

使用 tinyML 和自动化机器学习构建有效的物联网应用
物联网可以使用微型传感器对环境和机器进行持续监控。传感器技术、微控制器和通信协议的进步使得物联网平台的大规模生产成为可能,具有许多连接选项,而且价格合理。由于物联网硬件成本低廉,传感器正大规模部署在公共场所、住宅和机器上。
这些传感器 24/7 全天候监控与其部署环境相关的物理属性,并生成大量数据。例如,部署在旋转机械上的加速度计和陀螺仪不断记录连接到轴上的转子的振动模式和角速度。空气质量传感器持续监测室内或室外空气中的气态污染物。婴儿监视器中的麦克风一直在监听。智能手表内的传感器不断测量重要的健康参数。同样,其他各种传感器,如磁力计、压力、温度、湿度、环境光等,可以测量部署在任何地方的物理条件。
机器学习 (ML) 算法能够在这些数据中发现有趣的模式,这是手动分析和检查无法理解的。物联网设备和 ML 算法的融合可实现广泛的智能应用程序和增强的用户体验,这通过低功耗、低延迟和轻量级机器学习推理(即 tinyML)成为可能。如图 1 所示,许多垂直行业正在因这种融合而发生革命性变化,包括但不限于可穿戴技术、智能家居、智能工厂(工业 4.0)、汽车、机器视觉和其他智能消费电子设备。
带有自动机器学习的tinyML
由于多种优势,部署在物联网设备中的微型微控制器 (MCU) 上的 ML 算法特别受关注:
- 数据隐私和安全:机器学习推理发生在本地嵌入式微控制器上,而不必将数据流传输到云端进行处理。数据保留在设备上和本地,私密且安全。
