

云中断:为什么以及如何发生?
IT 越依赖云服务,您就越有可能因云中断而遭受停机和收入损失。超过 60% 的使用公共云的组织在 2022 年报告由于这些事件而遭受损失,因此中断并不是公司不太可能面临的异常事件。
但是中断是否足以成为永远离开云的理由?还是应该坚持使用这种基础架构类型,尽管存在偶尔停机的风险?
本文介绍了您需要了解的有关云中断的所有信息 .我们概述了它们的主要原因,检查了令人大开眼界的统计数据,展示了如何最大限度地减少云停机的影响,并研究了近年来发生的影响最大的中断。

什么是云中断?
云中断是云提供商的服务对最终用户不可用的时间跨度。供应商的基础设施出现故障(由于错误、电源故障等),并且客户无法访问基于云的资产,直到供应商解决问题为止。
在影响方面,现场数据中心停机和云中断之间没有区别。在这两种情况下,您都无法访问 IT 资产,但云计算的不干涉方法增加了一些独特的考虑因素:
- 云中断几乎没有故障可见性,因此用户通常不知道出了什么问题。
- 提供商的团队负责修复错误,因此客户不会参与恢复过程。
- 由于您无法查看或控制问题,因此无法知道服务何时会重新上线。
与本地硬件一样,有两种类型的可能中断:
- 已计划(通常由于定期维护而发生)。
- 计划外(当提供程序遇到意外错误并且必须执行恢复措施时发生)。
最近的研究表明,计划外停机的成本比计划停机时间(本地和云端)高出 35%。之所以存在价格差异,是因为意外事件需要更长的时间来识别和修复——而且停电持续的时间越长,损失就越大。
与现场硬件相比,基于云的基础架构导致停机时间更频繁,但严重程度更低 .由于没有托管系统能够提供 100% 的正常运行时间,因此客户可以容忍偶尔的中断,以换取云计算的优势。这种意愿在市场增长中也很明显——到 2024 年,云计算将占全球 IT 总支出的 14.2%(高于 2020 年的 9.1%)。
云中断原因
云中断是由供应商控制范围内和之外的多种原因引起的。以下是最常见的列表:
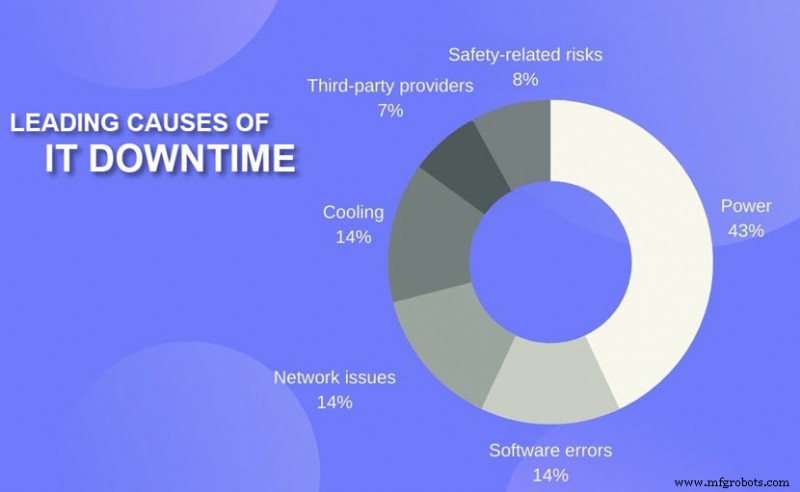
- 停电: 与电源相关的问题导致了 43% 的云中断,并造成严重的停机时间和经济损失。不间断电源 (UPS) 故障是电力事故的第一大原因。
- 网络安全: 诸如分布式拒绝服务 (DDoS) 之类的网络攻击会使数据中心的传入流量过载。在这种情况下,最终用户无法通过相同的网络基础设施访问服务。其他威胁(例如勒索软件或 SQL 注入)可能会迫使提供商关闭服务并离线解决问题。
- 人为错误: 一个错误的命令或布线错误可能会导致整个 IT 基础架构瘫痪。人为错误会导致物理和软件问题,进而导致服务中断。
- 技术问题: 云服务依赖于一个复杂的硬件技术系统,因此如果一个错误能够在雷达下隐藏足够长的时间,就会导致云服务中断。
- 软件错误: 故障和错误在云数据中心中很常见。问题背后的常见罪魁祸首是数据格式错误、与故障相关的错误、计时错误和常量值错误。
- 网络问题: 与网络通信和第三方电信合作伙伴相关的问题是导致云中断的另一个常见原因。
- 维护: 定期维护和系统升级有时会导致中断,但最终用户通常会提前知道这些情况。
- 环境原因: 飓风、火灾、雷暴和地震等事件也会引发云停机,这可能会使设施处于危险之中,也可能会破坏该地区的电网。
- 更复杂的部署: 更复杂的部署模型(例如混合、分布式和多云)使数据中心运营复杂化,从而产生更多错误机会。
当云关闭时会发生什么?
