

神经网络训练数据集:如何训练和验证 Python 神经网络
在本文中,我们将使用 Excel 生成的样本来训练多层感知器,然后我们将看到网络在验证样本上的表现.
如果您想开发 Python 神经网络,那么您来对地方了。在深入探讨本文关于如何使用 Excel 为您的网络开发训练数据的讨论之前,请考虑查看以下系列的其余部分以了解背景信息:
- 如何使用神经网络进行分类:什么是感知器?
- 如何使用简单的感知器神经网络示例对数据进行分类
- 如何训练基本的感知器神经网络
- 了解简单的神经网络训练
- 神经网络训练理论简介
- 了解神经网络中的学习率
- 使用多层感知器进行高级机器学习
- Sigmoid 激活函数:多层感知器神经网络中的激活
- 如何训练多层感知器神经网络
- 了解多层感知器的训练公式和反向传播
- Python 实现的神经网络架构
- 如何在 Python 中创建多层感知器神经网络
- 使用神经网络进行信号处理:神经网络设计中的验证
- 训练神经网络数据集:如何训练和验证 Python 神经网络
什么是训练数据?
在现实场景中,训练样本由某种测量数据和“解决方案”组成,这些“解决方案”将帮助神经网络将所有这些信息概括为一致的输入-输出关系。
例如,假设您希望神经网络根据颜色、形状和密度来预测番茄的食用质量。您不知道颜色、形状和密度与整体美味的确切关系,但您可以 测量颜色、形状和密度,然后您做 有味蕾。因此,您需要做的就是收集成千上万的西红柿,记录它们的相关物理特征,品尝每一个(最好的部分),然后将所有这些信息放入表格中。
每一行就是我所说的一个训练样本,有四列:其中三列(颜色、形状和密度)是输入列,第四列是目标输出列。
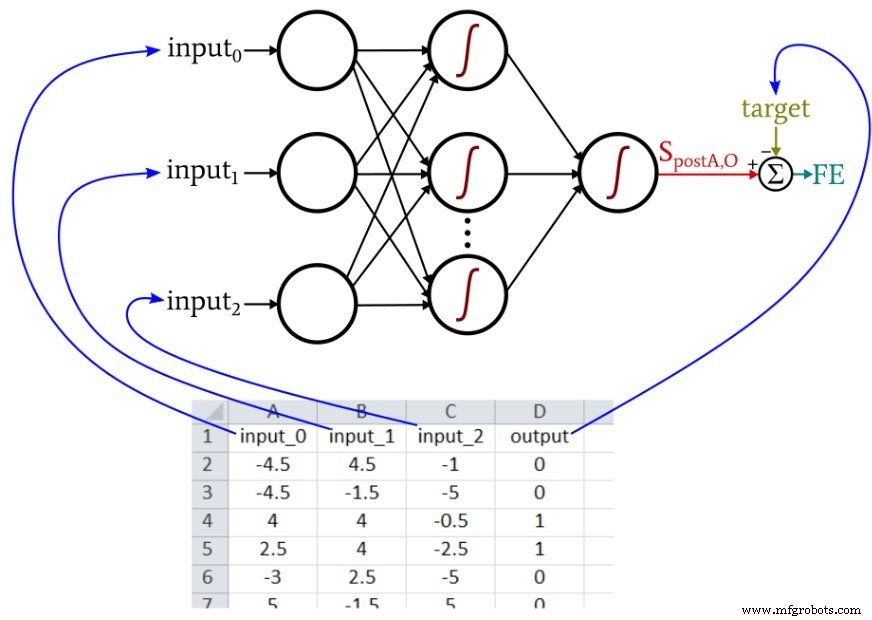
在训练过程中,神经网络会找出三个输入值和输出值之间的关系(如果存在相干关系)。
量化训练数据
请记住,一切都必须以数字形式处理。您不能将字符串“plum-shaped”用作神经网络的输入,并且“mouthwatering”也不能用作输出值。您需要量化您的测量和分类。