- 节能:由于没有/很少传输数据,tinyML 算法消耗的功率要少得多。
- 低延迟和高可用性:由于推理是在本地执行的,延迟是毫秒级的,不受网络延迟和可用性的影响。
点击查看全尺寸图片

图 1:tinyML 为传统物联网设备添加高级功能(来源:Qeexo)
使用传感器数据的自动化机器学习涉及图 2 中阐明的步骤。在这些步骤之前,目标 ML 应用程序的传感器配置和质量数据收集已完成。 Qeexo AutoML 等自动化机器学习平台管理整个工作流程,为 Arm Cortex-M0-to-M4 类 MCU 和其他受限环境构建轻量级和高性能机器学习模型。
点击查看全尺寸图片
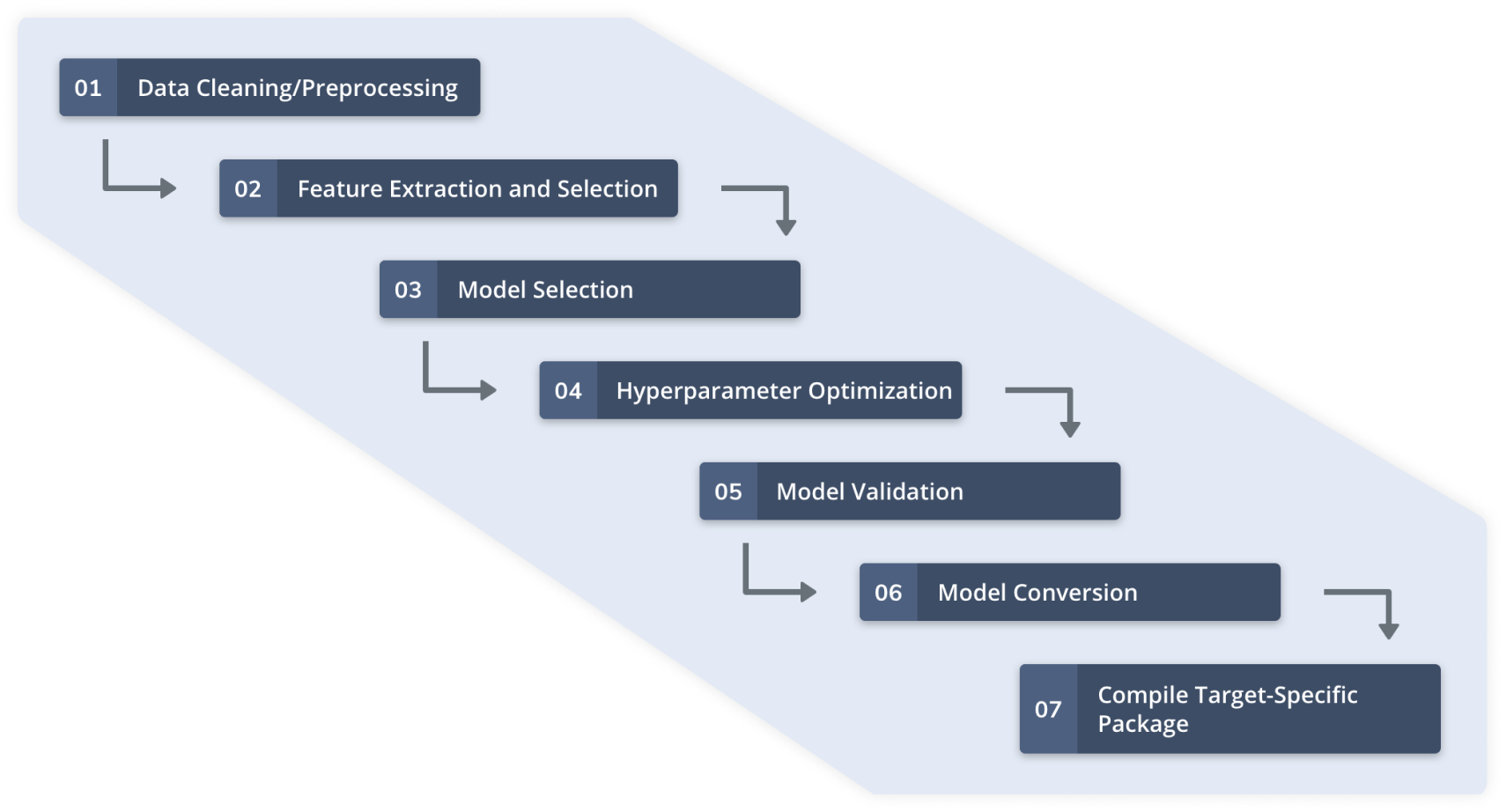
图 2:Qeexo AutoML 工作流程(来源:Qeexo)
采用 ARM® Cortex™ M0+ 架构的tinyML
物联网技术的激增和传感器的大规模部署要求进一步推动了微控制器架构和机器学习计算的界限。例如,运行频率为 48 MHz 的 Arm Cortex M0+ MCU 因其低功耗特性而广泛用于专为物联网应用设计的传感器板上。与以 64 MHz 运行并消耗 15mA 的 Cortex M4 版本相比,它的每个 I/O 引脚仅消耗 7 mA。
