

微控制器架构为 AI 发展
如果将人工智能与物联网交叉,你会得到什么? AIoT 是一个简单的答案,但您也获得了微控制器的巨大新应用领域,这得益于神经网络技术的进步,这意味着机器学习不再局限于超级计算机领域。如今,智能手机应用处理器可以(并且确实)为图像处理、推荐引擎和其他复杂功能执行 AI 推理。

一个由数十亿物联网设备组成的生态系统将在未来几年内获得机器学习功能(图片来源:NXP)
将这种能力带入不起眼的微控制器代表了一个巨大的机会。想象一下可以使用 AI 过滤对话中的背景噪音的助听器、可以识别用户面部并切换到个性化设置的智能家电,以及可以使用最小电池运行数年的支持 AI 的传感器节点。在端点处理数据具有不可忽视的延迟、安全和隐私优势。
然而,使用微控制器级设备实现有意义的机器学习并非易事。例如,作为 AI 计算的关键标准的内存通常受到严重限制。但数据科学正在迅速发展以缩小模型尺寸,设备和 IP 供应商正在通过开发工具和整合为现代机器学习的需求量身定制的功能做出回应。
TinyML 起飞
作为该行业快速增长的标志,TinyML 峰会(本月初在硅谷举行的一项新行业盛会)正在不断壮大。据组织者称,去年举行的第一次峰会有 11 家赞助公司,而今年的活动有 27 家,名额早早就售罄,组织者还表示,其全球设计师月度聚会的会员人数大幅增加。
TinyML 委员会联合主席、Qualcomm 的 Evgeni Gousev 表示:“我们看到了一个新世界,其中数以万亿计的智能设备由 TinyML 技术支持,这些设备能够感知、分析并自主行动,为所有人创造一个更健康、更可持续的环境。”展会开幕致辞。
Gousev 将这种增长归因于开发更节能的硬件和算法,并结合更成熟的软件工具。他指出,企业和风险投资正在增加,初创公司和并购活动也在增加。
今天,TinyML 委员会认为该技术已经过验证,并且在微控制器中使用机器学习的初始产品应该会在 2-3 年内上市。人们认为“杀手级应用”还需要 3-5 年的时间。
去年春天,当谷歌首次展示了其用于微控制器的 TensorFlow 框架版本时,技术验证的很大一部分是在去年春天进行的。用于微控制器的 TensorFlow Lite 旨在在只有 KB 内存的设备上运行(核心运行时在 Arm Cortex M3 上适合 16 KB,并且有足够的运算符来运行语音关键字检测模型,总共占用 22 KB)。它只支持推理(不支持训练)。
