

模拟内存计算如何解决边缘 AI 推理的功耗挑战
机器学习和深度学习已经成为我们生活中不可或缺的一部分。通过自然语言处理 (NLP)、图像分类和对象检测的人工智能 (AI) 应用程序深深嵌入我们使用的许多设备中。大多数 AI 应用程序都通过基于云的引擎提供服务,这些引擎非常适合它们的用途,例如在 Gmail 中输入电子邮件回复时进行单词预测。
尽管我们享受这些 AI 应用程序的好处,但这种方法带来了隐私、功耗、延迟和成本方面的挑战。如果有一个本地处理引擎能够在数据本身的源头执行部分或全部计算(推理),这些挑战就可以解决。这在传统的数字神经网络实现中很难做到,其中内存成为耗电瓶颈。该问题可以通过多级内存和模拟内存计算方法来解决,这些方法共同使处理引擎能够满足低得多的毫瓦 (mW) 到微瓦 (uW) 功率要求,以便在网络边缘。
云计算的挑战
当 AI 应用通过基于云的引擎提供服务时,用户必须将一些数据(愿意或不愿意)上传到云,由计算引擎处理数据,提供预测,并将预测下游发送给用户使用。

图 1:从边缘到云的数据传输。 (来源:微芯科技)
与此过程相关的挑战概述如下:
- 隐私和安全问题: 使用始终在线、始终感知的设备,人们担心个人数据(和/或机密信息)在上传期间或在数据中心的保质期内被滥用。
- 不必要的功耗: 如果每个数据位都要去云端,它就会消耗来自硬件、无线电、传输的电力,并且可能会在云端进行不必要的计算。
- 小批量推理的延迟: 如果数据源自边缘,有时可能需要一秒钟或更长时间才能从基于云的系统获得响应。对于人类感官而言,任何超过 100 毫秒 (ms) 的延迟都是显而易见的,并且可能令人讨厌。
- 数据经济需要有意义: 传感器无处不在,而且非常实惠;但是,它们会产生大量数据。将每一点数据都上传到云端并进行处理是不经济的。
为了使用本地处理引擎解决这些挑战,执行推理操作的神经网络模型必须首先针对所需用例使用给定的数据集进行训练。通常,这需要大量计算(和内存)资源和浮点算术运算。因此,机器学习解决方案的训练部分仍然需要在公共或私有云(或本地 GPU、CPU、FPGA 场)上使用数据集来生成最佳神经网络模型。一旦神经网络模型准备就绪,模型可以进一步针对具有小型计算引擎的本地硬件进行优化,因为神经网络模型不需要反向传播进行推理操作。推理引擎通常需要大量的乘法累加 (MAC) 引擎,然后是激活层,如整流线性单元 (ReLU)、sigmoid 或 tanh,具体取决于神经网络模型的复杂性,以及层与层之间的池化层。
