

深入了解数据科学生命周期
自从大数据出现以来,现代计算机科学已经达到了新的能力和处理能力的基准。如今,产生 100 TB 或更多数据集的应用程序并不少见,这被认为是大数据。
手头有如此大量的信息,很容易变得杂乱无章并浪费时间在无用的内容上。这就是为什么遵循一种可以提高大数据项目的功效和效率的方法非常重要的两个原因。

图 1. 现代数据科学处理非常大的数据集,也称为大数据。
数据科学生命周期提供了一个框架,帮助定义、收集、组织、评估和部署大数据项目。它是一个迭代过程,由一系列按逻辑顺序排列的步骤组成,便于反馈和旋转。
生命周期序列是什么样的?答案是,没有一个每个人都遵循的通用模型。许多承担大数据项目的公司将数据科学生命周期调整到其业务流程中,通常包括更多步骤。尽管如此,所有许多模型和流程都有共同点。本文将使用 CRISP-DM 过程模型,它是第一个也是最流行的数据科学生命周期模型之一。
CRISP-DM 模型
CRISP-DM 代表数据挖掘的跨行业标准流程。它于 1999 年由 ESPRIT 首次发布,ESPRIT 是一个欧洲促进信息技术 (IT) 研究的计划。 CRISP-DM 模型由指导大数据项目的六个步骤或阶段组成。它鼓励利益相关者通过提出和回答有关问题的重要问题来思考业务。
让我们详细回顾一下CRISP-DM模型的六个阶段。
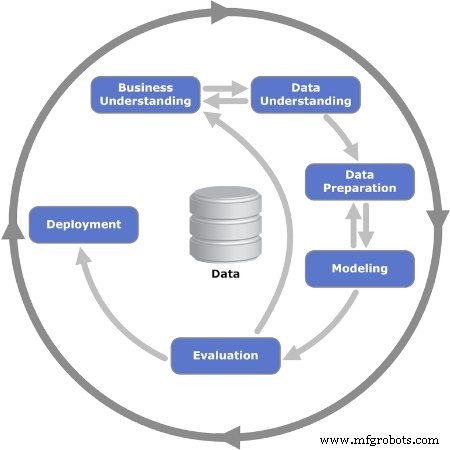
图2。 显示了 CRISP-DM 模型的六个迭代阶段。图片由提供 肯尼斯·詹森
第一阶段:业务理解
第一阶段包括定义问题和建立目标的几个任务。这是项目目标的设定重点是业务——或者换句话说,客户。通常,组成大数据项目的团队必须向客户交付解决方案,客户可以是公司内的另一个区域或部门。
一旦确定了业务需求或问题,下一步就是定义成功标准。这些可以是关键绩效指标 (KPI) 或服务水平协议 (SLA),它们提供了评估进度和完成情况的客观手段。
接下来,需要分析业务情况以识别风险、回滚计划、应急措施,以及更重要的是资源可用性。制定项目计划,包括里程碑资源。
阶段 2:数据理解
一旦在前一阶段建立了基本面,就该关注数据了。这个阶段首先定义哪些数据被认为是必要的,然后记录一些关于它的细节:在哪里可以找到它、数据类型、格式、不同数据字段之间的关系等。
准备好第一个文档后,下一步是执行第一次数据收集运行。这提供了结构如何形成的有用快照。然后评估此信息快照的质量。
阶段 3:数据准备
第三阶段加强前一阶段并准备数据集以进行建模。第一个集合中的数据字段被进一步整理,任何被认为不必要的信息都从集合中删除:这称为清理数据。
此外,可能需要从其他可用信息中获取特定信息;其他时候,它必须结合起来。换句话说,需要对数据进行处理以生成最终格式。
阶段 4:建模
此阶段最重要的任务是选择一种算法来处理收集到的数据。在这种情况下,算法是在专为大数据项目设计的计算机软件中编程的一组序列步骤和规则。
可以使用许多算法:线性回归、决策树和支持向量机是一些示例。选择正确的算法来解决问题需要经验丰富的数据科学家具备的技能。
图 3。 线性回归是一种用于大数据建模的算法。
下一步是将算法编码到软件应用程序中。这也是计划测试阶段的时间,其中包括为测试和验证分配特定数据集。
阶段 5:评估
有时,从一开始就很难选择算法。发生这种情况时,科学家会执行多种算法并分析结果以做出最终决定。测试阶段完成后,将对结果的完整性和准确性进行审查。
更重要的是,这是一个评估结果是否导致解决方案的机会。在迭代模型中,这是一个关键的交叉点,可以启动主要的迭代序列,或者可以做出走向最后阶段的决定。
阶段 6:部署
这是项目从测试环境转移到实时生产环境的时候。规划部署时间表和策略对于降低风险和潜在的系统停机时间非常重要。
尽管模型图表明项目到此结束,但之后仍有许多步骤需要跟进:监控和维护。监控是上线后立即进行的密切观察,也称为超级护理。维护是维护和升级已实施解决方案的半永久性过程。
之所以这么称呼大数据是有原因的:有大量的数据需要解析。实施其中一种数据科学生命周期模型有助于决定哪些信息值得保留并用于预测性维护等流程。
物联网技术