=不是数字(非数字) | + =匹配 1 个或多个 | \s=空格 | |
| \s =空格 (制表符、空格、换行符等) | ? =匹配 0 或 1 | \t =标签 | |
| \S=除了空格 | * =0 或更多 | \e =转义 | |
| \w =字母(匹配字母数字字符,包括“_”) | $ 匹配字符串的结尾 | \r =回车 | |
| \W =除字母以外的任何字符(匹配不包括“_”的非字母数字字符) | ^ 匹配字符串的开头 | \f=换页 | |
| 。 =除了字母(句号)之外的任何内容 | |匹配或 x/y | —————— | |
| \b =除换行符以外的任何字符 | [] =范围或“方差” | ————- | |
| \. | {x} =前面代码的数量 | —————— |
正则表达式(RE)语法
import re
- Python 中包含的“re”模块主要用于字符串搜索和操作
- 也经常用于网页“抓取”(从网站中提取大量数据)
我们将从这个简单的练习开始表达式教程,使用表达式 (w+) 和 (^)。
w+ 和 ^ 表达式示例
- “^”: 此表达式匹配字符串的开头
- “w+ “:此表达式匹配字符串中的字母数字字符
在这里,我们将看到一个 Python RegEx 示例,说明如何在代码中使用 w+ 和 ^ 表达式。我们将在 Python 中介绍函数 re.findall(),在本教程的后面部分,但有一段时间我们只关注 \w+ 和 \^ 表达式。
例如,对于我们的字符串“guru99,education is fun”,如果我们使用 w+ 和 ^ 执行代码,它将给出输出“guru99”。
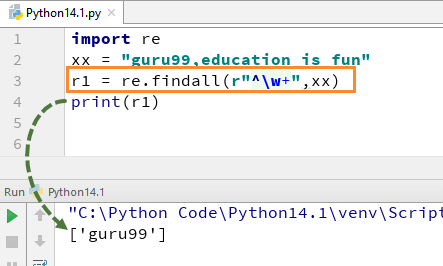
import re xx = "guru99,education is fun" r1 = re.findall(r"^\w+",xx) print(r1)
请记住,如果从 w+ 中删除 +sign,则输出会发生变化,并且只会给出第一个字母的第一个字符,即 [g]
re.split 函数中的\s表达式示例
- “s”:该表达式用于在字符串中创建空格
为了理解 Python 中的这个 RegEx 是如何工作的,我们从一个简单的 Python RegEx 示例开始。在示例中,我们使用“re.split”函数拆分每个单词,同时我们使用表达式 \s 允许单独解析字符串中的每个单词。
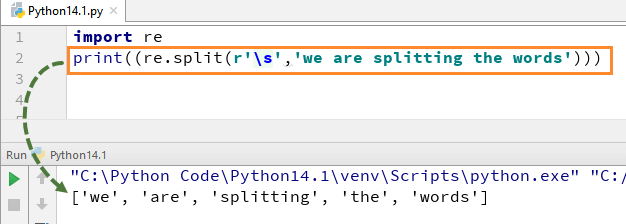
当你执行这段代码时,它会给你输出 ['we', 'are', 'splitting', 'the', 'words']。
现在,让我们看看如果从 s 中删除“\”会发生什么。输出中没有 's' 字母表,这是因为我们已经从字符串中删除了 '\',并且它将“s”评估为常规字符,从而在字符串中找到“s”的任何位置拆分单词。
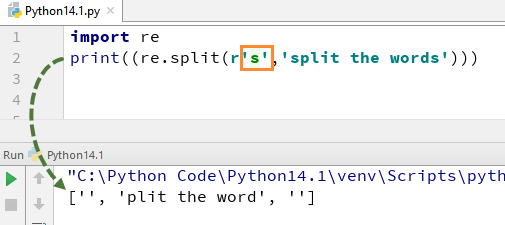
同样,还有一系列其他的 Python 正则表达式,您可以在 Python 中以各种方式使用,如 \d、\D、$、\.、\b 等。
这是完整的代码
import re xx = "guru99,education is fun" r1 = re.findall(r"^\w+", xx) print((re.split(r'\s','we are splitting the words'))) print((re.split(r's','split the words')))
接下来,我们将看看Python中正则表达式使用的方法类型。
使用正则表达式方法
“re”包提供了几种方法来实际对输入字符串执行查询。我们将在 Python 中看到 re 的方法:
- re.match()
- re.search()
- re.findall()
注意 :基于正则表达式,Python 提供了两种不同的原始操作。 match 方法只检查字符串开头是否匹配,而 search 方法检查字符串中任何位置是否匹配。
re.match()
re.match() Python 中的 re 函数将搜索正则表达式模式并返回第一个匹配项。 Python RegEx Match 方法仅在字符串的开头检查匹配项。因此,如果在第一行找到匹配项,则返回匹配对象。但如果在其他行中找到匹配项,Python RegEx Match 函数将返回 null。
例如,考虑以下 Python re.match() 函数的代码。表达式“w+”和“\W”将匹配以字母“g”开头的单词,此后,不识别任何不以“g”开头的单词。为了检查列表或字符串中每个元素的匹配,我们在这个 Python re.match() 示例中运行 forloop。
re.search():在文本中寻找模式
re.search() 函数将搜索正则表达式模式并返回第一个匹配项。与 Python re.match() 不同,它将检查输入字符串的所有行。 Python re.search() 函数在找到模式时返回一个匹配对象,如果没有找到则返回“null”
如何使用search()?