对于形状,您可以为每个番茄分配一个从 –1 到 +1 的值,其中 –1 代表完美的球形,+1 代表极度拉长。对于食用质量,您可以按照从“不可食用”到“可口”的五分制对每个番茄进行评分,然后使用单热编码将评分映射到五元素输出向量。
下图向您展示了如何将这种类型的编码用于神经网络输出分类。
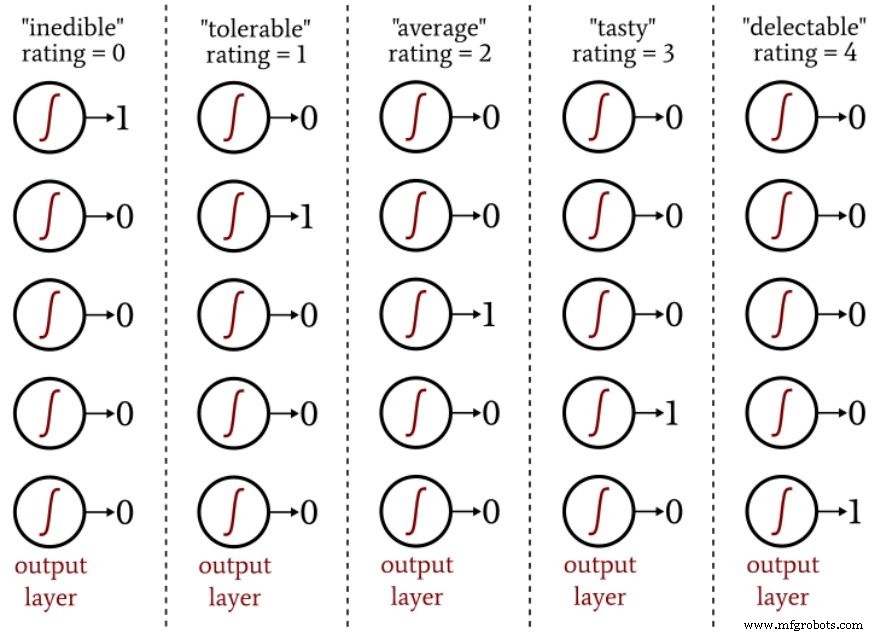
one-hot 输出方案允许我们以与逻辑 sigmoid 激活兼容的方式量化非二元分类。逻辑函数的输出本质上是二元的,因为与输出值非常接近最小值或最大值的无限范围的输入值相比,曲线的过渡区域很窄:
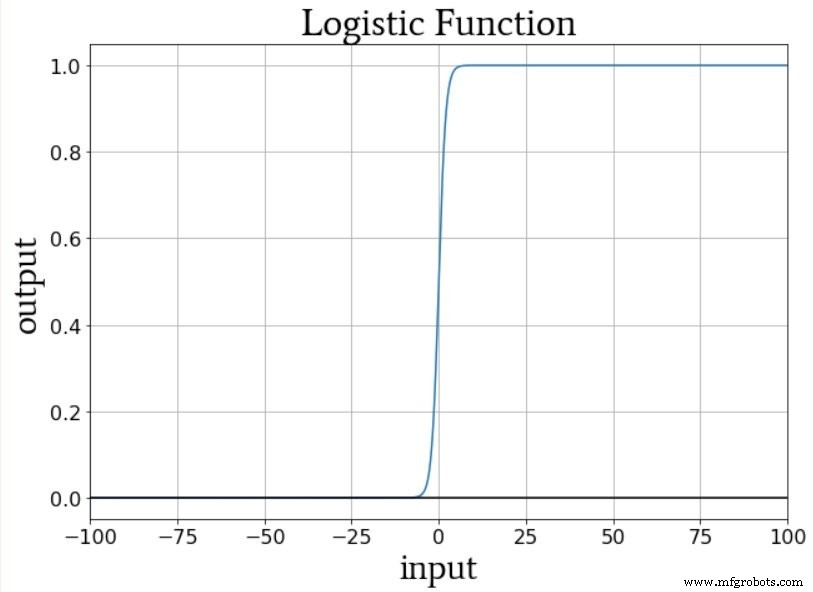
因此,我们不想用单个输出节点配置这个网络,然后提供输出值为 0、1、2、3 或 4(即 0、0.2、0.4、0.6 或 0.8)的训练样本如果你想保持在 0 到 1 的范围内);输出节点的逻辑激活函数将强烈支持最小和最大评级。
神经网络只是不明白得出所有西红柿都不能食用或美味的结论是多么荒谬。
创建训练数据集
我们在第 12 部分中讨论的 Python 神经网络从 Excel 文件中导入训练样本。我将用于此示例的训练数据组织如下:
我们当前的感知器代码仅限于一个输出节点,因此我们所能做的就是执行真/假类型的分类。输入值为 –5 到 +5 之间的随机数,使用此 Excel 公式生成:
=RANDBETWEEN(-10, 10)/2
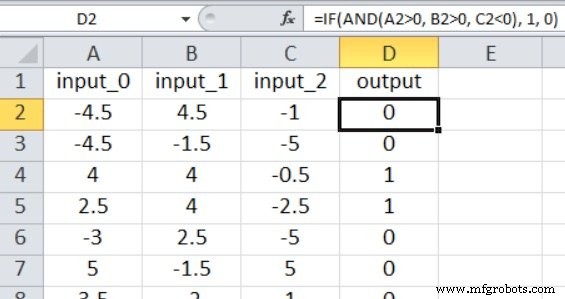
如截图所示,输出计算如下:
=IF(AND(A2>0, B2>0, C2<0), 1, 0)
因此,仅当 input_0 大于零、input_1 大于零且 input_2 小于零时,输出才为真。否则就是假的。
这是感知器需要从训练数据中提取的数学输入-输出关系。您可以根据需要生成任意数量的样本。对于这样一个简单的问题,5000个样本1个epoch就可以达到非常高的分类准确率。
训练网络
您需要将输入维度设置为 3 (I_dim =3,如果您使用的是我的变量名)。我将网络配置为具有四个隐藏节点 (H_dim =4),我选择了 0.1 (LR =0.1).
