

PLCnext 上的机器学习
到目前为止,每个人都听说过机器学习以及它将如何改变一切。但很少有人知道如何开始改变一切。我希望当您尝试本博客中的步骤,或者甚至阅读它时,将帮助您了解如何开始使用 PLCnext 控制器进行更改。在这篇博客中,我将训练您的第一个 ML 模型,将其转换为 ONNX 标准,并在 PLCnext 控制器上推断模型。为了不让事情变得不堪重负,我将使用著名的 Iris 数据集来构建我们的模型。
在开始之前,应该非常清楚我们将要达到的目标。因此,我将对本博客中处理的主题进行简单的解释。我的参考资料可以在这篇博客的末尾找到。
机器学习简介
什么是机器学习
所以,我想我们应该从解释什么是机器学习开始。机器学习的本质是我们将尝试使用统计数据和算法在数据集中找到模式。我们区分了三种主要的机器学习类型:监督机器学习、无监督机器学习和强化学习。监督学习是当今最常用的“风格”,我们将在本博客中使用监督学习。在监督学习中,我们标记数据并告诉机器我们正在寻找什么模式。
在无监督学习中,我们不对数据进行标记,而是让机器自行寻找模式,因为这种技术的应用不太明显,因此无监督学习不太受欢迎。
最后,在强化学习中,算法通过反复试验来学习以实现既定目标。它只是尝试了很多事情并获得奖励或惩罚,具体取决于它是好是坏。谷歌的 AlphaGo 是强化学习的一个著名例子。
鸢尾花数据集
根据维基百科,鸢尾花数据集是:
好的,很好,但是看起来怎么样?
在 Iris 数据集中有 5 个字段:萼片长度、萼片宽度、花瓣长度、花瓣宽度和鸢尾花的品种。我们今天的目标是在知道萼片长度、萼片宽度、花瓣长度和花瓣宽度的情况下找到鸢尾花的类型。所以我们将训练模型对花的类型进行分类。正如您可能已经猜到的那样,这种类型的机器学习就是分类。
机器学习也可用于预测数据集中的值。这是一个名为回归的过程,使用的算法与分类不同。
算法
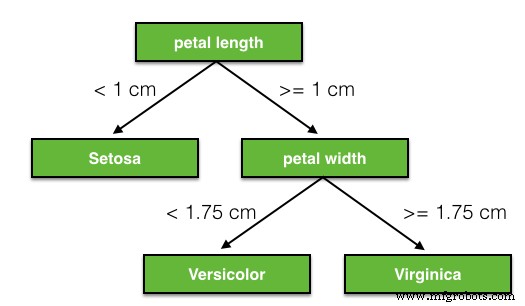
今天我们将使用“决策树分类器”,不是因为它非常适合这项任务,而是它非常直观,无需花哨的数学就可以轻松理解。在这里您可以找到我们鸢尾花数据集的决策树示例。
ONNX
可以想象,机器学习模型可以有多种格式,并且需要在具有不同加速方法的许多不同硬件上运行。开放神经网络交换试图缓解这个问题。它被用于开放式办公室、天蓝色和世界各地的无数其他应用程序。它几乎肯定会在您正在阅读此博客的设备上使用。
要运行 onnx 模型,我们需要 onnx 运行时,这带来了挑战。特别是在 arm 处理器上,但是使用提供的 docker 图像,你应该没问题!
技术演练
先决条件
我正在使用安装了固件 2021.0 LTS 的 AXC F 2152 控制器和 Ubuntu 20.04 VM 来训练模型。提供了用于训练和推断模型的脚本,但 Ubuntu VM 的设置超出了博客的范围。您可以找到有关如何安装所需 Python 包的很好的解释,并且所有使用的包都应使用 pip3 正确安装。
在 PLCnext 控制器上,我们需要安装一个容器引擎。您可以在此处找到该过程的详细说明。
AXC F 3152 也可以进行类似的操作。
对于此博客,您至少需要具备最低限度的 Python 和容器经验。
训练模型
下载此 GitHub 存储库的内容并确保已安装所有必要的包。
我们要运行的第一个脚本是训练脚本,我们要将模型拟合到 iris 数据集。
您可以在下面找到从该培训脚本中截取的代码。该脚本将创建一个“.onnx”文件,其中包含经过训练的模型。
# Slit the dataset in a training and testing dataset
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, Y_test = train_test_split(X, y)
# Define the model and fit the model with training data and print information about the model
clr = DecisionTreeClassifier()
clr.fit(X_train, y_train)
print(clr)
#Convert the model from sklearn format to ONNX (Open Neural Network Exchange)
initial_type = [('float_input', FloatTensorType([None, 4]))]
onx = convert_sklearn(clr, initial_types=initial_type)
with open("decision_tree_iris.onnx", "wb") as f:
f.write(onx.SerializeToString())
在 Ubuntu 上进行推理
通过在您的开发机器上运行它来检查您的模型。当你运行推理脚本时,你应该得到对应于鸢尾花类型的 2 个整数。
import numpy as np
import onnxruntime as rt
X_test = np.array([[5.8,4.0,1.2,0.2],[7.7,3.8,6.7,2.2,]])
sess = rt.InferenceSession("decision_tree_iris.onnx")
input_name = sess.get_inputs()[0].name
label_name = sess.get_outputs()[0].name
pred_onx = sess.run(
[label_name], {input_name: X_test.astype(np.float32)})[0]
print(pred_onx)
output : [0 2]
PLCnext 上的推理
打开您最喜欢的 sFTP 客户端,然后将“.onnx”和“inference.py”存储库放在您的 PLCnext 控制器上的 /opt/plcnext/onnx 中。以 root 身份继续执行下一个命令:
balena-engine run -it --name onnx -v /opt/plcnext/onnx/:/app pxcbe/onnx-runtime-arm32v7
使用
运行python推理脚本cd /app
python3 /app/inference.py
如果一切顺利,您将获得与 Ubuntu VM 上的推理相同的输出!恭喜你,你已经坚持到最后了。现在去改变吧!
如何在应用中实现?
实际上,我们还没有完成。我的意思是,对鸢尾花进行分类很有趣,但我无法想象它在逻辑控制器上的多个应用程序。您需要提出自己的模型并为该模型创建一个 API,以便您可以使用它进行推理。您可以选择使用 OPC UA 将数据传送到模型或为其构建自定义 REST 端点。无论如何,您需要编写比我提供的更多的代码。
考虑到构建图像花了我几天和一个不眠之夜,我建议您在提供的图像之上构建图像。在参考中,您可以找到构建 Python 容器应用程序的好资源。
参考资料:
https://www.technologyreview.com/2018/11/17/103781/what-is-machine-learning-we-drew-you-another-flowchart/https://en.wikipedia.org/wiki/Iris_flower_data_set请接受营销 cookie 以观看此视频。
https://www.researchgate.net/figure/Decision-tree-for-Iris-dataset_fig1_293194222https://onnx.ai/
https://github.com/PLCnext/Docker_GettingStarted
https://www.wintellect.com/containerize-python-app-5-minutes/
工业技术