

结合两个深度学习模型
深度学习是数据分析师武器库中的宝贵工具,在不同领域(包括工业应用)有新应用。深度学习的基本工作原理是利用海量数据构建可以做出准确预测的模型。
让我们考虑一个小例子,说明工业自动化工程师可能会遇到需要结合两种深度学习模型的情况。一家智能手机公司采用生产多种智能手机的生产线。采用深度学习算法的计算机视觉执行生产线的质量控制。
目前,该生产线生产两款智能手机:Phone A 和Phone B。模型A 和B 分别对Phone A 和B 进行质量控制。该公司推出了一款新智能手机 Phone C。生产设施可能需要一种新型号来对第三款名为 Model C 的手机进行质量控制。构建新型号需要大量数据和时间。
<中心>
图一。 视频由提供 马特·陈
另一种选择是结合模型 A 和 B 的学习来构建模型 C。组合模型可以通过对权重进行微小调整来执行质量控制。
另一种需要组合模型的场景是新模型必须同时执行两项任务。两个深度学习模型可以执行这些任务。需要对数据集进行分类并在每个类别中进行预测的模型可以通过组合两个模型来创建:一个可以对大型数据集进行分类,一个可以进行预测。
集成学习
结合多个深度学习模型是集成学习。这样做是为了更好地预测、分类或深度学习模型的其他功能。集成学习还可以创建具有不同深度学习模型组合功能的新模型。
与完全从头开始训练新模型相比,创建新模型有很多好处。
- 需要很少的数据来训练组合模型,因为大部分学习都来自组合模型。
- 与构建新模型相比,构建组合模型所需的时间更少。
- 组合模型时需要更少的计算资源。
- 新的组合模型比获得新模型的组合具有更高的准确性和更高的能力。
由于集成学习的不同优势,通常会执行集成学习来创建新模型。各自的深度学习算法、包和训练模型必须结合不同的模型,最先进的深度学习算法都是用Python编写的。
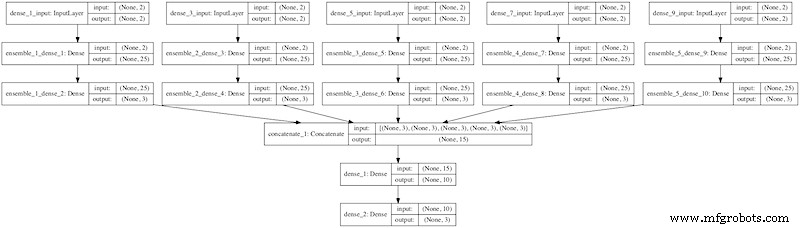
图 2. Python 中深度学习神经网络的堆叠集成。图片由提供 精通机器学习
了解 Python 和各自使用的深度学习工具是组合不同模型的先决条件。一旦所有这些都到位,就会实施不同的技术来组合不同的深度学习算法。它们将在以下部分进行解释。
(加权)平均法
在该方法中,使用两个模型的平均值作为新模型。这是结合两个深度学习模型的最直接的方法。通过取两个模型的简单平均值创建的模型比合并的两个模型具有更高的准确性。
为了进一步提高组合模型的准确性和结果,加权平均是一个可行的选择。赋予不同模型的权重可以基于模型的性能或每个模型接受的训练量。该方法将两种不同的模型结合起来形成一个新的模型。
装袋方法
同一个深度学习模型可以有多次迭代。不同的迭代将使用不同的数据集进行训练,并具有不同的改进水平。将同一深度学习模型的不同版本组合起来就是bagging方法。
方法与平均法相同。同一深度学习模型的不同版本以简单平均或加权平均的方式组合。这种方法有助于创建一个新模型,该模型没有单一模型所建立的确认偏差,使模型更加准确和高性能。
提升方法
boosting 方法类似于对模型使用反馈回路。模型的性能用于调整后续模型。这会创建一个正反馈循环,累积所有有助于模型成功的因素。
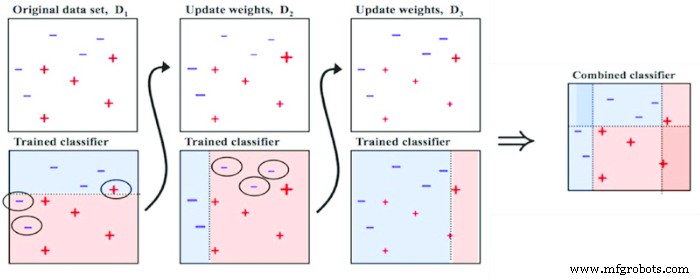
图 3。 集成学习的boosing方法。图片由提供 阿什·帕特尔
提升方法减少了模型所经历的偏差和方差。这是可能的,因为在随后的迭代中过滤掉了这样的消极面。 Boosting 可以通过两种不同的方式完成:基于权重的 boosting 和基于残差的 boosting。
连接方法
当不同的数据源要合并到同一个模型中时使用此方法。这种组合技术接受不同的输入并将它们连接到同一个模型。生成的数据集将具有比原始数据集更多的维度。
当连续多次执行时,数据的维度会增长到非常大的数量,这可能导致过拟合和关键信息丢失,从而降低组合模型的性能。
堆叠方式
集成深度学习模型的堆叠方法集成了不同的方法来开发深度学习模型,利用之前迭代的性能来提升之前的模型。向这个堆叠模型添加一个加权平均的元素可以提高子模型的积极贡献。
类似地,可以将装袋技术和串联技术添加到模型中。将不同技术组合起来进行模型组合的方法可以提高组合模型的性能。
可用于组合深度学习模型的方法论、技术和算法数不胜数,并且一直在不断发展。将有新技术来完成相同的任务,提供更好的结果。下面给出了关于组合模型的关键思想。
- 结合深度学习模型也称为集成学习。
- 结合不同的模型是为了提高深度学习模型的性能。
- 通过组合构建新模型需要更少的时间、数据和计算资源。
- 最常见的组合模型的方法是对多个模型进行平均,采用加权平均可以提高准确性。
- 装袋、提升和串联是用于组合深度学习模型的其他方法。
- 堆叠集成学习使用不同的组合技术来构建模型。
物联网技术