

混合架构加速人工智能、视觉工作负载
一种新颖的混合数据流和冯诺依曼架构可以加速工作负载,包括神经网络、机器学习、计算机视觉、DSP 和基本线性代数子程序。
硅谷初创公司 Quadric 构建了一个加速器,旨在为机器人、工厂自动化和医学成像等边缘设备加速人工智能和标准计算机视觉算法工作负载。该公司的硬件架构是一种新颖的混合数据流和冯诺依曼设计,可以处理包括神经网络、机器学习、计算机视觉、DSP 和基本线性代数子程序在内的工作负载。
Quadric 的首席执行官 Veerbhan Kheterpal 告诉 EE Times “从一开始,我们就非常清楚人工智能并不是边缘设备上的设备上计算所需的唯一应用程序” . “这些产品的开发人员需要整个系统能够运行经典的高性能计算算法以及人工智能。这确实是完整的系统要求。”
Kheterpal 强调,该架构不是单个工作负载的加速器集合。相反,它是一个具有数据并行指令集的统一架构,旨在加速各种工作负载,包括 AI 推理。
Quadric 的首席产品官 Daniel Firu 说:“最近人工智能正在发展,有一些有趣的趋势是用快速傅立叶变换 (FFT) 替换整个层。” Quadric 将自己定位为加速这些类型的工作负载,引用了谷歌最近的一篇论文,其中研究人员通过用 FFT 替换一些层来加速变压器网络。谷歌用 FFT 替换了变压器编码器的自注意力子层,以生成一个在 BERT 基准上达到 92% 准确率的网络;在 GPU 上训练速度提高了七倍,在 Google TPU 上训练速度提高了两倍。

Quadric 的开发者套件,带有 Q16 处理器和 4 GB 外部存储器的 M.2 卡(来源:Quadric)
葡萄园机器人
Quadric 的三位联合创始人 Veerbhan Kheterpal、Daniel Firu 和 Nigel Drego 之前创立了 21,一家比特币矿业公司,该公司被卖给了 Coinbase。加利福尼亚州伯灵格姆市的 Quadric 并不是从设计芯片开始的。相反,它最初制造了农业机器人,可以在纳帕谷葡萄园走来走去,观察葡萄藤,并在发现灌溉泄漏或害虫时发出警报。

Veerbhan Kheterpal(来源:Quadric)
Kheterpal 说:“当我们建造它时,我们意识到它不会成为从无人机供应链中以 5 到 10,000 美元的价格构建的可行产品。” “它必须由耗资 50,000 美元的拖拉机供应链构建,并搭载带有 GPU 的大型 PC,以及大量摄像头。那时我们开始深入了解所有机器人软件,并发现了从根本上导致这种能源需求与 Nvidia 和 Intel 等平台合作的原因。”