找到 training_data =pandas.read_excel(...) 语句并插入电子表格的名称。 (如果您无法访问 Excel,Pandas 库也可以读取 ODS 文件。)然后只需单击“运行”按钮即可。在我的 2.5 GHz Windows 笔记本电脑上训练 5000 个样本只需几秒钟。
如果您使用的是我在第 12 部分中包含的完整“MLP_v1.py”程序,验证(参见下一节)会在训练完成后立即开始,因此您需要在训练网络之前准备好验证数据.
验证网络
为了验证网络的性能,我创建了第二个电子表格并使用完全相同的公式生成输入和输出值,然后以与导入训练数据相同的方式导入此验证数据:
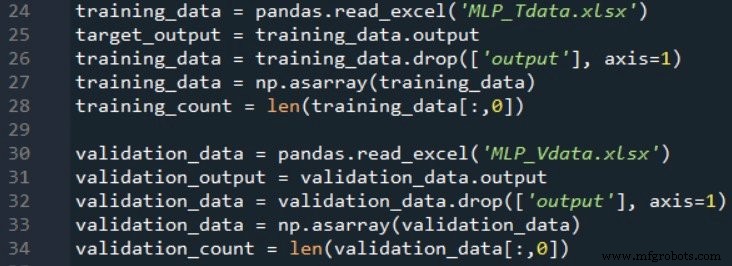
下一段代码摘录向您展示了如何执行基本验证:
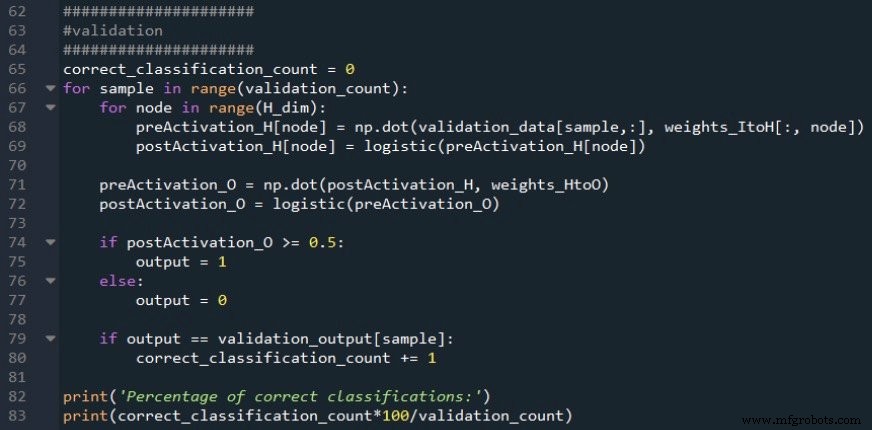
我使用标准前馈过程计算输出节点的激活后信号,然后使用 if/else 语句应用阈值,将激活后值转换为真/假分类值。
分类准确率的计算方法是将当前验证样本的分类值与目标值进行比较,计算正确分类的数量,然后除以验证样本的数量。
请记住,如果您有 np.random.seed(1) 指令注释掉,每次运行程序时权重将初始化为不同的随机值,因此,分类准确度会从一次运行到下一次。我使用上面指定的参数、5000 个训练样本和 1000 个验证样本进行了 15 次独立运行。
分类准确率最低为88.5%,最高为98.1%,平均为94.4%。
结论
我们已经介绍了一些与神经网络训练数据相关的重要理论信息,并使用我们的 Python 语言多层感知器进行了初步训练和验证实验。我希望你喜欢 AAC 的神经网络系列——自第一篇文章以来我们已经取得了很大的进步,还有很多我们需要讨论的!
工业机器人