

如何在 VHDL 中创建环形缓冲区 FIFO
循环缓冲区是用于在顺序编程语言中创建队列的流行结构,但它们也可以在硬件中实现。在本文中,我们将在 VHDL 中创建一个环形缓冲区,以在 Block RAM 中实现一个 FIFO。
在实现 FIFO 时,您必须做出许多设计决策。你需要什么样的接口?你受资源限制吗?它应该能够适应过度读取和覆盖吗?延迟可以接受吗?这些是我在被要求创建 FIFO 时出现的一些问题。
在线存在许多免费的 FIFO 实现,以及 Xilinx LogiCORE 等 FIFO 生成器。但是,许多工程师仍然喜欢实现自己的 FIFO。因为即使它们都执行相同的基本队列和出队任务,但考虑到细节时它们可能会有很大的不同。
环形缓冲区的工作原理
环形缓冲区是一种 FIFO 实现,它使用连续内存来存储缓冲数据,并且数据混洗最少。新元素从写入到被读取并从 FIFO 中移除之前一直停留在相同的内存位置。
两个计数器用于跟踪 FIFO 中元素的位置和数量。这些计数器指的是从存储数据的内存空间开始的偏移量。在 VHDL 中,这将是数组单元的索引。对于本文的其余部分,我们将这些计数器称为指针 .
这两个指针是head 和尾巴 指针。头部始终指向将包含下一个写入数据的内存插槽,而尾部则指向将从 FIFO 中读取的下一个元素。还有其他变体,但这是我们要使用的变体。
空状态
![]()
如果head和tail指向同一个元素,则表示FIFO为空。上图显示了一个具有 8 个插槽的示例 FIFO。 head 和 tail 指针都指向元素 0,表示 FIFO 为空。这是环形缓冲区的初始状态。
请注意,如果两个指针都位于另一个索引处,例如 3,则 FIFO 仍然为空。对于每次写入,头指针向前移动一个位置。 FIFO 的用户每读取一个元素,尾指针就会递增。
当任一指针位于最高索引时,下一次写入或读取将导致指针移回最低索引。这就是环形缓冲区的美妙之处,数据不会移动,只有指针会移动。
头引尾

上图显示了五次写入后的相同环形缓冲区。尾指针仍位于槽号 0,但头指针已移动到槽号 5。包含数据的槽在图中以浅蓝色显示。尾指针将指向最旧的元素,而头指向下一个空闲槽。
当头部的索引比尾部的索引高时,我们可以通过头部减去尾部来计算环形缓冲区中的元素数。在上图中,这产生了五个元素。
尾引头部

仅当头部领先于尾部时,从尾部减去头部才有效。在上图中,头部在索引 2 处,尾部在索引 5 处。因此,如果我们执行这个简单的计算,我们会得到 2 – 5 =-3,这没有任何意义。
解决方案是用 FIFO 中的插槽总数偏移头部,在本例中为 8。现在计算得出 (2 + 8) – 5 =5,这是正确的答案。
尾巴将永远追逐头部,这就是环形缓冲区的工作原理。有一半的时间,尾部的指数会高于头部的指数。数据存储在两者之间,如上图中的浅蓝色所示。
完整状态

一个完整的环形缓冲区的尾部将直接指向头部之后的索引。这种方案的结果是我们永远不能使用所有的槽来存储数据,必须至少有一个空闲槽。上图显示了环形缓冲区已满的情况。打开但无法使用的插槽显示为黄色。
专用的空/满信号也可用于指示环形缓冲区已满。这将允许所有内存插槽存储数据,但它需要寄存器和查找表 (LUT) 形式的附加逻辑。因此,我们将使用 keep one open 用于我们实现环形缓冲区 FIFO 的方案,因为这只会浪费更便宜的块 RAM。
环形缓冲区FIFO实现
如何定义进出 FIFO 的接口信号将限制环形缓冲区可能实现的数量。在我们的示例中,我们将使用经典读/写启用和空/完整/有效接口的变体。
会有一个写入数据 输入端的总线,用于承载要推送到 FIFO 的数据。还有一个write enable 信号,当被置位时,将导致 FIFO 对输入数据进行采样。
输出端会有一个读取数据 和一个读取有效 信号由 FIFO 控制。它还将具有读取启用 信号由 FIFO 的下游用户控制。
空 和完整 控制信号是经典 FIFO 接口的一部分,我们也会使用它们。它们由FIFO控制,目的是将FIFO的状态传达给读写器。
背压
在采取行动之前等到 FIFO 为空或已满的问题是接口逻辑没有时间做出反应。顺序逻辑在时钟周期到时钟周期的基础上工作,时钟的上升沿有效地将设计中的事件分成时间步长。

一种解决方案是包含
在我们的实现中,前面的信号将被命名为 empty_next 和 full_next ,只是因为我更喜欢后缀而不是前缀名称。

实体
下图显示了我们的环形缓冲区 FIFO 的实体。除了端口中的输入和输出信号外,它还有两个通用常量。 RAM_WIDTH generic 定义了输入和输出字的位数,每个内存槽将包含的位数。