Firu 表示,该公司转向制造加速器芯片——“我们希望拥有的芯片”。
种子轮融资于 2017 年启动,随后的 A 轮融资从潜在客户那里获得了 1300 万美元,包括 Quadric 的主要投资者日本汽车一级电装。 Quadric 的总资金为 1800 万美元。
图灵完备
Quadric 采用指令驱动架构,该架构从数据流架构中获取元素,并将它们与冯诺依曼机的元素相结合。目的是用不太复杂的东西替换边缘设备中的异构系统。该公司声称,作为图灵整机,Quadric Vortex 内核提供了加速与灵活性的结合。该架构可在内核阵列方面进行扩展,并可向下移植到高级(7 或 5 纳米)工艺节点。这适用于功率预算在大约数百毫瓦到 20W 之间的边缘设备应用。
该公司的第一款芯片 Q16 是一个 16 x 16 Vortex 核心阵列。每个内核都具有执行矩阵乘法和 AI 计算的能力,但每个内核还有一个多功能 ALU,用于与、或、归约、移位等运算。软件允许开发人员表达各种算法类型,包括 LSTM 激活函数等。 If-Then-Else 语句可用于整个数组,允许开发人员利用细粒度的稀疏性。
阵列中的每个内核都可以对其相邻内核进行单周期访问,以及对 4 Kb 内核内存的单周期访问。片上存储器也包含在阵列旁边,为内核提供低延迟、确定性的访问。
内核以 Quadric 所谓的“单指令、多解码”方式并行运行;每个内核在每个周期都获得相同的指令。但是基于运行时的动态数据,每个内核可以不同地解释该指令。这允许内核或内核组执行略有不同的功能。
还包括一个专用的广播总线,它优化了阵列的带宽,可用于将常数,例如神经网络权重,一次广播到所有核心(Firu 说,许多计算机视觉算法也有一些循环不变的信息,可以映射到总线上)。
动态信息通过静态的、软件控制的加载存储单元进入阵列,允许确定性的内核运行时。该设备允许从设备的任意两条边同时加载和存储,加上一条边的特殊属性,可用于发送神经网络权重——同时从两条边加载和从第三条边存储可以减少计算执行运行时间。

Daniel Firu(来源:Quadric)
“您可以装入一侧,然后从垂直一侧存放,”Firu 说。 “这允许在软件级别发生一些非常有趣的事情。您还可以开始使用此范例进行数据重新映射和图像旋转等操作。”
同时,片上软件控制的静态存储器(不是缓存)为大型数据结构提供了空间。 Quadric 允许 API 访问这些,因此开发人员可以在其中定义任意数据结构。 Firu 说,在 Q16 芯片中,内存为 8 GB,足以容纳“两个或三个高清帧缓冲区,或整个权重神经网络”。
