

加速边缘人工智能:专用处理器和内存的关键作用
人工智能不再只是一个流行词,而是推动当今计算平台设计的全球趋势。虽然 GPU 为数据中心中大规模语言模型的训练提供了动力,但人工智能的前沿现在位于物联网传感器、安全摄像头和自主机器人等功率受限设备的边缘。
为了将数十亿端点从单纯的云代理转变为自主的设备端推理引擎,我们必须优化计算和内存。真正重要的指标是每瓦每秒兆次运算 (TOPS/W) 的效率。
实时边缘人工智能面临的挑战
随着基础模型增长到数十亿个参数,数据中心基础设施的成本和能源足迹急剧上升。然而,对数据源实时、低延迟推理的需求仍然比以往任何时候都强烈。因此,边缘人工智能必须超越原始计算密度,并解决有限功率预算和严格成本目标的双重限制。
实际上,这意味着平衡原始吞吐量 (TOPS) 与内存带宽和延迟。 GPU 等现代加速器可提供前所未有的计算能力,但其性能受到数据传入和传出内存的速度的限制。内存瓶颈会影响加速器,从而抵消了更高计算能力的好处。
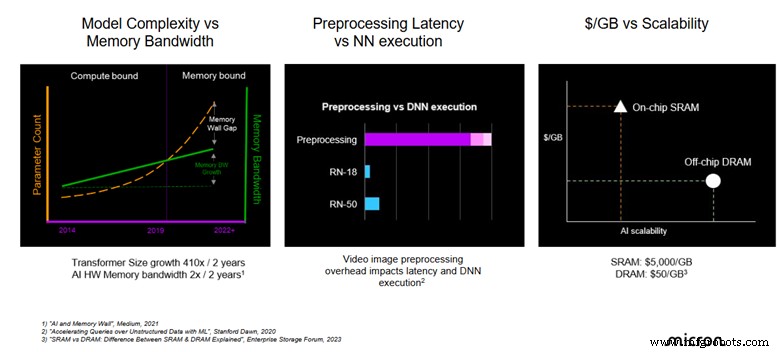
内存带宽限制已成为嵌入式边缘 AI 中最重要的性能限制因素。即使模型变得越来越复杂,缓慢的内存路径也会削弱实时推理。
推理是一个管道,从原始传感器数据开始,经过预处理,提供量化的神经网络,并以提供可操作结果的后处理结束。如果这条链中的任何环节薄弱——无论是低带宽内存总线还是缓慢的预处理例程——整个系统都会受到影响。
此外,在片上系统 (SoC) 设计中添加神经处理单元 (NPU) 或加速器内核可能会增加物料清单并降低灵活性。该解决方案在于专用 ASIC 加速器,将高 TOPS/W 与紧凑、低功耗内存接口结合起来。
专用 ASIC 具有多种优势:它们针对神经网络的算术模式进行了优化,可以针对各种模型进行调整,并且为边缘部署提供尽可能最佳的能源效率 - 无论是自主农场机器、监控摄像头还是仓库机器人。
计算和内存的协同
与边缘平台无缝集成的协处理器可实现实时深度学习推理,同时保持较低的功耗和成本。它们支持多种工作负载,从视觉转换器到大型语言模型。
Hailo 之间的合作伙伴关系就是这种协同作用的最佳例证 的边缘人工智能加速器和美光 的低功耗 DDR (LPDDR) 内存。它们共同提供了保持在严格的能源和预算范围内所需的平衡计算内存组合。
美光的 LPDDR 技术可提供高速、高带宽数据传输,且不会影响功效。 LPDDR 用于智能手机、笔记本电脑、汽车电子和工业控制,非常适合需要快速 I/O 和低延迟的 AI 工作负载。
LPDDR4/4X 每个引脚支持高达 4.2Gb/s,总线宽度高达 x64。美光的 LPDDR5/5X 将每个引脚的速度提升至 9.6Gb/s,并且能效比 LPDDR4X 高出 20%,从而提供最苛刻的边缘 AI 模型所需的带宽。
Hailo 是人工智能芯片领域的领导者,利用这种内存合作伙伴关系来提供 Hailo‑10H 等处理器 ,最高可达 40TOPS。其数据流架构与神经网络的统计特性相一致,使边缘设备能够全面运行复杂的模型,同时保持较低的成本。
让解决方案发挥作用

Hailo‑15 VPU SoC 专为智能相机和视觉密集型应用量身定制。它将 Hailo 的推理引擎与先进的计算机视觉管道结合在一起,在一个节能的软件包中提供优质的图像质量和复杂的视频分析。

美光的 LPDDR4X 在汽车、工业和企业环境中经过严格测试,与 Hailo‑15 VPU 完美搭配。其结果是即使在极端温度范围内,解决方案也能提供高带宽、低延迟和不妥协的电源效率。
获胜组合
随着生态系统的发展,开发人员必须将数百万甚至数十亿设备重新构想为完全自主的边缘人工智能平台。成功取决于从头开始构建的可加速神经工作负载的处理器,以及保持数据平稳传输的低功耗、高性能内存。
当处理器和内存一起优化时,边缘人工智能可以扩展到新的应用程序,从自主农业设备到实时视频监控和机器人。
赞助文章
通过 X 评论本文:@IoTNow_ 并访问我们的主页 IoT Now
物联网技术