要使用 search() 函数,需要先导入 Python re 模块,然后执行代码。 Python re.search() 函数从我们的主字符串中获取“模式”和“文本”进行扫描
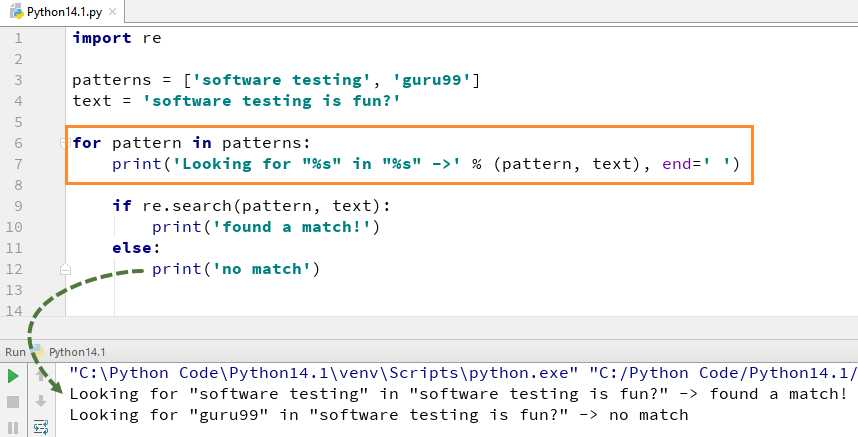
例如,我们在文本字符串“Software Testing is fun”中查找两个文字字符串“Software testing”“guru99”。对于“软件测试”,我们找到了匹配项,因此它返回 Python re.search() 示例的输出为“找到匹配项”,而对于单词“guru99”,我们在字符串中找不到,因此它返回输出为“不匹配” ”。
re.findall()
findall() 模块用于搜索与给定模式匹配的“所有”事件。相反,search() 模块只会返回与指定模式匹配的第一个匹配项。 findall() 将遍历文件的所有行,并在一个步骤中返回所有不重叠的模式匹配。
如何在 Python 中使用 re.findall()?
这里我们有一个电子邮件地址列表,我们希望从列表中取出所有电子邮件地址,我们使用 Python 中的 re.findall() 方法。它会从列表中找到所有的电子邮件地址。
这是re.findall()示例的完整代码
import re
list = ["guru99 get", "guru99 give", "guru Selenium"]
for element in list:
z = re.match("(g\w+)\W(g\w+)", element)
if z:
print((z.groups()))
patterns = ['software testing', 'guru99']
text = 'software testing is fun?'
for pattern in patterns:
print('Looking for "%s" in "%s" ->' % (pattern, text), end=' ')
if re.search(pattern, text):
print('found a match!')
