

应对物联网数据的 ETL 挑战并最大限度地提高投资回报率

通过开发 ETL(提取、传输、加载)技术方面的专业知识,组织可以优化 IoT 数据,快速且经济高效地获得其业务价值。
物联网的潜力从未如此巨大。预计到 2021 年,对支持物联网的设备的投资将翻一番,并且数据和分析领域的机会激增,主要任务是克服挑战并控制周围的成本物联网数据项目。
通过开发 ETL(提取、传输、加载)技术(如流处理和数据湖)方面的专业知识,组织可以优化物联网数据,快速且经济高效地获得其业务价值。
另见: 启用原始数据湖的 4 条原则
然而,在许多组织中,这可能会导致 IT 瓶颈、长期项目延迟和数据科学被推迟。结果:物联网项目——其中预测分析数据在提高运营效率和刺激创新方面发挥关键作用——仍然 没有超过概念验证的门槛,绝对不能证明投资回报率。
了解物联网面临的 ETL 挑战
下图将帮助您更好地理解问题:
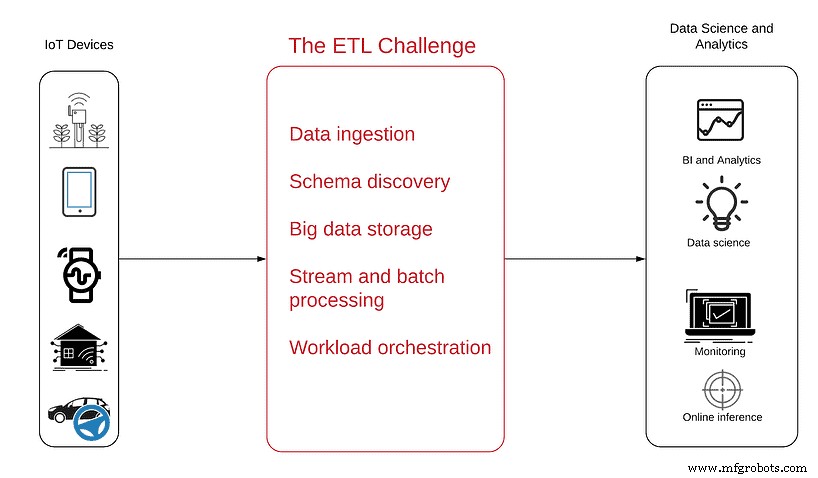
数据源在左侧 - 无数的传感器填充设备,从简单的天线到复杂的自动驾驶汽车,它们生成物联网数据并将其作为不间断的半结构化数据流通过网络发送。
右边是使用上述数据应该达到的目标,以及项目结束时产生的分析产品,包括:
- 商业智能 了解产品使用趋势和模式
- 运营监控 实时查看中断和非活动设备
- 异常检测 在数据高峰或急剧下降时获得主动警报
- 嵌入式分析 让客户能够查看和了解自己的使用数据
- 数据科学 在预测性维护、路线优化或人工智能开发中享受高级分析和机器学习带来的好处
要实现这些目标,您需要首先将数据从其原始流模式转换为可使用 SQL 和其他分析工具查询的分析就绪表。
ETL 过程通常是任何分析项目中最难理解的部分,因为物联网数据包含一组独特的品质,这些品质并不总是与通常的关系数据库、ETL 和 BI 工具同步。例如:
- IoT 数据是流数据, 在小文件中不断生成,这些文件累积起来成为海量、蔓延的数据集。这些与传统的表格数据非常不同,需要更复杂的 ETL 来执行连接、聚合和数据丰富。
- 现在必须存储 IoT 数据,以后再进行分析。 与典型的数据集不同,物联网设备创建的数据量巨大,这意味着它必须有一个可以分析的地方——云或本地数据湖。
- 物联网数据由于多个设备而呈现无序事件 可能会进出 Internet 连接区域。这意味着日志可能会在不同的时间到达服务器,而且并不总是以“正确”的顺序。
- 物联网数据通常需要低延迟访问。 在操作上,您可能必须实时或近乎实时地识别异常或特定设备,因此您无法承受批处理造成的延迟。
您应该使用开源框架来创建数据湖吗?
为了构建用于数据分析的企业数据平台,许多组织使用这种通用方法:使用开源流处理框架作为构建块以及 Apache Spark/Hadoop、Apache Flink、InfluxDB 等时间序列数据库来创建数据湖。
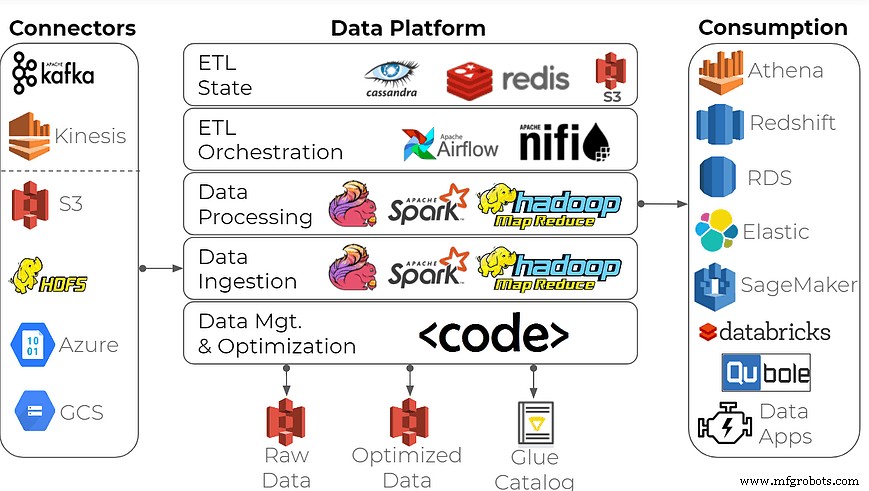
这个工具集可以完成这项工作吗?当然,除了最有数据经验的公司之外,正确地执行它可能会让所有人不知所措。构建这样一个数据平台需要大数据工程师的专业技能和对数据基础设施的高度关注——在与物联网数据密切合作的制造业和消费电子行业,这通常不是一个强项。预计交货延迟、成本高昂以及大量浪费的工程时间。
如果您的组织想要高性能以及全方位的功能和用例——操作报告、临时分析和机器学习的数据准备——那么采用合适的解决方案。一个示例是使用专门构建的数据湖 ETL 平台将流转换为可用于分析的数据集。
该解决方案不像 Spark/Hadoop 数据平台那样死板和复杂。它是使用自助服务用户界面和 SQL 构建的,而不是 Java/Scala 中的密集编码。对于 DevOps 和数据工程领域的分析师、数据科学家、产品经理和数据提供者来说,它可以是一个真正用户友好的工具:
- 为数据消费者提供自助服务,无需依赖 IT 和数据工程
- 优化 ETL 流程和大数据存储以降低基础架构成本
- 借助完全托管的服务,组织可以专注于功能而不是基础架构
- 无需为实时数据、临时分析和报告维护多个系统
- 确保数据永远不会离开客户的 AWS 账户以确保整体安全
您可以从物联网数据中受益——它只需要正确的工具才能发挥作用。
物联网技术