Cortex-M0+ MCU 评级的低功耗是以减少内存和计算配置文件为代价的。 M0+ MCU只能进行32位定点数学运算,没有饱和算术支持,缺乏DSP能力。基于此 MCU,Arduino Nano 33 IoT 是流行的物联网平台之一,仅配备 256 KB 闪存和 32 KB SRAM。相比之下,采用 Cortex M4 架构的流行传感器模块 Arduino Nano 33 BLE Sense 可以进行 32 位浮点运算,具有 DSP 和饱和算法支持,以及四倍的闪存和八倍的 SRAM。
由于以下三个主要挑战,在 M0+ 上部署机器学习算法比在 M4 上部署更具挑战性:
- 定点计算: 典型的传感器数据机器学习涉及数字信号处理、特征提取和运行推理。从传感器信号中提取统计和基于频率(例如 FFT 分析)的特征对于开发高性能机器学习模型至关重要。代表现实世界物理现象的传感器数据流本质上是非平稳的。一般来说,从非平稳传感器信号中提取的信息越好,开发高性能机器学习模型的机会就越大。在保持商业级精度和性能的同时以定点表示执行数学运算具有挑战性。完全定点机器学习管道从传感器数据表示开始,一直运行到用于生成分类/回归输出的模型推理。
- 低内存容量: 256 KB 的闪存和 32 KB 的 SRAM 对机器学习模型的大小和这些模型在执行期间可以使用的运行时内存进行了严格限制。现实世界的机器学习问题通常具有复杂的决策/分类边界,由具有大量参数的机器学习模型表示。对于基于树的集成模型,解决如此复杂的问题可能会导致树很深和大量 booster,影响模型大小和运行时内存。减小模型大小通常以牺牲模型性能为代价——通常不是最理想的权衡标准。