RAM_DEPTH generic 定义将为环形缓冲区保留的插槽数。因为预留了一个slot来表示环形缓冲区已满,所以FIFO的容量将是RAM_DEPTH – 1. RAM_DEPTH 常数应与目标 FPGA 上的 RAM 深度相匹配。块 RAM 原语中未使用的 RAM 将被浪费,它不能与 FPGA 中的其他逻辑共享。
entity ring_buffer is
generic (
RAM_WIDTH : natural;
RAM_DEPTH : natural
);
port (
clk : in std_logic;
rst : in std_logic;
-- Write port
wr_en : in std_logic;
wr_data : in std_logic_vector(RAM_WIDTH - 1 downto 0);
-- Read port
rd_en : in std_logic;
rd_valid : out std_logic;
rd_data : out std_logic_vector(RAM_WIDTH - 1 downto 0);
-- Flags
empty : out std_logic;
empty_next : out std_logic;
full : out std_logic;
full_next : out std_logic;
-- The number of elements in the FIFO
fill_count : out integer range RAM_DEPTH - 1 downto 0
);
end ring_buffer;
除了时钟和复位,端口声明将包括经典的数据/使能读写端口。这些被上游和下游模块用于将新数据推送到 FIFO,并从中弹出最旧的元素。
rd_valid 当 rd_data 端口包含有效数据。此事件在 rd_en 上的一个脉冲之后延迟一个时钟周期 信号。我们将在本文末尾详细讨论为什么必须这样。
然后是 FIFO 设置的空/满标志。 empty_next 当剩下 1 个或 0 个元素时,信号将被断言,而 empty 仅当 FIFO 中有 0 个元素时才有效。同样,full_next 信号将指示还有 1 个或 0 个元素的空间,而 full 仅在 FIFO 无法容纳另一个数据元素时才断言。
最后还有一个fill_count 输出。这是一个整数,将反映当前存储在 FIFO 中的元素数量。我将这个输出信号包含在内只是因为我们将在模块内部使用它。通过实体断开它本质上是免费的,用户在实例化这个模块时可以选择不连接这个信号。
声明区域
在VHDL文件的声明区,我们将声明一个自定义类型、一个子类型、一些信号,以及一个供环形缓冲区模块内部使用的过程。
type ram_type is array (0 to RAM_DEPTH - 1) of
std_logic_vector(wr_data'range);
signal ram : ram_type;
subtype index_type is integer range ram_type'range;
signal head : index_type;
signal tail : index_type;
signal empty_i : std_logic;
signal full_i : std_logic;
signal fill_count_i : integer range RAM_DEPTH - 1 downto 0;
-- Increment and wrap
procedure incr(signal index : inout index_type) is
begin
if index = index_type'high then
index <= index_type'low;
else
index <= index + 1;
end if;
end procedure;
首先,我们声明一个新类型来为我们的 RAM 建模。 ram_type type 是一个向量数组,由通用输入确定大小。下一行使用新类型来声明 ram 将数据保存在环形缓冲区中的信号。
在下一个代码块中,我们声明 index_type ,整数的子类型。它的范围将由 RAM_DEPTH 间接控制 通用的。在子类型声明下面,我们使用索引类型来声明两个新信号,头指针和尾指针。
然后是一组信号声明,它们是实体信号的内部副本。它们与实体信号具有相同的基本名称,但后缀为 _i 表示它们是供内部使用的。我们使用这种方法是因为使用 inout 被认为是不好的风格 实体信号上的模式,尽管这会产生相同的效果。