大玩家
大型微控制器制造商当然会饶有兴趣地关注 TinyML 社区的发展。随着研究使神经网络模型变得越来越小,它们的机会越来越大。
大多数都对机器学习应用程序提供某种支持。例如,STMicroelectronics 有一个扩展包 STM32Cube.AI,它可以在其基于 Arm Cortex-M 的 STM32 系列微控制器上映射和运行神经网络。
瑞萨电子拥有 e-AI 开发环境,允许在微控制器上实现 AI 推理。它有效地将模型转换为可在其 e 2 中使用的形式 studio,兼容C/C++项目。
恩智浦表示,有客户将其低端 Kinetis 和 LPC MCU 用于机器学习应用。该公司正在通过硬件和软件解决方案拥抱人工智能,尽管主要面向其更大的应用处理器和跨界处理器(应用处理器和微控制器之间)。
强力武装
微控制器领域的大多数老牌公司都有一个共同点:Arm。这家嵌入式处理器核心巨头凭借其 Cortex-M 系列主导了微控制器市场。该公司最近发布了全新的 Cortex-M55 内核,该内核专为机器学习应用而设计,尤其是与 Ethos-U55 AI 加速器结合使用时。两者都是为资源受限的环境而设计的。
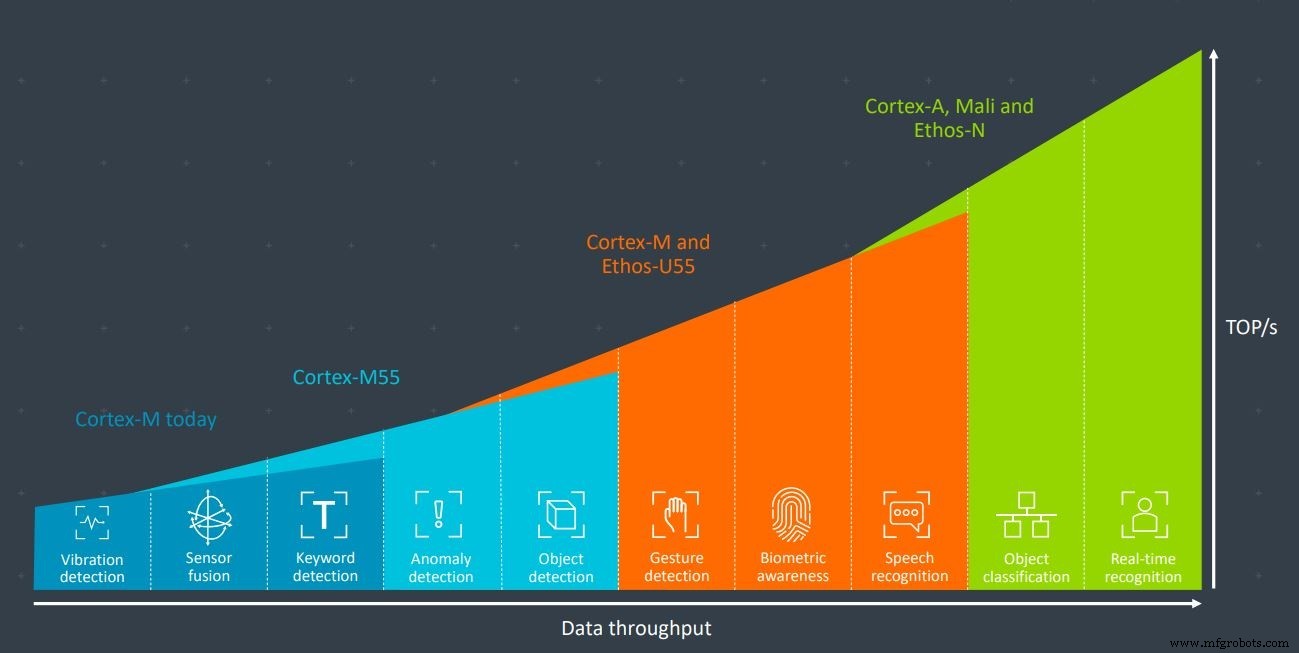
Arm 的 Cortex-M55 和 Ethos-U55 协同使用,具有足够的处理能力,可用于手势识别、生物识别和语音识别等应用(图片:Arm)
但初创公司和小公司如何才能在这个市场上与大公司竞争?
“不是通过构建基于 Arm 的 SoC!因为他们做得非常好,”XMOS 首席执行官马克·利佩特 (Mark Lippett) 笑着说。 “与这些家伙竞争的唯一方法是拥有架构优势……[这意味着] Xcore 在性能方面的内在能力,以及灵活性。”
虽然 XMOS 的 Xcore.ai 是其新发布的用于语音接口的跨界处理器,但不会直接与微控制器竞争,但这种观点仍然成立。任何制造基于 ARM 的 SoC 以与大公司竞争的公司最好在他们的秘密武器中拥有一些非常特别的东西。
缩放电压和频率
初创公司 Eta Compute 在 TinyML 展会期间发布了备受期待的超低功耗设备。它可用于始终在线的图像处理和传感器融合应用中的机器学习,功率预算为 100µW。该芯片使用 Arm Cortex-M3 内核和 NXP DSP 内核——其中一个或两个内核均可用于 ML 工作负载。该公司的秘诀有多种成分,但关键是它为两个内核连续调整时钟频率和电压的方式。这节省了大量功率,尤其是在没有 PLL(锁相环)的情况下实现的。
