

面向初学者的机器学习及其四种主要类型的重点说明
毫无疑问,大数据是未来科技发展的重要组成部分。然而,机器学习 (ML) 和人工智能 (A.I) 在这一发展中都发挥着重要作用。简述这三者的关系:大数据为材料,机器学习为方法,人工智能为结果。
什么是机器学习?
机器学习 (ML) 是人工智能 (A.I) 的一种类型,其中算法的编写方式使得系统能够通过经验自动学习、适应和改进,而无需明确编程.
机器学习算法根据目标学习的数据类型构建了一个示例模型,这种类型的数据称为“训练数据”。
机器学习的类型?
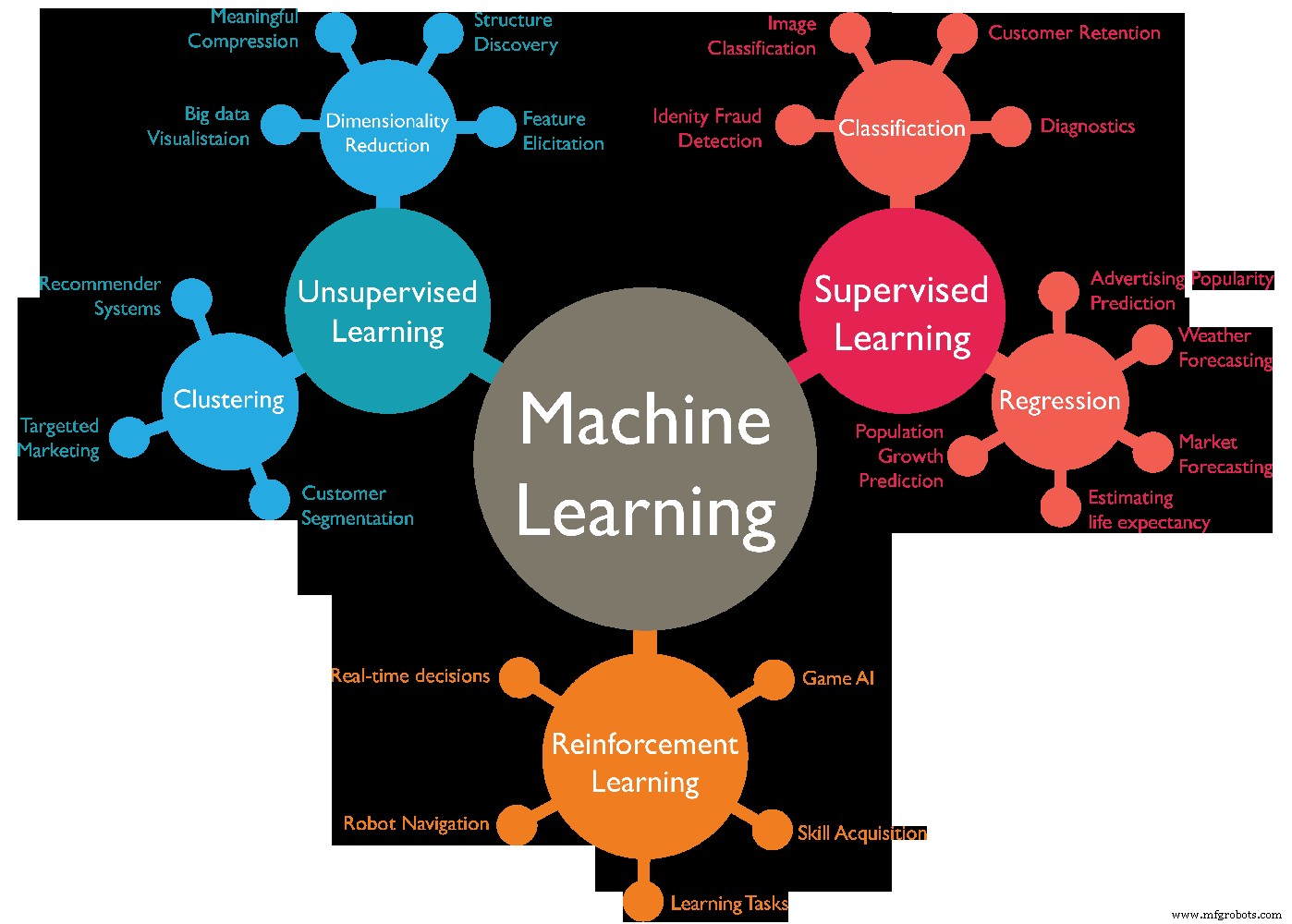
机器学习算法有很多种,一般可以分为4大类,不同类型的机器学习如下:-
- 监督学习.
- 无监督学习.