大多数神经网络模型需要大量的 MAC 操作。例如,即使是相对较小的“1.0 MobileNet-224”模型也有 420 万个参数(权重),并且需要 5.69 亿次 MAC 操作来执行推理。由于大多数模型都由 MAC 操作主导,因此这里的重点将放在机器学习计算的这一部分——并探索创建更好解决方案的机会。一个简单的、全连接的两层网络如下图 2 所示。
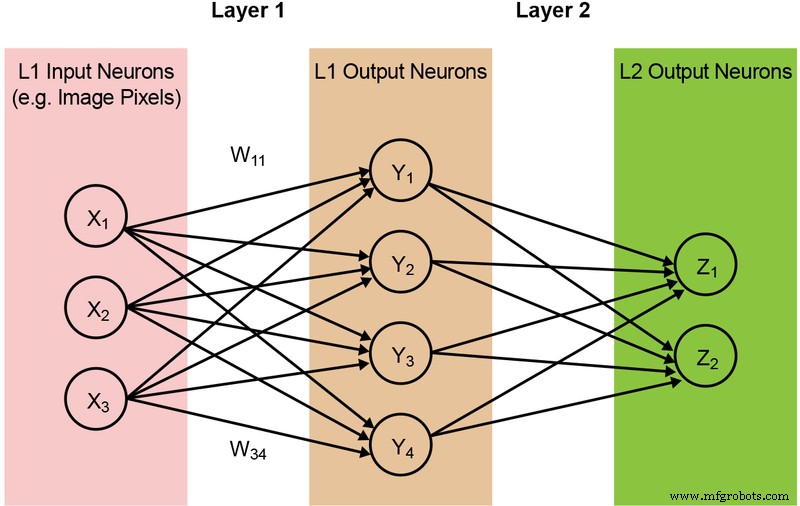
图 2:具有两层的全连接神经网络。 (来源:微芯科技)
输入神经元(数据)使用第一层权重进行处理。然后用第二层权重处理来自第一层的输出神经元并提供预测(假设模型是否能够在给定图像中找到猫脸)。这些神经网络模型使用“点积”来计算每一层中的每个神经元,如下面的等式所示(为了简化,省略了等式中的“偏差”项):
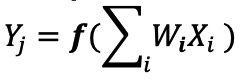
内存 数字计算的瓶颈
在数字神经网络实现中,权重和输入数据存储在 DRAM/SRAM 中。权重和输入数据需要移动到 MAC 引擎进行推理。根据下面的图 3,这种方法导致大部分功率消耗在将模型参数和输入数据提取到实际 MAC 操作发生的 ALU 中。
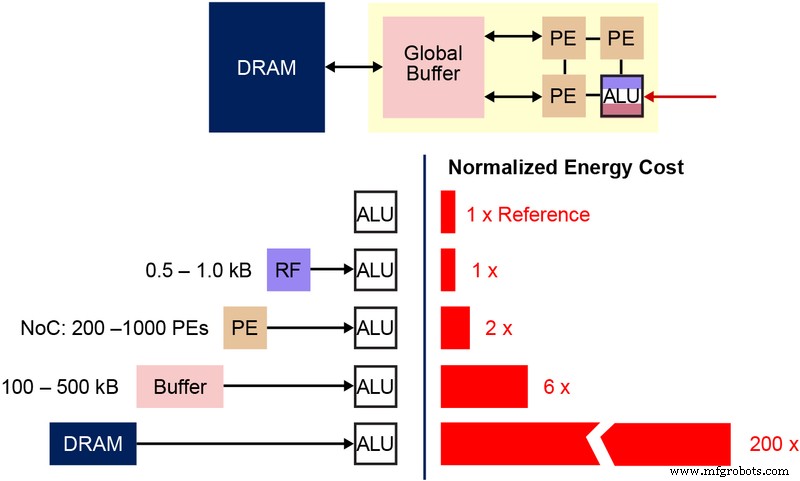
图 3:机器学习计算中的内存瓶颈。 (来源:Y.-H. Chen、J. Emer 和 V. Sze,“Eyeriss:卷积神经网络节能数据流的空间架构”,ISCA,2016 年。)
从能量的角度来看——使用数字逻辑门的典型 MAC 操作消耗约 250 飞焦(fJ,或 10 −15 焦耳)的能量,但在数据传输过程中消耗的能量比计算本身高两个数量级以上,并且在 50 皮焦耳(pJ,或 10 −12 焦耳)到 100pJ。公平地说,有许多设计技术可以最大限度地减少从内存到 ALU 的数据传输;然而,整个数字方案仍然受到冯诺依曼架构的限制——因此这为减少浪费的电力提供了很大的机会。如果执行 MAC 操作的能量可以从 ~100pJ 减少到 pJ 的一小部分会怎样?
