

为 TinyML 设备设计的 Arm core
Arm 推出了两个新的 IP 核,旨在为端点设备、物联网设备和其他低功耗、成本敏感的应用中的机器学习提供动力。 Cortex-M55 微控制器内核率先使用 Arm 的 Helium 矢量处理技术,而 Ethos-U55 机器学习加速器是该公司现有 Ethos NPU(神经处理单元)系列的微型版本。两个内核设计为一起使用,但也可以单独使用。
在微控制器和其他成本敏感、低功耗资源受限的设备上启用 AI 和机器学习应用程序被称为 tinyML 领域。随着 5G 的兴起引发了终端设备更加智能的趋势,tinyML 预计将呈指数级增长,成为一个包含数十亿消费者和工业系统的市场。
Arm 物联网和嵌入式高级总监 Thomas Ensergueix 表示:“当我们从现在回顾五年后,我们可能都同意,这一次标志着计算领域真正的范式变革。” “几年之内,我们已经看到人工智能如何彻底改变了数据分析在云中的运行方式,我们大多数人的口袋里都有一部人工智能增强的智能手机,现在是下一步,为无处不在的人工智能做好准备。”

智能音箱等智能家居设备将越来越能够自行执行机器学习推理(图片来源:Sebastian Scholz/Unsplash)
机器学习,包括语音识别和计算机视觉应用,将越来越多地发生在微控制器中。一系列基于 Arm 内核和其他内核的微控制器替代品正在涌现,Arm 以这两个新内核为目标。
“我们知道端点级别的所有这些数据都无法返回到云端,”Ensergueix 说。 “家庭或智能城市中的摄像机每天会产生数千兆字节的数据,而基础设施并不是为这种上游数据流而构建的。我们坚信,我们需要扩展到数十亿或数万亿个 IoT 端点,我们将需要直接在 IoT 端点中使用 AI 推理能力。而且它需要是安全的。”
皮质-M55
作为 Arm 著名的 Cortex-M 系列微控制器的最新成员,Cortex M-55 旨在成为 Arm 最具有 AI 功能的 Cortex-M 内核。
M55 率先使用 Arm 的全新 Helium 矢量处理技术,与前几代 Cortex-M 相比,该技术有望将 DSP 性能提高 5 倍,ML 性能提高 15 倍。基于 Armv8.1-M 架构,可以创建自定义指令来针对特定工作负载优化处理器,或许可以挤出每一滴电源。