- 低 CPU 速度: 在选择用于商业部署的模型时,低延迟一直是一个关键指标。与 64 MHz M4 架构相比,我们在 48 MHz M0+ 架构上牺牲的 16 MHz 时钟速度在毫秒级延迟测量方面有很大不同。
AutoML M0+ 框架
Qeexo AutoML 旨在应对这些挑战,提供定点机器学习管道,针对 Arm Cortex M0+ 架构进行了高度优化。该管道包括在定点、定点特征计算中处理传感器数据,以及基于树的集成算法的定点推理,例如梯度提升机 (GBM)、随机森林 (RF) 和极限梯度提升( XGBoost) 算法。 Qeexo AutoML 以非常有效的数据结构对集成模型参数进行编码,并将它们与解释逻辑相结合,从而对 M0+ 目标进行极快的推理。图 3 阐明了 Qeexo 为 Arm Cortex M0+ 嵌入式目标开发的定点机器学习流水线。
点击查看全尺寸图片
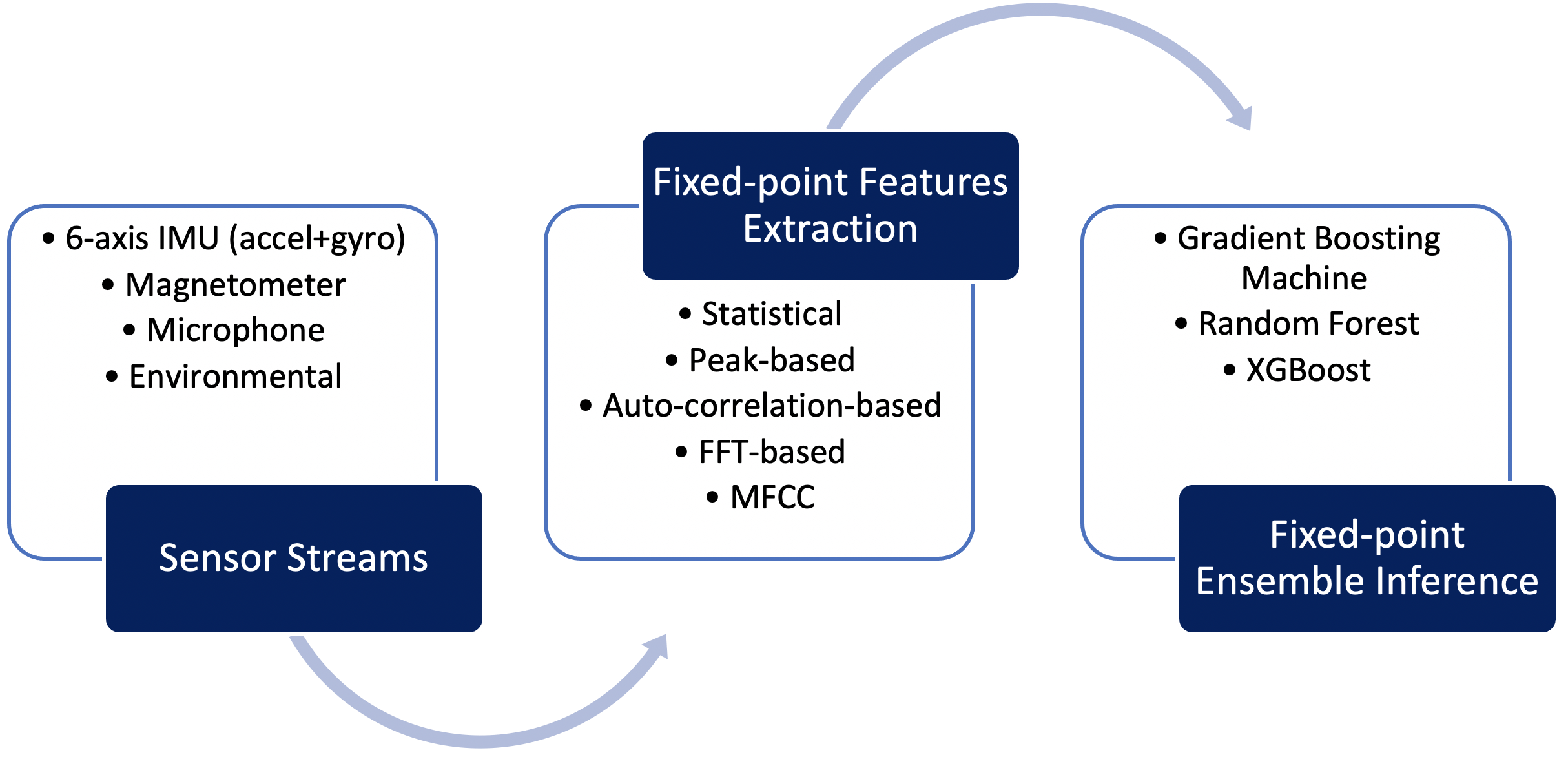
图 3:Qeexo AutoML M0+ 推理管道(来源:Qeexo)
Qeexo AutoML 执行正在申请专利的模型压缩和量化,以在不影响分类性能的情况下进一步减少开发的集成模型的内存占用。图 4 描述了针对 Cortex M0+ 嵌入式目标的 Qeexo AutoML 训练过程。
点击查看全尺寸图片
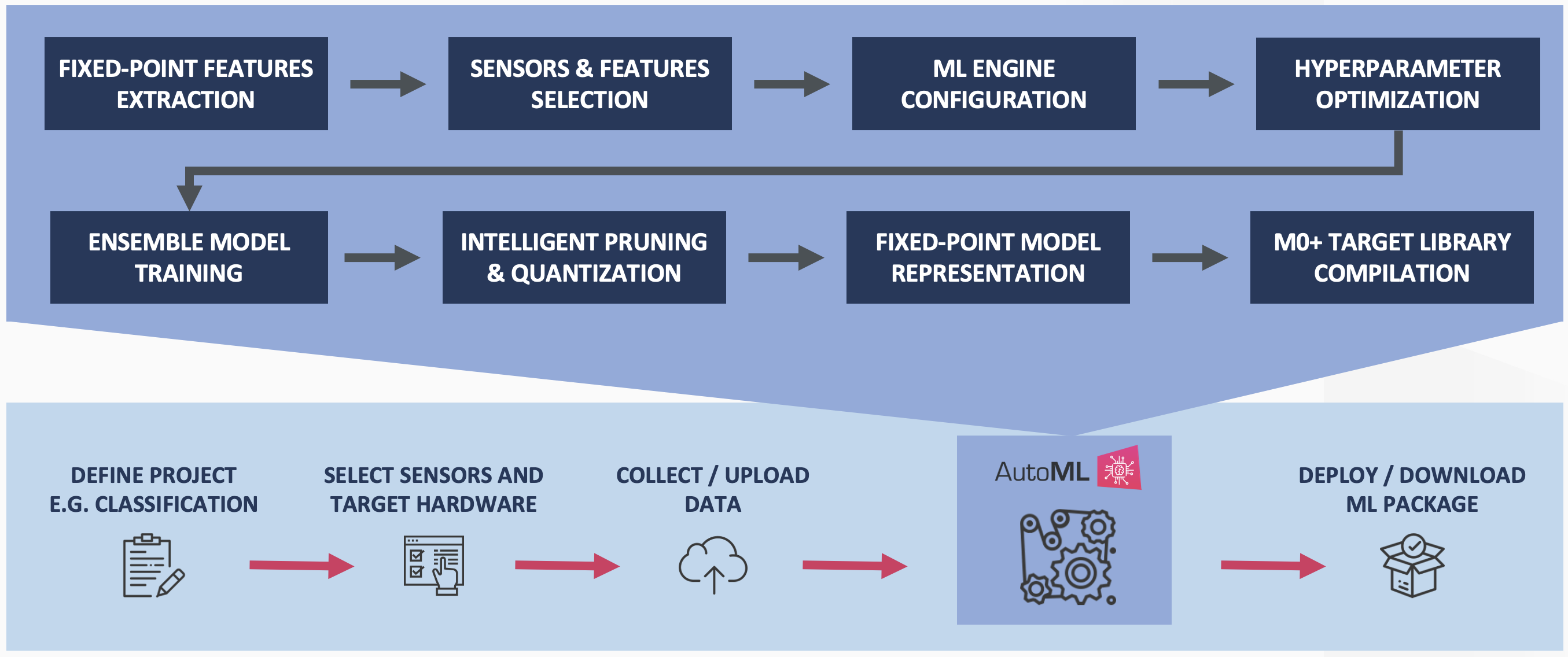
图 4:Qeexo AutoML M0+ 训练管道(来源:Qeexo)
智能剪枝