通过模拟内存计算消除内存瓶颈
当内存本身可用于降低计算所需的功率时,在边缘执行推理操作就变得节能了。内存计算方法的使用最大限度地减少了必须移动的数据量。这反过来又消除了数据传输过程中浪费的能量。使用可在超低有效功耗下工作且在待机模式下几乎没有能量耗散的闪存单元,进一步减少了能量耗散。
这种方法的一个例子是来自 Microchip Technology 公司 Silicon Storage Technology (SST) 的 memBrain™ 技术。基于 SST 的 SuperFlash ® 内存技术,该解决方案包括一个内存计算架构,可以在推理模型的权重存储的地方进行计算。这消除了 MAC 计算中的内存瓶颈,因为权重没有数据移动——只有输入数据需要从输入传感器(如相机或麦克风)移动到内存阵列。
此存储器概念基于两个基本原理:(a) 晶体管的模拟电流响应基于其阈值电压 (Vt) 和输入数据,以及 (b) 基尔霍夫电流定律,该定律指出在一个点相遇的导体网络为零。
了解在这种多级存储器架构中使用的基本非易失性存储器 (NVM) 位单元也很重要。下图(图 4)是两个 ESF3(Embedded SuperFlash 3 rd 一代)位单元,具有共享的擦除门 (EG) 和源线 (SL)。每个位单元有五个端子:控制门 (CG)、工作线 (WL)、擦除门 (EG)、源线 (SL) 和位线 (BL)。