最后,我们声明一个名为 incr 的过程 这需要一个 index_type 信号作为参数。该子程序将用于增加头指针和尾指针,并在它们处于最大值时将它们回零。 head 和 tail 是 integer 的子类型,通常不支持包装行为。我们将使用该过程来规避这个问题。
并发语句
在架构的顶部,我们声明了我们的并发语句。我更喜欢在正常流程之前收集这些单线信号分配,因为它们很容易被忽略。并发语句实际上是一种过程,您可以在这里阅读更多关于并发语句的信息:
如何在 VHDL 中创建并发语句
-- Copy internal signals to output empty <= empty_i; full <= full_i; fill_count <= fill_count_i; -- Set the flags empty_i <= '1' when fill_count_i = 0 else '0'; empty_next <= '1' when fill_count_i <= 1 else '0'; full_i <= '1' when fill_count_i >= RAM_DEPTH - 1 else '0'; full_next <= '1' when fill_count_i >= RAM_DEPTH - 2 else '0';
在并发分配的第一个块中,我们将实体信号的内部版本复制到输出。这些行将确保实体信号在完全相同的时间遵循内部版本,但在模拟中具有一个增量周期延迟。
第二个也是最后一个并发语句块是我们分配输出标志的地方,表示环形缓冲区的满/空状态。我们基于 RAM_DEPTH 进行计算 通用和在 fill_count 信号。 RAM 深度是一个不会改变的常数。因此,标志只会随着填充计数的更新而改变。
更新头指针
头指针的基本功能是每当从该模块外部发出写使能信号时递增。我们通过传递 head 来做到这一点 向前面提到的 incr 发出信号 程序。
PROC_HEAD : process(clk)
begin
if rising_edge(clk) then
if rst = '1' then
head <= 0;
else
if wr_en = '1' and full_i = '0' then
incr(head);
end if;
end if;
end if;
end process;
我们的代码包含一个额外的 and full_i = '0' 声明以防止覆盖。如果您确定数据源在 FIFO 已满时永远不会尝试写入,则可以省略此逻辑。如果没有这种保护,覆盖将导致环形缓冲区再次变空。
如果在环形缓冲区已满时增加头指针,则头将指向与尾相同的元素。因此,模块将“忘记”包含的数据,FIFO 填充看起来是空的。
通过评估 full_i 在增加头指针之前发出信号,它只会忘记被覆盖的值。我认为这个解决方案更好。但无论哪种方式,如果发生覆盖,则表明该模块之外存在故障。
更新尾指针
尾指针以与头指针类似的方式递增,但 read_en 输入用作触发器。就像覆盖一样,我们通过包含 and empty_i = '0' 来防止过度读取 在布尔表达式中。
PROC_TAIL : process(clk)
begin
if rising_edge(clk) then
if rst = '1' then
tail <= 0;
rd_valid <= '0';
else
rd_valid <= '0';
if rd_en = '1' and empty_i = '0' then
incr(tail);
rd_valid <= '1';
end if;
end if;
end if;
end process;
此外,我们正在发送 rd_valid 在每个有效读取信号。读取的数据始终在rd_en之后的时钟周期有效 被断言,如果 FIFO 不为空。有了这些知识,就不需要这个信号了,但为了方便起见,我们将它包括在内。 rd_valid 如果在模块实例化时信号未连接,则信号将在合成中被优化掉。
推断块 RAM
为了使综合工具推断块 RAM,我们必须在同步过程中声明读写端口而无需复位。我们将在每个时钟周期对 RAM 进行读写,并让控制信号处理这些数据的使用。
PROC_RAM : process(clk)
begin
if rising_edge(clk) then
ram(head) <= wr_data;
rd_data <= ram(tail);
end if;
end process;
这个过程不知道下一次写入何时发生,但它不需要知道。相反,我们只是在不断地写作。当 head 信号由于写入而增加,我们开始写入下一个插槽。这将有效地锁定写入的值。
更新填充计数