M55 和 U55 的结合利用了 M55 增加的 DSP 马力,可用于信号预处理。但是,M55 可以自行运行神经网络工作负载。它具有 INT8 数字的专用指令,包括机器学习应用中常用的点积。
一个成功的 AIoT 应用“不仅取决于良好的计算性能,还取决于能够在正确的时间获得正确的数据、正确的系数和正确的机器学习权重,因此处理器的内存接口已经过优化,能够处理所有进出数据。在这方面,它比任何其他 Cortex-M 内核都更有能力,”Ensergueix 说。
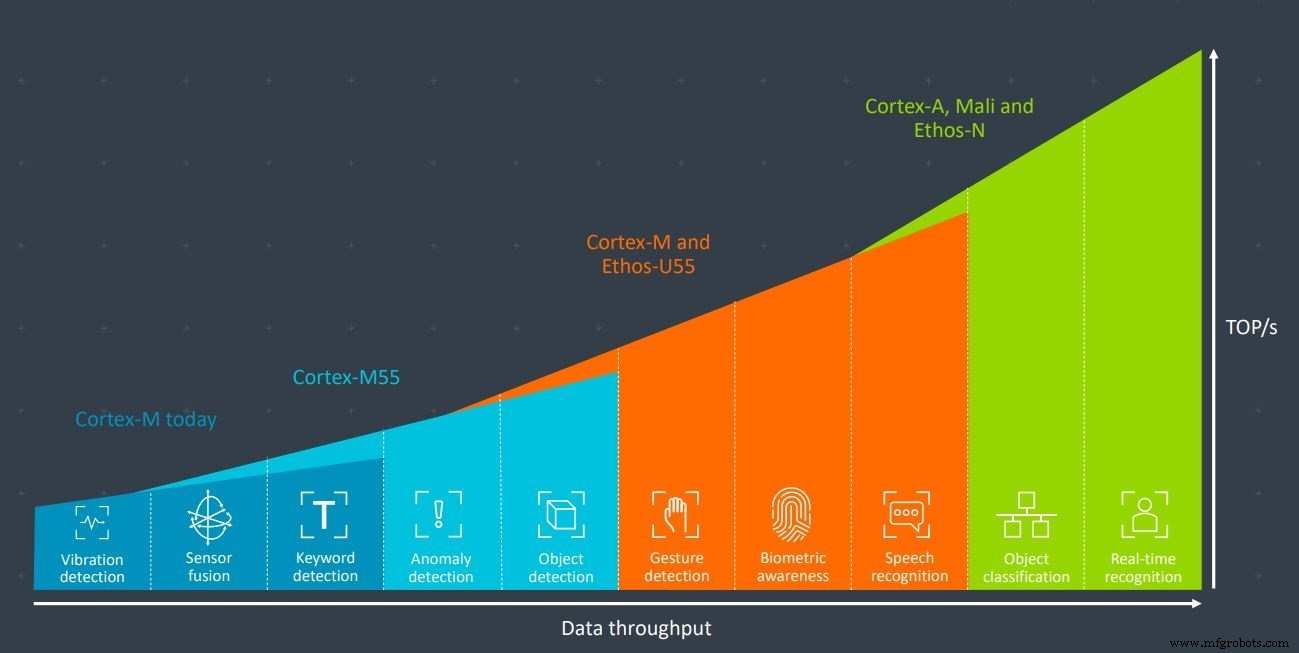
Cortex-M55 和 Ethos-U55 的组合为手势识别、生物识别和语音识别等应用提供了足够的处理能力(图片:Arm)
Ethos-U55
Ethos-U55 被称为 Arm 的第一款“微型 NPU”,可提供高达 0.5 TOPS 的加速度(基于较小的几何形状,例如 16 或 7 nm,运行频率为 1 GHz)。 Arm 尚未发布电源效率数据 (TOPS/W)。它是可配置的——可以使用 32 到 256 个乘法累加单元 (MAC)——它有一个权重解码器和用于即时权重解压缩的直接内存访问。
Ethos-U55 加入了 Ethos N77、N57 和 N37,相比之下,它们分别提供 4、2 和 1 个 TOPS。可以通过使用多个 Ethos 内核来提升性能。
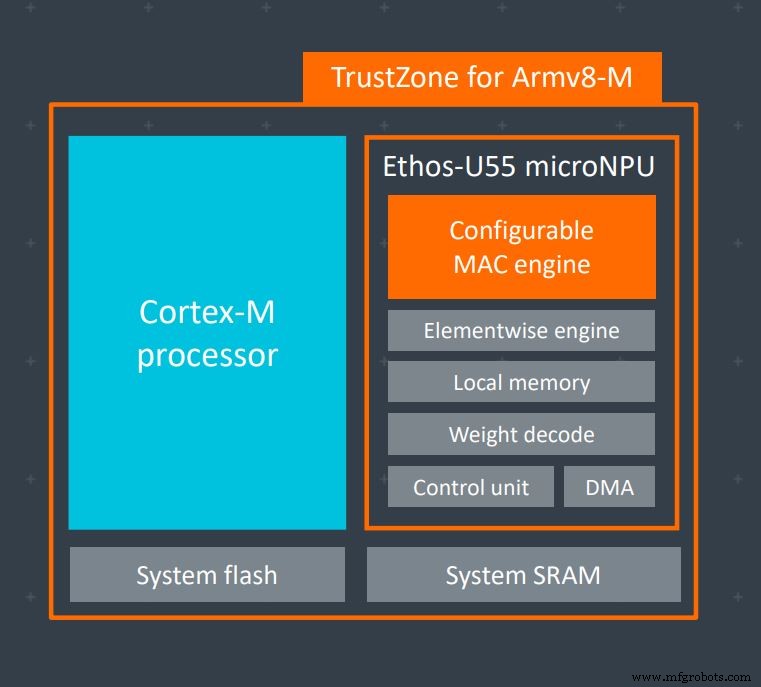
Cortex-M55 和 Ethos-U55 旨在一起使用,但也可以单独使用(图片:Arm)
这两个新内核 M55 和 U55 旨在一起使用,它们处理 ML 任务的速度比单独的任何上一代 Cortex-M 设备快 480 倍。 Arm 表示,与单独使用 Cortex-M7 相比,使用 ML 的端到端语音助手应用程序的典型数据速度提高了 50 倍,能效提高了 25 倍。
“Cortex-M 将运行应用系统代码,然后当需要处理神经网络工作负载时,将其命令流放置在 SRAM 中,向 U55 发出中断,然后它说,在这里,继续工作命令流,”Arm 机器学习小组副总裁 Steve Roddy 解释说。 “这可能是对单一模型的单一推断。 U55 运行完成,将结果放回 SRAM,然后让 Cortex-M 接管。或者可能是在您对流数据(可能是音频或视频)进行某种处理时连续运行的情况。”
基于这些新内核的硅芯片应该会在 2021 年初上市。
嵌入式