对位单元的擦除操作是通过在 EG 上施加高电压来完成的。编程操作是通过在 WL、CG、BL 和 SL 上施加高/低电压偏置信号来完成的。读操作是通过在 WL、CG、BL 和 SL 上施加低压偏置信号来完成的。
图 4:SuperFlash ESF3 单元。 (来源:微芯科技)
使用这种存储器架构,用户可以通过细粒度编程操作在各种 Vt 级别对存储器位单元进行编程。存储技术利用智能算法来调整存储单元的浮栅 (FG) Vt,以实现对输入电压的特定电流响应。根据最终应用的要求,可以在线性或亚阈值工作区对单元进行编程。
图 5 说明了在存储单元上存储和读取多个级别的能力。假设我们试图在内存单元中存储一个 2 位整数值。对于这种情况,我们需要使用 2 位整数值(00、01、10、11)的四个可能值之一对存储器阵列中的每个单元进行编程。下面的四条曲线是四种可能状态中每一种的 IV 曲线,电池的电流响应将取决于施加在 CG 上的电压。
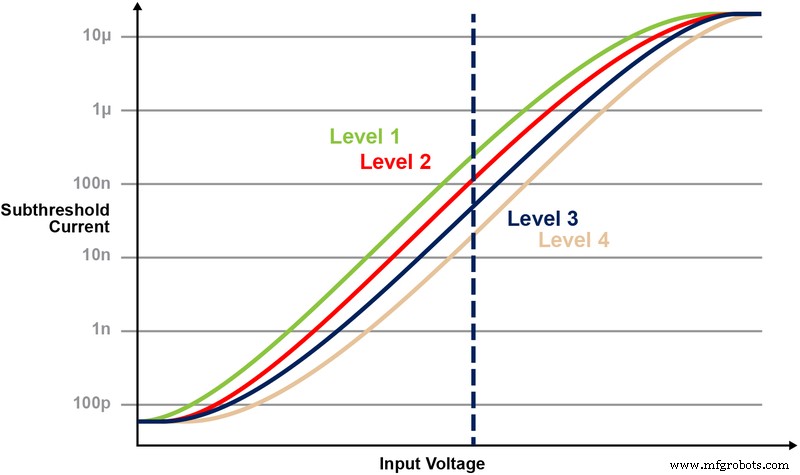
图 5:在 ESF3 单元中编程 Vt 电平。 (来源:微芯科技)
具有内存计算的乘法累加运算
每个 ESF3 电池都可以建模为可变电导 (gm)。 ESF3 单元的电导取决于编程单元的浮栅 Vt。来自训练模型的权重被编程为存储器单元的浮动栅极Vt,因此,单元的gm代表训练模型的权重。当输入电压 (Vin) 施加到 ESF3 单元上时,输出电流 (Iout) 将通过等式 Iout =gm * Vin 给出,这是输入电压与存储在 ESF3 单元上的权重之间的乘法运算。