fill_count 信号用于产生满和空信号,这些信号又用于防止FIFO的覆盖和过度读取。填充计数器由对头尾指针敏感的组合过程更新,但这些信号仅在时钟的上升沿更新。因此,填充计数也会在时钟沿之后立即发生变化。
PROC_COUNT : process(head, tail)
begin
if head < tail then
fill_count_i <= head - tail + RAM_DEPTH;
else
fill_count_i <= head - tail;
end if;
end process;
填充计数只需通过从头部减去尾部来计算。如果尾部索引大于头部,我们必须添加 RAM_DEPTH 的值 常量来获取当前在环形缓冲区中的正确数量的元素。
环形缓冲区 FIFO 的完整 VHDL 代码
library ieee;
use ieee.std_logic_1164.all;
entity ring_buffer is
generic (
RAM_WIDTH : natural;
RAM_DEPTH : natural
);
port (
clk : in std_logic;
rst : in std_logic;
-- Write port
wr_en : in std_logic;
wr_data : in std_logic_vector(RAM_WIDTH - 1 downto 0);
-- Read port
rd_en : in std_logic;
rd_valid : out std_logic;
rd_data : out std_logic_vector(RAM_WIDTH - 1 downto 0);
-- Flags
empty : out std_logic;
empty_next : out std_logic;
full : out std_logic;
full_next : out std_logic;
-- The number of elements in the FIFO
fill_count : out integer range RAM_DEPTH - 1 downto 0
);
end ring_buffer;
architecture rtl of ring_buffer is
type ram_type is array (0 to RAM_DEPTH - 1) of
std_logic_vector(wr_data'range);
signal ram : ram_type;
subtype index_type is integer range ram_type'range;
signal head : index_type;
signal tail : index_type;
signal empty_i : std_logic;
signal full_i : std_logic;
signal fill_count_i : integer range RAM_DEPTH - 1 downto 0;
-- Increment and wrap
procedure incr(signal index : inout index_type) is
begin
if index = index_type'high then
index <= index_type'low;
else
index <= index + 1;
end if;
end procedure;
begin
-- Copy internal signals to output
empty <= empty_i;
full <= full_i;
fill_count <= fill_count_i;
-- Set the flags
empty_i <= '1' when fill_count_i = 0 else '0';
empty_next <= '1' when fill_count_i <= 1 else '0';
full_i <= '1' when fill_count_i >= RAM_DEPTH - 1 else '0';
full_next <= '1' when fill_count_i >= RAM_DEPTH - 2 else '0';
-- Update the head pointer in write
PROC_HEAD : process(clk)
begin
if rising_edge(clk) then
if rst = '1' then
head <= 0;
else
if wr_en = '1' and full_i = '0' then
incr(head);
end if;
end if;
end if;
end process;