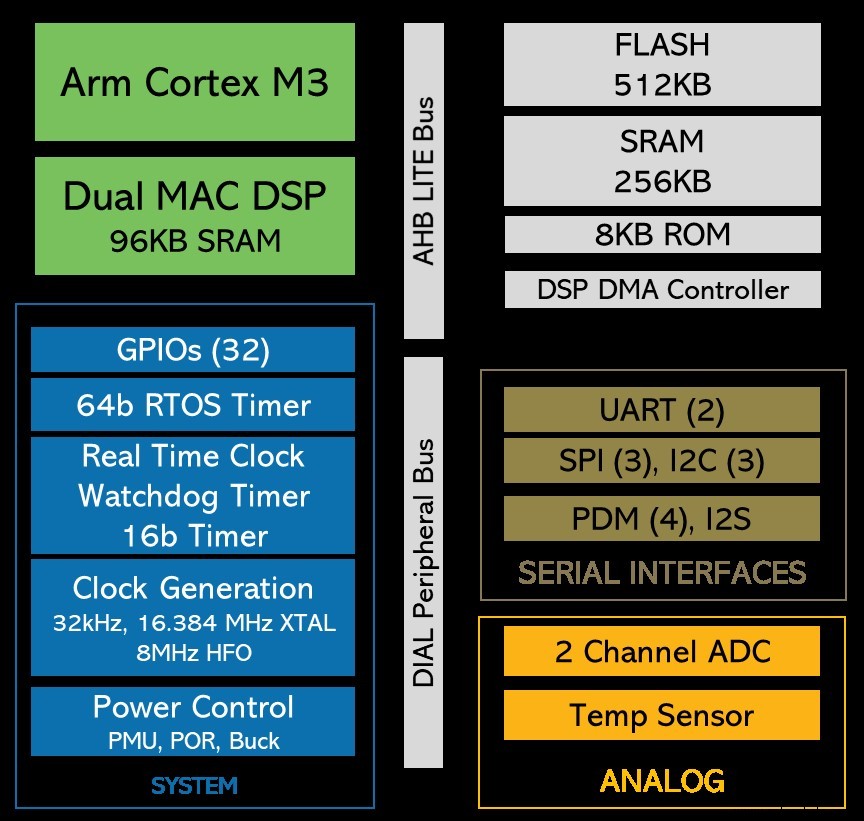
Eta Compute 的 ECM3532 使用 Arm Cortex-M3 内核和 NXP CoolFlux DSP 内核。机器学习工作负载可以由一个或两个处理(图片:Eta Compute)
有了 Arm 的可行竞争对手,包括 RISC-V 基金会提供的新兴指令集架构,为什么 Eta Compute 选择使用 Arm 内核进行超低功耗机器学习加速?
“简单的答案是 Arm 的生态系统非常发达,”Tewksbury 告诉 EETimes . “现在[使用 Arm] 投入生产比使用 RISC-V 容易得多。这种情况在未来可能会改变……RISC-V 有其自身的优势;当然,这对中国市场有利,但我们现在主要着眼于国内和欧洲市场,以及 [我们的设备] 的生态系统。”
Tewksbury 指出,AIoT 面临的主要挑战是应用的广度和多样性。市场相当分散,许多相对利基的应用程序只占很小的数量。然而,总的来说,这个领域可能会扩展到数十亿台设备。
“开发人员面临的挑战是,他们无法投入时间和金钱为每个用例开发定制解决方案,”Tewksbury 说。 “这就是灵活性和易用性变得绝对最重要的地方。这也是我们选择 Arm 的另一个原因——因为生态系统就在那里,工具就在那里,而且客户可以轻松地快速开发产品并将其快速推向市场,而无需进行大量定制。”
在对其 ISA 进行了数十年的锁定和锁定之后,终于在去年 10 月,Arm 宣布将允许客户构建自己的自定义指令,以处理机器学习等专业工作负载。如果使用得当,这种能力还可以提供进一步降低功耗的机会。
Eta Compute 还不能利用这一点,因为它不能追溯适用于现有的 Arm 内核,因此不适用于 Eta 正在使用的 M3 内核。但 Tewksbury 能否看到 Eta Compute 在未来几代产品中使用 Arm 自定义指令来进一步降低功耗?
“绝对,是的,”他说。
替代 ISA
RISC-V 今年受到了很多关注。开源 ISA 允许在无需许可费用的情况下设计处理器,而基于 RISC-V ISA 的设计可以像任何其他类型的 IP 一样受到保护。设计人员可以选择添加哪些扩展,也可以添加自己定制的扩展。