在最好的情况下,云中断仅持续几分钟并影响少数用户或服务。在最坏的情况下,停电会使客户的业务瘫痪半天或更长时间。一家公司失去了对所有基于云的资产的访问权限,并且在中断结束之前一直处于中断状态。
虽然具有威胁性,但第三方提供商的错误是“仅”7% 的 2021 年严重中断的原因 .严重中断必须涉及以下一项(或多项):
- 重大财务损失。
- 名誉受损。
- 违规行为。
- 丧生。
尽管存在更紧迫的问题(如下面的圆环图所示),但请记住,平均每分钟的停机时间会花费 5,600 美元 (对于企业来说,这个每分钟的数字是 9,000 美元)。如果您没有做好准备(即您没有数据备份、灾难恢复等),云中断可能会导致您的服务停止并严重影响利润。
在云中保留一小部分业务的公司不太容易受到中断的影响。例如,如果您只在云中托管电子邮件,即使长达一天的中断也不是灾难性的。您可以等待事件发生或运行功能减少的应用程序,如果您使用云来运行物联网平台或执行支付处理,这种策略将不起作用。
在某些情况下,云中断会导致永久性数据丢失(丢失的数据量取决于备份的频率)。此外,如果中断导致数据泄露或泄漏,严格行业的客户将承担法律罚款,因此在决定在云存储中保留哪些内容时要小心。
用户可以做什么?
以下是公司为减轻云中断的影响而采取的措施:
- 消除单点故障: 在现场服务器机房或二级提供商处准备每个关键任务 IT 组件的备份。如果云出现故障,您可以执行故障转移(切换到备用服务器、硬件组件、网络等的过程)以确保业务连续性。
- 制定应急计划: 灾难恢复计划概述了团队在发生中断时所做的分步策略。该计划提供有关保护数据、执行故障转移、确保业务连续性和恢复操作的说明。及时规划云中断可避免浪费时间评估停机期间的最佳行动方案。
- 投资于更高可用性的 SLA: 如果您的关键业务任务无法承受长时间的云中断,请寻找更高可用性的服务水平协议 (SLA),例如保证 99.999% 正常运行时间(每年最多 5.25 分钟停机时间)的协议。这些合同的成本更高,但让您的服务保持在线成为云提供商的重中之重。
- 执行定期数据备份: 如果云中断损坏或删除数据库,备份可确保您的团队有办法恢复文件的最新版本。理想情况下,备份应该在每小时一次到每天一次之间的任意时间自动进行(取决于任务关键性)。
- 尽快检测中断: 您的团队设置的任何其他云监控功能都有助于实时识别中断,而不是等待提供商的通知。以下是用于改进停机检测并确保及时故障转移的最佳云监控工具列表。
近期最大的云中断
使用云时,云中断是不可避免的,即使是最流行的提供商(如 Azure、AWS 和 Google Cloud)也无法避免停机。让我们来看看最近历史上一些最严重的云中断。
Azure 中断(2021 年 10 月)
2021 年 10 月,Microsoft Azure 遭遇中断,导致虚拟机服务中断 6 小时 .在中断期间,许多用户无法部署新的虚拟机或更新扩展。基本的服务管理操作(如启动、创建和删除)也会导致错误。
云中断的原因是 VM 查询无法检索到所需的工件版本数据。恢复后的一份报告显示,基于软件的错误发生在 Microsoft 迁移其 VM 架构之一时。
Google Cloud 中断(2021 年 11 月)
Google Cloud 宕机了大约 两个小时 去年11月中旬,影响到:
- 家得宝。
- Snapchat。
- Etsy。
- 不和谐。
- Spotify。
当访问者尝试访问受影响的网站时,它们会显示 404 错误。谷歌报告称,云中断的原因是负责负载平衡的网络配置出现故障。
AWS 中断(2021 年 12 月)
大规模的连接活动激增使 AWS 的一个旗舰设施中的网络设备不堪重负,影响了各种网站和应用程序。一些最著名的“受害者”是:
- 亚马逊的网站。
- Prime 视频。
- Netflix。
- IMDb.