- 半监督学习。
- 强化学习。
监督学习
当机器在“学习”阶段被监督时,这种类型的训练称为监督学习。当我们说一台机器被监督时,我们真正的意思是什么? ?.以允许机器学习使用其旧数据(过去提供的数据)并使用它来预测围绕输入的数据类型(即旧数据)的未来事件的方式应用算法的真正含义。
分析开始,训练数据集中的所有材料和标记都与机器相关,从而可以预测正确的输出值。这意味着我们向机器提供有关特定案例的大量信息,然后它提供案例结果。结果称为标记数据,而其余信息用作输入特征。然后,系统还可以在充分训练后为新的输入提供目标。该算法可以将其输出与预期输出进行比较,并找到差异以相应地更改模型。
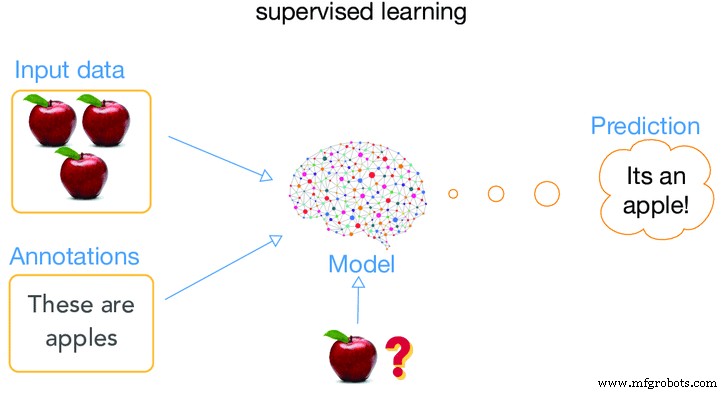
图片来自人工智能.oodles.io/
这种方法多半是人工分类,对电脑来说最容易,对人来说最难。这种方法的一个例子是,告诉机器标准答案,当机器被测试时,机器总是按照标准答案来回答,因此它的可靠性也会更大。
无监督学习
与监督学习相反,当用于训练机器的信息既没有分类也没有标记时,使用无监督学习算法,正如无监督学习中的名称所暗示的那样,用户不会向计算机提供帮助来帮助它会学习。
提供的材料没有标签,机器匹配数据的特性,对材料进行分类。由于缺乏标记的训练集,机器会识别出数据中对人类来说不太明显的模式。
图片来自 data-flair.training/在这种方法中,没有任何手动分类,这对人类来说是最容易的,但对计算机来说最难,而且会导致更多的错误。该系统通常不会计算出预期的输出,但它会研究提供的数据,并可以从数据集中提取关系以描述未标记数据中的隐藏结构。因此,在无监督学习中识别数据模式非常有用,也有助于我们做出决策。
半监督学习
半监督学习不同于监督学习和无监督学习,其中要么没有标签用于所有数据的观察,要么存在标签。
在半监督中,标记(监督)和未标记(非监督)数据都用于训练。 SSL 混合了两种类型的学习,其中少量数据被标记,大量数据未被标记。机器需要通过标记数据找到特征,然后使用基本模型对其他数据进行相应的分类。 SSL 系统不仅可以显着提高其学习准确性,还可以做出更准确的预测。
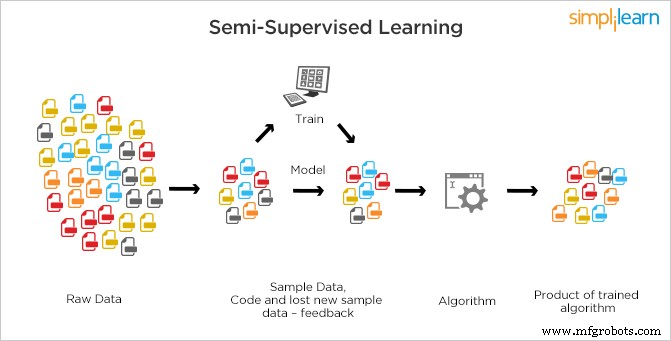
这是最常用的方法,因为标记成本很高,因为需要熟练的人类专家。它需要相关资源来训练它并从中学习,而获取未标记的数据通常不需要额外的资源。由于在大多数观察中缺乏标签,但存在少数,半监督算法是构建模型的最佳候选者。
这些方法受益于这样的想法:即使组成员是未知的,因为未标记的数据更普遍,但有关参数的信息仍然携带在标记中并且可以使用它找到。
强化学习
强化学习最接近我们人类的学习方式。 RML 算法是一种学习方法,其中机器通过构建新动作并发现错误或奖励来反复与其环境交互。它使用基于正面或负面奖励的系统。
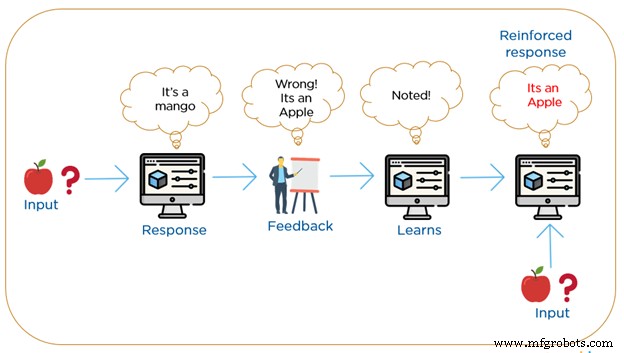
具有延迟奖励的试错搜索是强化学习最相关的特征。机器使用从与环境交互中收集的观察结果来构建行为,并采取行动来最大化回报或最小化风险。这种方法允许机器自动确定特定上下文中的理想行为以提高其性能。在强化学习中,没有标记材料,而是需要简单的反馈,即哪一步是正确的,哪一步是错误的,这就是强化信号。

机器根据反馈的标准,逐步修正自己的分类,直到最终得到正确的结果。为了在无监督学习中达到一定水平的精度,强化学习的整合是必要的,
RML 可能是在商业环境中最难生产和执行的,但它通常用于自动驾驶汽车。
工业技术