下面的图 6 说明了小阵列配置(2×2 阵列)中的乘法累加概念,其中通过添加输出电流(来自连接到同一列的单元(来自乘法操作)(例如 I1 =I11 + I21). 根据应用的不同,激活功能既可以在 ADC 模块内执行,也可以通过存储器模块外的数字实现来完成。
点击查看大图
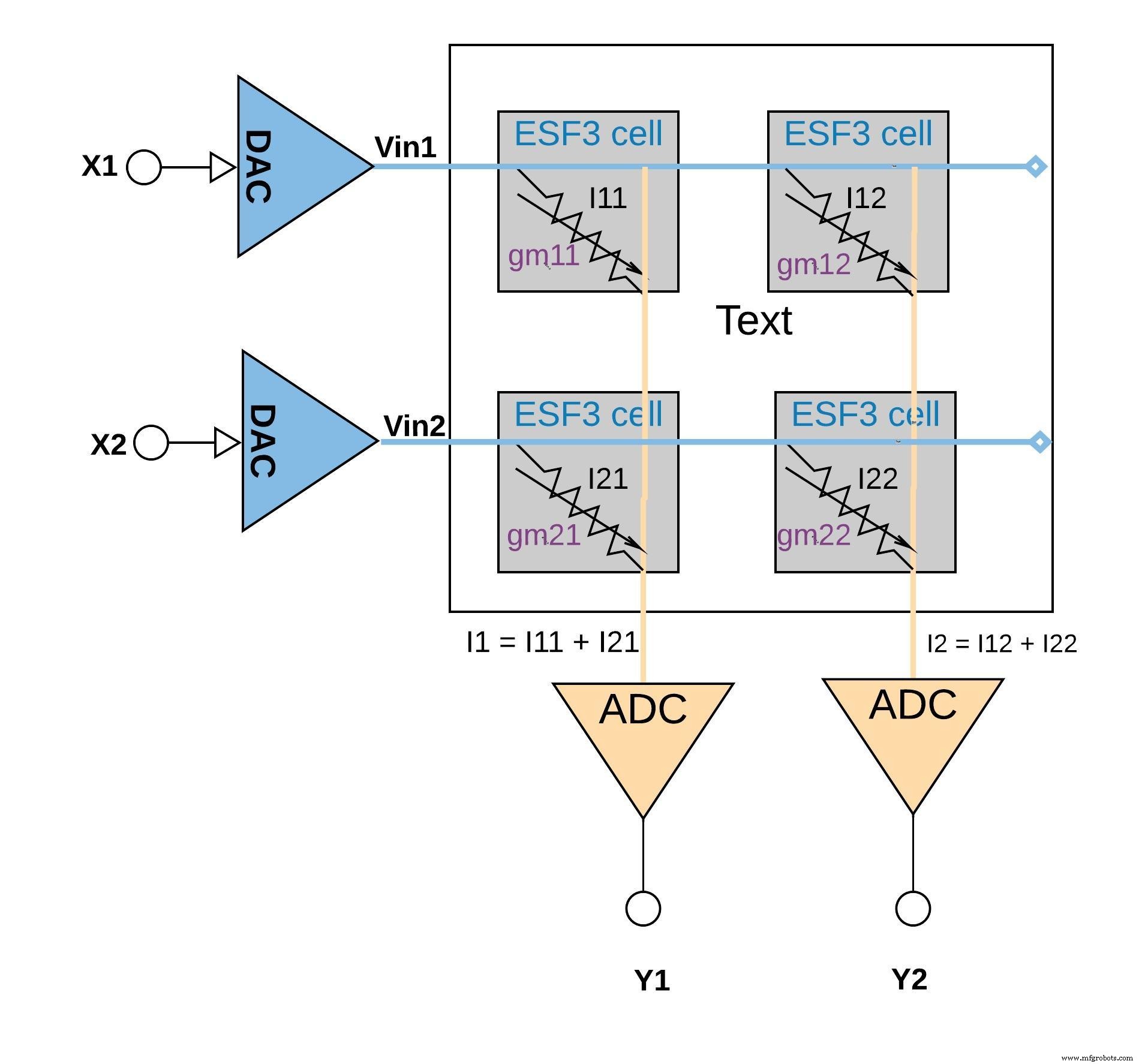
图 6:ESF3 数组 (2×2) 的乘加运算。 (来源:微芯科技)
在更高的层次上进一步说明这个概念;来自训练模型的各个权重被编程为存储单元的浮动门 Vt,因此来自训练模型每一层(假设是全连接层)的所有权重都可以在物理上看起来像权重矩阵的存储器阵列上编程,如图 7 所示。
点击查看大图
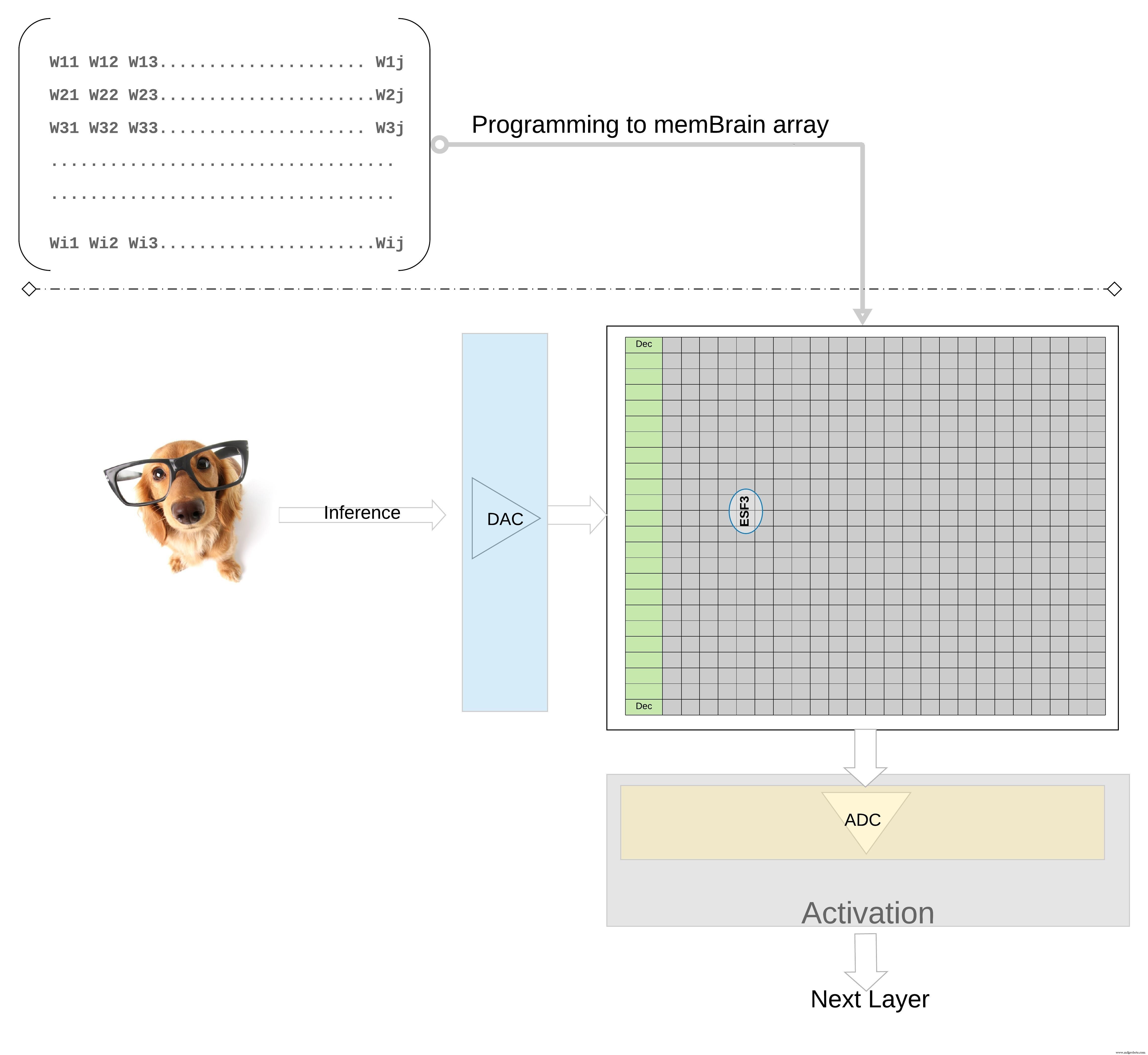
图 7:用于推理的权重矩阵内存阵列。 (来源:微芯科技)
对于推理操作,首先使用数模转换器 (DAC) 将数字输入(例如图像像素)转换为模拟信号并应用于存储器阵列。然后,该阵列对给定的输入向量并行执行数千次 MAC 操作,并产生可以进入各个神经元激活阶段的输出,然后可以使用模数转换器 (ADC) 将其转换回数字信号。然后对数字信号进行池化处理,然后再进入下一层。