- PlayStation 网络。
数据中心问题导致内部 AWS 网络出现严重延迟。客户应用程序感受到了连锁反应,遭受交通延误或完全关闭约 7 小时 .
两次后续 IBM 中断(2022 年 1 月)
IBM 基础架构的一个问题影响了达拉斯地区的云服务超过 五个小时 .内部团队解决了这个问题,但意外地导致了虚拟私有云额外的一个小时的问题。次要问题影响了全球用户,包括美国、日本、加拿大和德国。
AWS/Slack 中断(2022 年 2 月)
Slack 在 2 月份遭遇 AWS 云资源中断,导致通信平台无法正常使用 5 小时 .超过 11,000 名被举报的用户无法:
- 发送或接收消息。
- 上传文件。
- 加入频道。
- 启动桌面应用。
Slack 的团队从未分享云中断背后的原因,并要求所有受影响的用户在恢复后重启应用并清除缓存。
iCloud 中断(2022 年 3 月)
Apple 的 15 项主要服务中断了 四个小时 3 月由于云中断,包括:
- 应用商店。
- Apple 地图。
- Apple 电视。
苹果的企业和零售系统也出现了问题。该公司后来透露,根本原因是与公司的域名系统(DNS)有关的问题。
Google Cloud 中断(2022 年 3 月)
2022 年 3 月 8 日,Google Cloud 用户遭遇服务错误两个半小时 . Spotify 和 Discord 都在中断中。
用于处理配置的 Traffic Director 代码的更改导致了该错误。根据恢复后的报告,错误的代码更改忽略了配置数据格式的迁移,因此平台无意中删除了用户的编程。
Atlassian 中断(2022 年 4 月)
今年最大的 Atlassian 中断从 4 月 5 日开始,到 4 月 18 日结束(尽管一些用户在 4 月 8 日开始恢复服务)。该公司解释说,此次停电是由于团队沟通不足和计划不周的事件响应计划造成的。
尽管这次云中断持续了将近两周 对于一些用户来说,没有关于客户数据重大丢失的报告。但是,Atlassian 的旗舰产品 Trello 和 Jira 的用户都受到了该问题的影响。
Microsoft Azure 中断(2022 年 6 月)
6 月 7 日,Azure 客户无法连接到托管在美国东部 2 区域(主要是弗吉尼亚州)的资源。中断持续了大约 12 小时 并且不会影响依赖区域冗余基础设施的消费者。受损服务包括:
- 应用洞察。
- 日志分析。
- 托管身份服务。
- 媒体服务。
- NetApp 文件。
罪魁祸首是其中一个本地数据中心突然发生电源振荡,导致空气处理机组 (AHU) 关闭。
Cloudflare 中断(2022 年 6 月)
6 月,Cloudflare 的一次意外中断造成了持续 一个半小时的重大中断 ,下架热门网站,例如:
- 不和谐。
- 购物。
- Fitbit。
- 大部队。
这家总部位于旧金山的供应商解释说,计划外停机是因为其 19 个数据中心的网络配置发生了变化。
不要忽视云中断计划的价值
近年来的云中断示例传达了一个明确的信息:尽管云改变了 IT 游戏规则,但技术并非万无一失 .关心最终用户和应用可用性的公司必须为偶尔的停机做好准备,这使得备份和灾难恢复 (BDR) 成为使用基于云的资源不可或缺的一部分。
云计算