else:
print('no match')
abc = 'guru99@google.com, careerguru99@hotmail.com, users@yahoomail.com'
emails = re.findall(r'[\w\.-]+@[\w\.-]+', abc)
for email in emails:
print(email) Python 标志
许多 Python 正则表达式方法和正则表达式函数采用称为标志的可选参数。此标志可以修改给定 Python 正则表达式模式的含义。为了理解这些,我们将看到这些标志的一两个示例。
Python中使用的各种标志包括
| 正则表达式标志的语法 | 这个标志有什么作用 |
|---|---|
| [re.M] | 开始/结束考虑每一行 |
| [re.I] | 忽略大小写 |
| [re.S] | 制作 [ . ] |
| [re.U] | 使 { \w,\W,\b,\B} 遵循 Unicode 规则 |
| [re.L] | 使 {\w,\W,\b,\B} 遵循语言环境 |
| [re.X] | 允许正则表达式中的注释 |
re.M 或多行标志示例
在多行中,模式字符 [^] 匹配字符串的第一个字符和每行的开头(紧跟在每个换行符之后)。而表达式小“w”用于用字符标记空间。当你运行代码时,第一个变量“k1”只打印出 guru99 字的字符“g”,而当你添加多行标志时,它会取出字符串中所有元素的第一个字符。
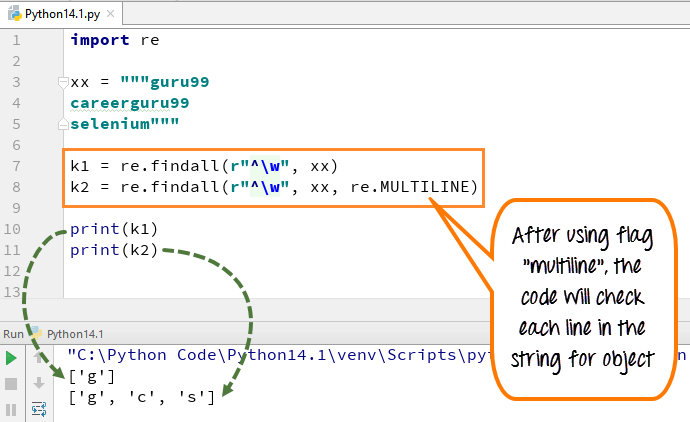
这是代码
import re xx = """guru99 careerguru99 selenium""" k1 = re.findall(r"^\w", xx) k2 = re.findall(r"^\w", xx, re.MULTILINE) print(k1) print(k2)
- 我们为字符串“guru99…”声明了变量 xx。 Careerguru99….selenium”
- 在不使用多行标志的情况下运行代码,它只给出行中的“g”输出
- 运行带有“multiline”标志的代码,当您打印“k2”时,它会输出“g”、“c”和“s”
- 因此,我们可以在上面的示例中看到添加多行前后的区别。
同样,您也可以使用其他 Python 标志,如 re.U(Unicode)、re.L(遵循语言环境)、re.X(允许评论)等。
Python 2 示例
以上代码是 Python 3 示例,如果您想在 Python 2 中运行,请考虑以下代码。
# Example of w+ and ^ Expression
import re
xx = "guru99,education is fun"
r1 = re.findall(r"^\w+",xx)
print r1
# Example of \s expression in re.split function
import re
xx = "guru99,education is fun"
r1 = re.findall(r"^\w+", xx)
print (re.split(r'\s','we are splitting the words'))
print (re.split(r's','split the words'))
# Using re.findall for text
import re
list = ["guru99 get", "guru99 give", "guru Selenium"]
for element in list:
z = re.match("(g\w+)\W(g\w+)", element)
if z:
print(z.groups())
patterns = ['software testing', 'guru99']
text = 'software testing is fun?'
for pattern in patterns:
print 'Looking for "%s" in "%s" ->' % (pattern, text),
if re.search(pattern, text):
print 'found a match!'
else:
print 'no match'
abc = 'guru99@google.com, careerguru99@hotmail.com, users@yahoomail.com'
emails = re.findall(r'[\w\.-]+@[\w\.-]+', abc)
for email in emails:
print email
# Example of re.M or Multiline Flags
import re
xx = """guru99
careerguru99
selenium"""
k1 = re.findall(r"^\w", xx)
k2 = re.findall(r"^\w", xx, re.MULTILINE)
print k1
print k2
总结
编程语言中的正则表达式是用于描述搜索模式的特殊文本字符串。它包括数字和标点符号以及 $#@!% 等所有特殊字符。表达式可以包括文字
- 文本匹配
- 重复
- 分支
- 图案组合等
在 Python 中,正则表达式表示为 RE(REs、regexes 或 regex pattern),通过 Python re 模块嵌入。
- Python 中包含的“re”模块主要用于字符串搜索和操作
- 也经常用于网页“抓取”(从网站中提取大量数据)
- 正则表达式方法包括 re.match(),re.search()&re.findall()
- 其他 Python RegEx 替换方法是 sub() 和 subn(),用于替换 re 中匹配的字符串
- Python 标志 许多 Python 正则表达式方法和正则表达式函数采用一个名为 Flags 的可选参数
- 此标志可以修改给定正则表达式模式的含义
- Regex 方法中使用的各种 Python 标志是 re.M、re.I、re.S 等。
Python