软件栈
Quadric 在硅之前构建了它的软件堆栈。 Kheterpal 说,一年来,客户一直将它与公司的架构模拟器或 FPGA 一起使用。 Quadric 的堆栈通过基于 LLVM 的编译器抽象出体系结构和指令集,并在其顶部使用 C++ API。
源模式支持不同的数据并行算法,具有处理器架构特性的源级 C++ 控制。随着神经网络变得越来越复杂,Source Mode 还允许开发者表达自定义操作。
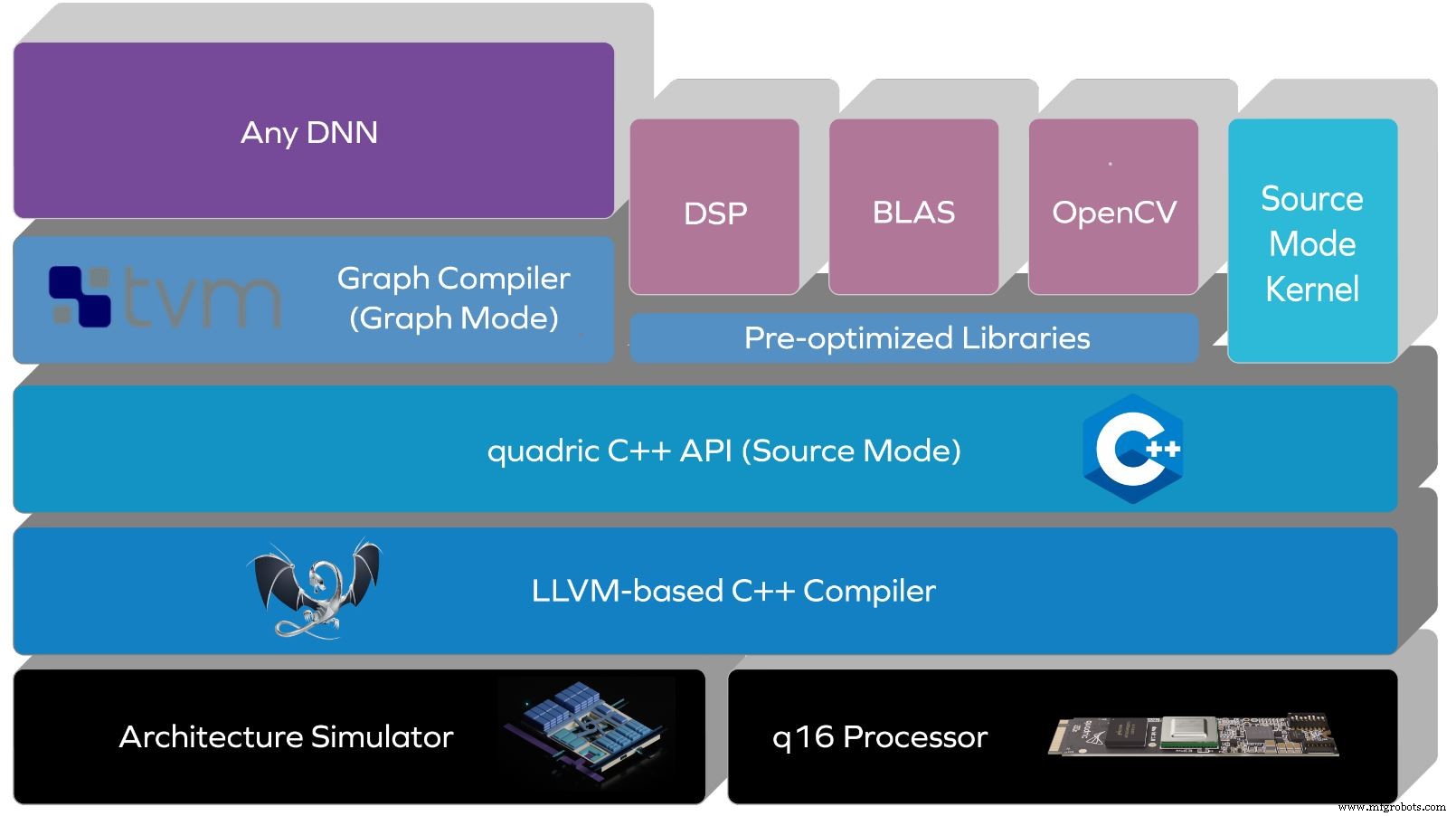
Quadric 的软件栈(来源:Quadric)
堆栈的未来更新将提供无代码图形模式,该模式将支持 TensorFlow 或 ONNX 版本的神经网络。这将包括一个基于 TVM 的深度神经网络 (DNN) 编译器,它可以自动生成代码。
“我们将无代码的强大功能与拥有您自己的自定义代码的灵活性相结合,并以有趣的方式将它们组合起来以实现您的应用程序,”Kheterpal 说。 “大多数平台只会提供带有某种 DNN 编译器的特定于 AI 的架构——但是定制呢?不支持的 DNN 呢?不支持的运算符怎么办?我们没有这些限制,因为这是一个图灵完备的内核,内核可以做任何操作。代码灵活性使开发人员能够编写他们想要的任何算法。”
芯片路线图
Quadric 的 Q16 芯片在 16 纳米硅的 16 x 16 阵列中具有 256 个 Vortex 内核,提供 4 个 INT8 DNN TOPS。它可以以每秒 200 次推理运行 ResNet-50(对于 224 x 224 图像大小的 INT8 参数),平均消耗 2W。
Quadric 的路线图包括第二代架构,以及 Q32 芯片(一个 1,000 个内核的阵列)的流片,“可能是 7 nm,”Firu 说。虽然 Q16 严格来说是一个加速器(它将与系统主机处理器并排放置),但正在开发的 Q32 也可能包括 Arm 或 RISC-V 内核作为主机。
带有 Q16 处理器和 4 GB 直接映射到 Q16 通用内存空间的外部内存的 M.2 格式开发套件现已上市。
>> 本文最初发表在我们的姊妹网站 EE次。
相关内容:
- 硬件加速器为 AI 应用服务
- 当 DSP 击败硬件加速器
- 使用恰到好处的 RISC-V 自定义指令加速应用程序的指南
- 推理芯片性能建立在优化的内存子系统设计之上
- 新的 AI 加速模块增强了边缘性能
- 边缘人工智能挑战内存技术
有关 Embedded 的更多信息,请订阅 Embedded 的每周电子邮件通讯。
嵌入式