智能修剪允许在不损失性能的情况下压缩模型。简单来说,Qeexo AutoML首先按照超参数优化器的推荐构建全尺寸的集成模型,然后智能地只选择最强大的助推器。
这种增长一个更大的模型然后针对目标部署智能地修剪它的方法比首先构建一个更小的模型更有效。初始更大的模型提供了选择高性能助推器(或树)的机会,最终导致更好的模型性能。
如图5所示,压缩后的集成模型约为1/10 th 完整模型的大小,同时具有更高的交叉验证性能。 (X 轴表示集成模型中的树(或 booster)数量,y 轴表示交叉验证性能。)请注意,我们的 Qeexo AutoML 智能剪枝方法仅选择了 20 个最强大的 booster,从而实现了 90% 的压缩模型尺寸。
点击查看全尺寸图片
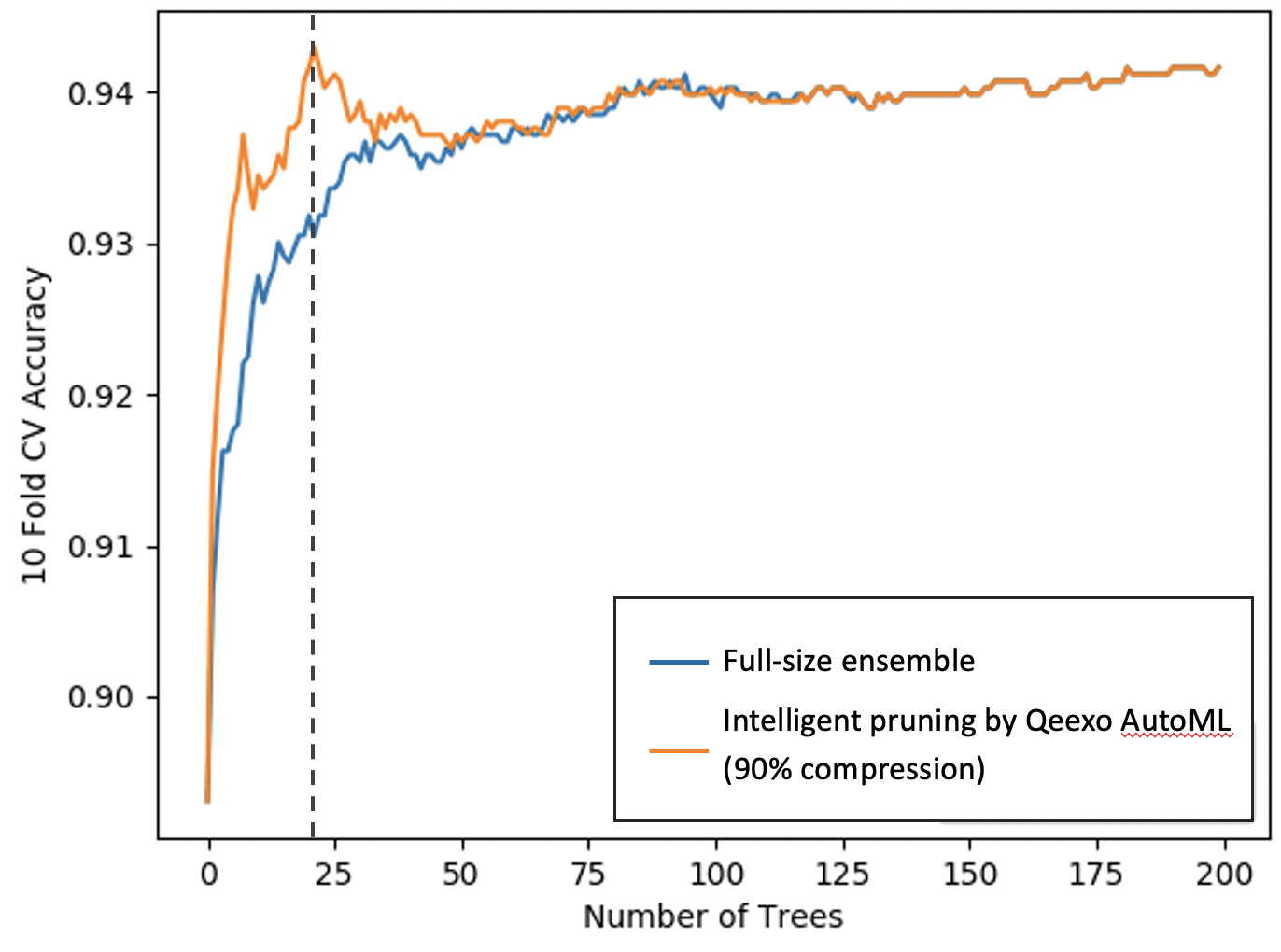
图 5:Qeexo AutoML 智能模型修剪(来源:Qeexo)
集成模型量化
Qeexo AutoML 执行集成算法的训练后量化。训练后量化是基于神经网络的模型的商品化功能,在 TensorFlow Lite 等框架中开箱即用。然而,集成模型的量化是 Qeexo 正在申请专利的技术,它可以进一步减小模型大小,同时改善 MCU 级别的延迟,而模型性能几乎没有下降。 Qeexo AutoML M0+ 管道生成以 32 位精度表示的定点集成模型。 16 位和 8 位量化的附加选项可以分别将模型进一步减少 ½ 和 ¼,速度提高 2 到 3 倍。
tinyML 的示例用例