-- Update the tail pointer on read and pulse valid
PROC_TAIL : process(clk)
begin
if rising_edge(clk) then
if rst = '1' then
tail <= 0;
rd_valid <= '0';
else
rd_valid <= '0';
if rd_en = '1' and empty_i = '0' then
incr(tail);
rd_valid <= '1';
end if;
end if;
end if;
end process;
-- Write to and read from the RAM
PROC_RAM : process(clk)
begin
if rising_edge(clk) then
ram(head) <= wr_data;
rd_data <= ram(tail);
end if;
end process;
-- Update the fill count
PROC_COUNT : process(head, tail)
begin
if head < tail then
fill_count_i <= head - tail + RAM_DEPTH;
else
fill_count_i <= head - tail;
end if;
end process;
end architecture;
上面的代码显示了环形缓冲区 FIFO 的完整代码。您可以填写下面的表格,以便立即将 ModelSim 项目文件和测试台邮寄给您。
测试台
FIFO 在一个简单的测试台中实例化,以演示它是如何工作的。您可以使用下面的表格下载测试平台的源代码以及 ModelSim 项目。
通用输入已设置为以下值:
- RAM_WIDTH:16
- RAM_DEPTH:256
测试台首先重置 FIFO。释放复位后,测试平台会将顺序值 (1-255) 写入 FIFO,直到它写满。最后在测试完成前清空FIFO。
我们可以在下图中看到测试平台完整运行的波形。 fill_count 信号在波形中显示为模拟值,以更好地说明 FIFO 的填充水平。
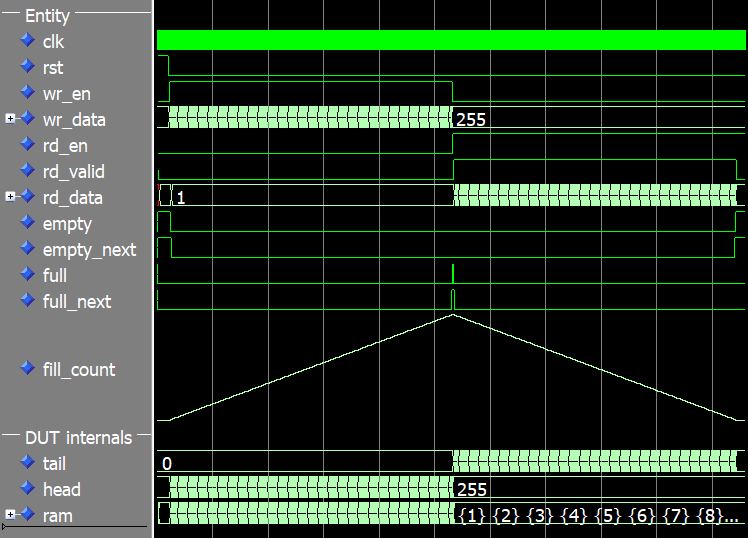
头、尾和填充计数在模拟开始时为 0。在 full 信号被断言,头部的值为 255,fill_count 也是如此 信号。即使我们的 RAM 深度为 256,填充计数也只会上升到 255。那是因为我们使用了 keep one open 我们在本文前面讨论过的方法来区分满和空。
在我们停止写入 FIFO 并开始读取它的转折点,头部值冻结,而尾部和填充计数开始减少。最后,在仿真结束时,当FIFO为空时,头部和尾部的值为255,而填充计数为0。
除了演示目的之外,不应将此测试平台视为足够。它没有任何自检行为或逻辑来验证 FIFO 的输出是否正确。
我们将在下周的文章中深入探讨受约束的随机验证主题时使用此模块 .这是与更常用的定向测试不同的测试策略。简而言之,测试平台将与 DUT(被测设备)进行随机交互,而 DUT 的行为必须通过单独的测试平台流程进行验证。最后,当一些预定义的事件发生时,测试就完成了。
点此阅读后续博文:
约束随机验证
在 Vivado 中进行综合
我在 Xilinx Vivado 中合成了环形缓冲区,因为它是最流行的 FPGA 实现工具。但是,它应该适用于所有具有双端口块 RAM 的 FPGA 架构。
我们必须为通用输入分配一些值,以便能够将环形缓冲区实现为独立模块。这是在 Vivado 中使用 Settings 完成的 → 一般 → 泛型/参数 菜单,如下图所示。
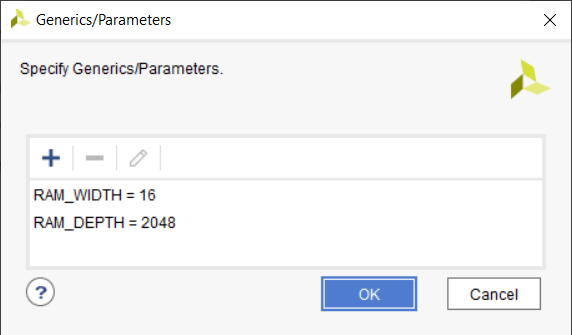
RAM_WIDTH 的值 设置为 16,这与模拟中的相同。但我已经设置了 RAM_DEPTH 到 2048,因为这是我选择的 Xilinx Zynq 架构中 RAMB36E1 原语的最大深度。我们可以选择一个较低的值,但它仍然会使用相同数量的块 RAM。较高的值会导致使用多个 Block RAM。
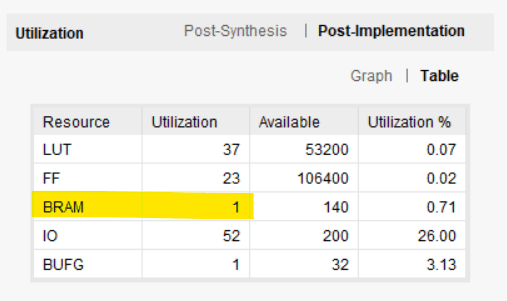
下图显示了 Vivado 报告的实施后资源使用情况。我们的环形缓冲区确实消耗了一个块 RAM 和一些 LUT 和触发器。
丢弃有效信号
您可能会问自己 rd_en 之间的一个时钟周期延迟是否 和 rd_valid 信号实际上是必要的。毕竟,数据已经存在于 rd_data 上 当我们断言 rd_en 信号。我们不能只使用这个值,让环形缓冲区在我们从 FIFO 读取的下一个时钟周期跳到下一个元素吗?