这种类型的内存架构非常模块化和灵活。许多 memBrain tile 可以拼接在一起,以构建各种混合权重矩阵和神经元的大型模型,如图 8 所示。在这个例子中,一个 3×4 tile 配置是用模拟和数字结构拼接在一起的。瓦片,数据可以通过共享总线从一个瓦片移动到另一个瓦片。
点击查看大图
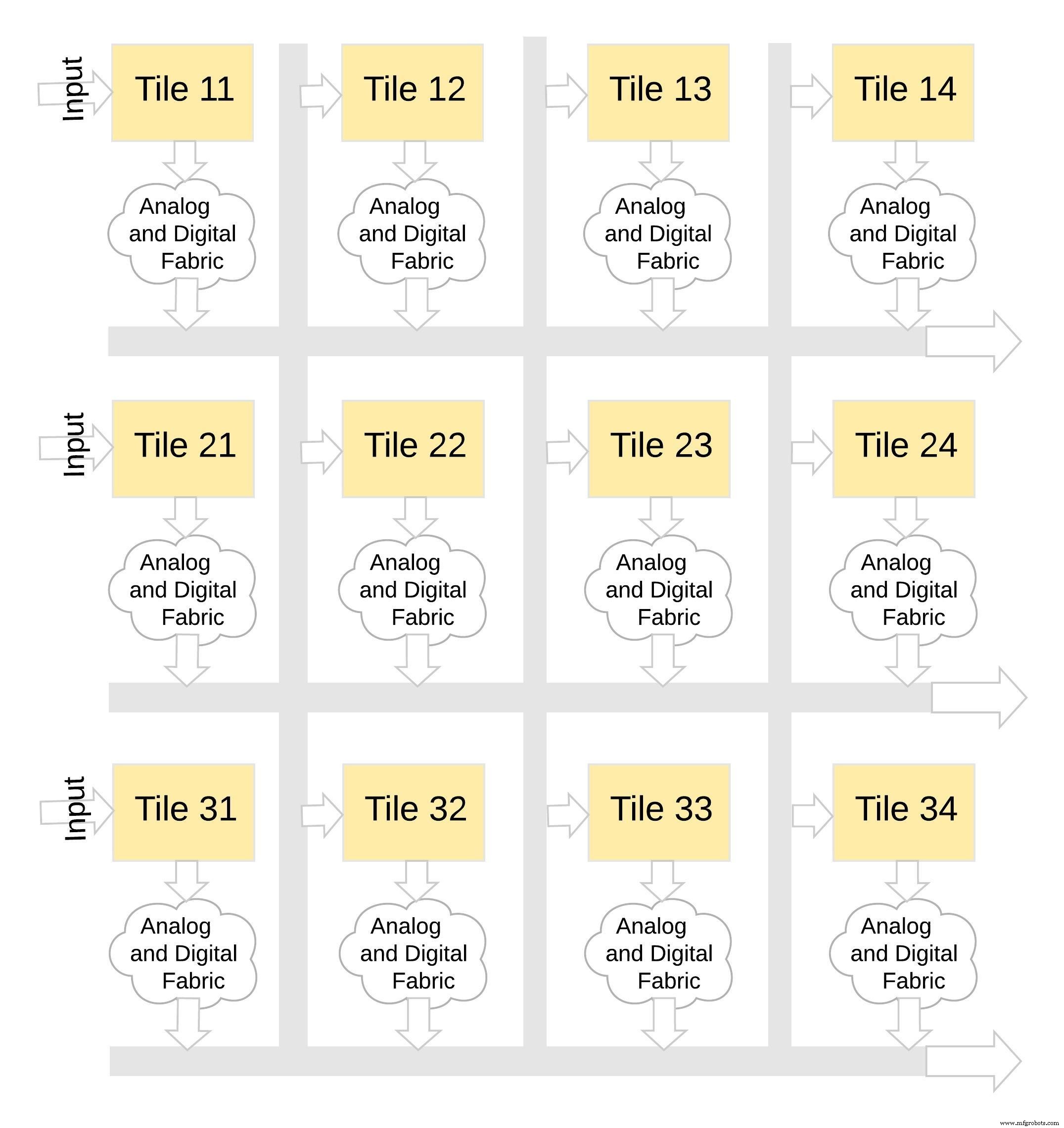
图 8:memBrain™ 是模块化的。 (来源:微芯科技)
到目前为止,我们主要讨论了这种架构的芯片实现。软件开发工具包 (SDK)(图 9)的可用性有助于解决方案的部署。除了芯片之外,SDK 还促进了推理引擎的部署。
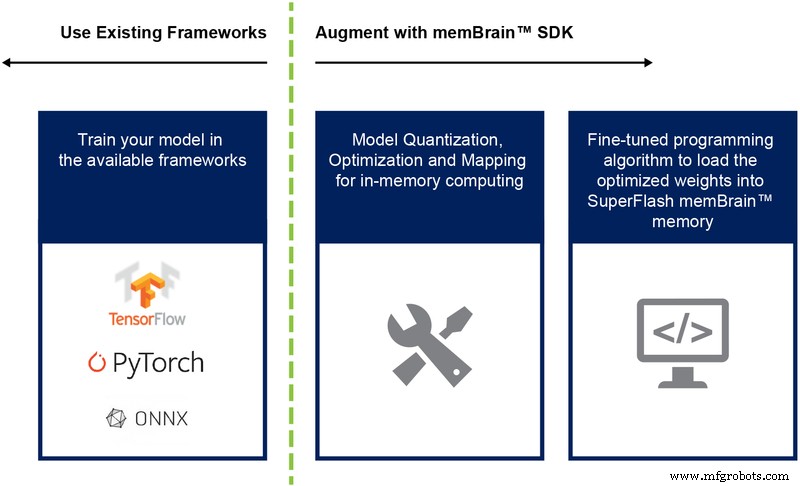
图 9:memBrain™ SDK 流程。 (来源:微芯科技)
SDK 流程与训练框架无关。用户可以在任何可用的框架(如 TensorFlow、PyTorch 或其他)中创建神经网络模型,根据需要使用浮点计算。创建模型后,SDK 会帮助量化经过训练的神经网络模型并将其映射到内存阵列,在内存阵列中,可以使用来自传感器或计算机的输入向量执行向量矩阵乘法。
结论
这种具有内存计算能力的多级内存方法的优势包括:
- 极低功耗: 该技术专为低功耗应用而设计。第一级功率优势来自于解决方案是内存计算这一事实,因此在计算过程中,能量不会浪费在从 SRAM/DRAM 传输的数据和权重上。第二个能量优势源于这样一个事实,即闪存单元以非常低的电流值在亚阈值模式下运行,因此有源功耗非常低。第三个优势是在待机模式下几乎没有能量耗散,因为非易失性存储单元不需要任何电源来为永远在线的设备保存数据。该方法也非常适合利用权重和输入数据的稀疏性。如果输入数据或权重为零,则不会激活内存位单元。
- 降低封装尺寸: 该技术使用分裂栅 (1.5T) 单元架构,而数字实现中的 SRAM 单元基于 6T 架构。此外,与 6T SRAM 单元相比,该单元是一个小得多的位单元。此外,一个单元单元可以存储整个 4 位整数值,这与需要 4*6 =24 个晶体管的 SRAM 单元不同。这提供了显着更小的片上占用空间。
- 降低开发成本: 由于内存性能瓶颈和冯诺依曼架构限制,许多专用设备(如英伟达的 Jetsen 或谷歌的 TPU)倾向于使用更小的几何结构来获得每瓦性能,这是解决边缘 AI 计算挑战的昂贵方法。通过使用模拟内存计算方法的多级内存方法,计算是在闪存单元的片上完成的,因此人们可以使用更大的几何形状并减少掩模成本和交付周期。
边缘计算应用程序显示出巨大的希望。然而,在边缘计算起飞之前,还需要解决功耗和成本方面的挑战。使用在闪存单元中执行片上计算的存储器方法可以消除主要障碍。这种方法利用了经过生产验证、事实上的标准类型的多级内存技术解决方案,该解决方案针对机器学习应用进行了优化。
嵌入式