有哪些 tinyML 应用程序或用例?有无限的可能性,在这里我们重点介绍几个:
- 我们想要制作一个智能的、支持人工智能的墙,用户可以点击它来控制照明(打开/关闭和改变灯光强度)。我们可以定义与开/关和强度控制相关的手势,然后使用安装在墙后的加速度计和陀螺仪模块收集和标记手势数据。有了这些标记数据,Qeexo AutoML 可以使用 AI 算法来构建模型来检测墙壁上的“敲”和“擦拭”手势来控制照明。在下面的视频中,您可以在几分钟内看到 Qeexo AutoML 开发的原型智能墙。
- 使用机器学习和物联网,我们希望确保按照运输指南极其谨慎地处理货物。在下面的视频中,您可以看到支持 AI 的货箱如何检测货件从源头到目的地的处理方式。
- 人工智能与物联网的融合还可以打造智能厨房台面。下面的视频展示了 Qeexo AutoML 构建的用于检测各种厨房用具的模型。
- 机器监控是 tinyML 最有前途的用例之一。在下面的视频中检测到多种机器故障模式。
- 异常检测是另一种从机器学习中受益匪浅的场景。通常,很难收集工业环境中各种故障的数据,而监控机器的健康运行状态则相对容易。只需观察健康的运行状态,Qeexo AutoML 算法就可以开发用于异常检测的 AI 系统,如第 1 部分(下)、第 2 部分、第 3 部分和第 4 部分所示。
- 使用嵌入在可穿戴设备中的传感器进行活动识别是另一个有益于我们日常生活的用例。下面的视频演示了如何在几分钟内使用 Qeexo AutoML 构建活动识别解决方案。
物联网技术