严格来说,我们不需要 valid 信号。为了方便起见,我包含了这个信号。关键部分是我们必须等到我们断言 rd_en 之后的时钟周期 信号,否则 RAM 来不及反应。
FPGA 中的 Block RAM 是完全同步的组件,它们需要一个时钟沿来读取和写入数据。读写时钟不必来自同一个时钟源,但必须有时钟边沿。此外,RAM 输出和下一个寄存器(触发器)之间不能有逻辑。这是因为用于为 RAM 输出提供时钟的寄存器位于 Block RAM 原语中。

上图显示了值如何从 wr_data 传播的时序图 在我们的环形缓冲区中输入,通过RAM,最后出现在rd_data 输出。因为每个信号都是在时钟上升沿采样的,所以从我们开始驱动写端口到它出现在读端口上需要三个时钟周期。在接收模块可以利用这些数据之前,还要经过一个额外的时钟周期。
减少延迟
有一些方法可以缓解这个问题,但它是以 FPGA 中使用的额外资源为代价的。让我们尝试一个实验来减少环形缓冲区读取端口的一个时钟周期延迟。在下面的代码片段中,我们更改了 rd_data 从同步过程输出到对 ram 敏感的组合过程 和 tail 信号。
PROC_READ : process(ram, tail)
begin
rd_data <= ram(tail);
end process;
不幸的是,此代码无法映射到块 RAM,因为 RAM 输出和 rd_data 上的第一个下游寄存器之间可能存在组合逻辑 信号。
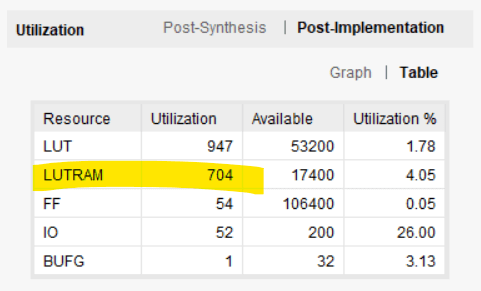
下图显示了 Vivado 报告的资源使用情况。 Block RAM 已被 LUTRAM 取代;一种在 LUT 中实现的分布式 RAM 形式。 LUT 的使用量从 37 个 LUT 飙升至 947 个。查找表和触发器比块 RAM 更昂贵,这就是我们首先使用块 RAM 的全部原因。
有多种方法可以在 Block RAM 中实现环形缓冲区 FIFO。您可以通过使用另一种设计来节省额外的时钟周期,但它会以额外支持逻辑的形式产生成本。对于大多数应用程序,本文介绍的环形缓冲区就足够了。
更新:
如何使用 AXI 就绪/有效握手在 Block RAM 中创建环形缓冲区 FIFO
在下一篇博文中,我们将使用约束随机验证为环形缓冲区模块创建一个更好的测试平台 .
点此阅读后续博文:
约束随机验证
VHDL