法国初创公司 GreenWaves 是使用 RISC-V 内核瞄准超低功耗机器学习领域的几家公司之一。其设备 GAP8 和 GAP9 分别使用 8 核和 9 核计算集群。
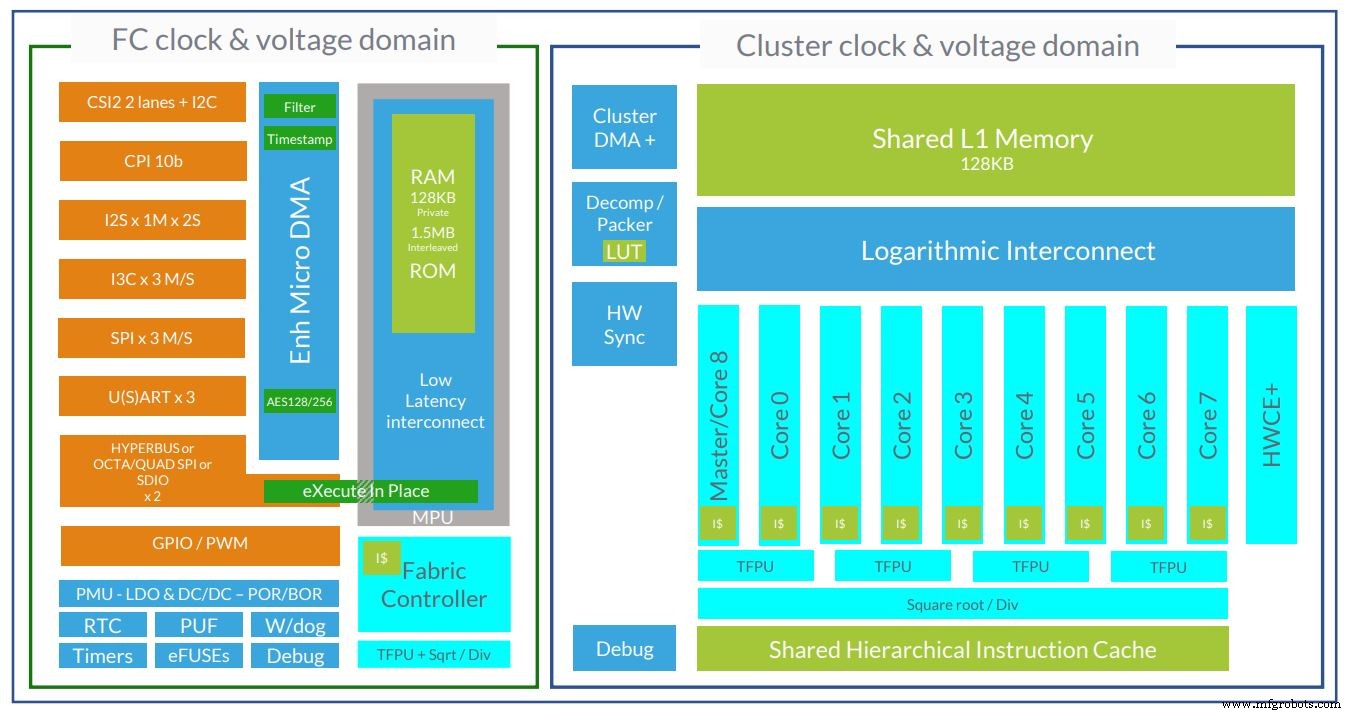
GreenWaves 的 GAP9 超低功耗 AI 芯片架构现在使用 10 个 RISC-V 内核(图片:GreenWaves)
GreenWaves 业务发展副总裁 Martin Croome 向 EETimes 解释 为什么公司使用 RISC-V 内核。
Croome 说:“第一个原因是 RISC-V 使我们能够在指令集级别自定义内核,这是我们大量使用的内核,”并解释说自定义扩展用于降低机器学习和信号处理工作负载的能力. “当公司成立时,如果你想用任何其他处理器架构来做到这一点,要么是不可能的,要么会花费你一大笔钱。而这将花费你的财富基本上是你的投资者的钱流向了另一家公司,这很难证明是合理的。”
与未修改的 RISC-V 内核相比,仅 GreenWaves 的自定义扩展就使其内核的能耗提高了 3.6 倍。但 Croome 也表示 RISC-V 仅仅因为是新的就具有基本的技术优势。
“这是一个非常干净、现代的指令集。它没有任何行李。因此,从实现的角度来看,RISC-V 内核实际上是一个更简单的结构,简单意味着更少的功耗,”他说。
Croome 还指出控制是一个重要因素。 GAP8 设备在其计算集群中有 8 个内核,GreenWaves 需要对内核执行进行非常精细、详细的控制,以实现最大的能效。他说,RISC-V 实现了这一点。
“最后,如果我们能用 Arm 完成所有这些,我们也会用 Arm 完成所有这些,这将是一个更合乎逻辑的选择......因为没有人因为购买 Arm 而被解雇,”他开玩笑说. “软件工具的成熟度远远高于 RISC-V……但话虽如此,现在人们对 RISC-V 的关注度如此之高,以至于这些工具的成熟度增长得非常快。”
总而言之,虽然有些人认为 Arm 对微处理器市场的控制正在减弱,部分原因是来自 RISC-V 的竞争加剧,但该公司正在通过允许一些定制扩展和从一开始就开发专为机器学习设计的新内核做出回应。
事实上,针对超低功耗机器学习应用的市场有 Arm 和非 Arm 设备。随着 TinyML 社区继续致力于缩小神经网络模型大小并开发专用框架和工具,该领域将发展成为一个健康的应用领域,支持各种不同的设备类型。
嵌入式