

在边缘使用 DSP 实现音频 AI
机器学习一旦局限于具有几乎无限资源的云服务器,出于各种原因,包括更低的延迟、降低的成本、能源效率和增强的隐私,机器学习正在进入边缘设备。将数据发送到云端进行解释所需的时间可能令人望而却步,例如自动驾驶汽车中的行人识别。将数据发送到云端所需的带宽可能很昂贵,更不用说云服务本身的成本,例如语音命令的语音识别。
能量是将数据来回发送到服务器与本地化处理之间的权衡。机器学习计算很复杂,如果不能有效执行,很容易耗尽边缘设备的电池。边缘决策还将数据保存在设备上,这对用户隐私很重要,例如智能手机上语音指示的敏感电子邮件。音频 AI 是边缘推理的丰富示例;以及一种专门用于音频机器学习用例的新型数字信号处理器 (DSP),可以在网络边缘实现更好的性能和新功能。
永远在线的语音唤醒是边缘机器学习的最早例子之一:在唤醒系统的其余部分以确定下一步行动之前,先聆听诸如“Hey Siri”或“OK Google”之类的关键字。如果此关键字检测在通用应用处理器上运行,则可能需要超过 100mW。在一天的过程中,这会耗尽智能手机的电池电量。因此,第一款实现此功能的手机将算法移植到一个运行功率低于 5mW 的小型 DSP 上。如今,这些相同的算法可以在智能麦克风中的专用音频和机器学习 DSP 上以低于 0.5mW 的功率运行。
一旦边缘设备启用始终在线的音频机器学习,它可以做比低功耗语音识别更多的事情:上下文感知,例如设备是在拥挤的餐厅还是繁忙的街道、环境音乐识别、超声波房间识别、甚至可以识别附近是否有人在大喊大笑。这些类型的功能将支持新的复杂用例,从而改进边缘设备并使用户受益。
边缘机器学习推理的最佳性能和能源效率需要大量的硬件定制,表 1 中收集了一些最具影响力的技术。实施这些功能将提高边缘机器学习推理效率。
神经网络推理所需的大多数算术运算是矩阵向量乘法。这是因为机器学习模型通常表示为矩阵,这些矩阵被应用于表示为向量的新刺激物。改进边缘机器学习推理的最常用技术是使矩阵向量乘法非常有效。融合乘法后跟累加 (MAC) 是解决此问题的常用方法。
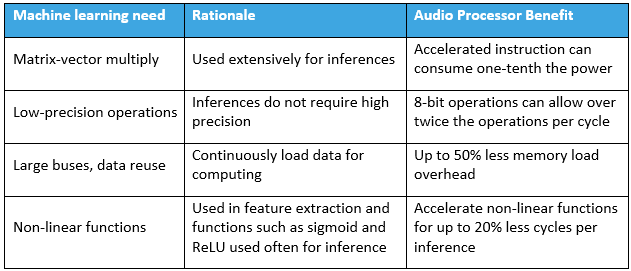
尽管训练阶段对数值精度很敏感,但推理阶段可以以低精度(例如 8 位)获得接近等效的结果。限制精度可以大大降低边缘计算的复杂度。为此,英特尔和德州仪器等处理器公司增加了精度有限的 MAC。 Texas Instruments 的 TMS320C6745 每个周期可以执行 8 个 8 位的 MAC。此外,Knowles 的音频 DSP 支持 16 个 MACS,每个周期为 8 位。
训练和推理阶段都对内存子系统施加了压力。处理器对宽字宽的支持通常会得到改进以适应这一点。 Intel 最新的高性能处理器具有 AVX-512,它支持将 512 位/周期传输到 64 个乘法器阵列。 Texas Instruments 6745 使用 64 位总线来增加内存带宽。楼氏先进的音频处理器使用 128 位总线,在大芯片面积和高带宽之间取得了良好的平衡。此外,音频机器学习架构(如 RNN 或 LSTM)通常需要反馈。这对芯片架构提出了额外的要求,因为数据依赖会导致严重流水线架构的停滞。
虽然传统的机器学习可以处理原始数据,但音频机器学习算法通常会执行频谱分析和特征提取来馈送神经网络。传统信号处理功能(例如 FFT、音频滤波器、三角函数和对数)的加速对于能源效率而言是必要的。后续运算通常使用各种非线性向量运算,例如 sigmoid,实现为双曲正切或整流线性单元(所有负数都更改为零的绝对值函数)。这些复杂的非线性操作在传统处理器上需要很多周期。这些功能的单周期指令也提高了机器学习音频 DSP 的能效。
总而言之,专门用于机器学习和音频处理的高级处理器能够以低成本实现实时、始终在线的边缘推理,同时保持隐私。通过指令集支持的架构决策来保持低能耗,以允许每个周期和更宽的内存总线进行多次操作,以在低功耗下保持高性能。随着公司继续在边缘专用计算方面进行创新,使用它的机器学习用例只会增加。

Jim Steele 是 Knowles 公司的技术战略副总裁。
>> 本文最初发表于我们的姊妹网站 EE Times:“DSP 上的机器学习:在边缘启用音频 AI。”
物联网技术