

初创公司将 1000 个 RISC-V 内核装入 AI 加速器芯片
该初创公司的节能芯片针对 M.2用于加速数据中心推荐模型的加速器套接字。
恰逢 Hot Chips 大会,初创公司 Esperanto 本周从隐身模式中脱颖而出,推出了迄今为止性能最高的商用 RISC-V 芯片——专为超大规模数据中心设计的千核 AI 加速器。虽然该芯片可以在 10 到 60 W 之间的多种电压和功率配置文件中运行,但其“最佳点”是每个芯片的功率为 20 W,这种配置允许在 Glacier Point 加速器卡上安装六个芯片,保持总功耗低于 120 W。六颗芯片的总性能约为 800 TOPS。
Esperanto 的 ET-SoC-1 号称在单个芯片上拥有最多的 RISC-V 内核:1,093。计数包括 1,088 个 ET-Minion 定制 RISC-V 内核,用作节能 AI 加速引擎。还包括四个 ET-Maxion RISC-V 内核和一个 RISC-V 服务处理器。整个设计面向能源效率。
领先于热门芯片, EE Times 与行业资深人士 Dave Ditzel 进行了交谈,他是世界语的创始人兼执行主席。 (Ditzel 的凭据包括与 David Patterson 共同撰写了 1980 年发表的开创性论文“精简指令集计算机的案例”。)

Dave Ditzel(来源:世界语)
“我们是第一个在单个芯片上放置一千个 RISC-V 内核的公司,”Ditzel 说。 “多年来人们一直在谈论多核 CPU,但我们还没有看到很多。大多数 RISC-V 的东西都是用于嵌入式的。
“我们说,‘让我们向他们展示 RISC-V 可以做高端......我们将向他们展示真正经验丰富的 CPU 设计师可以在这里做什么’。”
客户要求
Ditzel 的 CPU 设计团队能够从超大规模数据中心运营商那里了解他们的需求细节。
“他们不想要训练芯片,他们在训练方面没有问题,”Ditzel 说。 AI 训练通常是一个离线问题,超大规模者的巨大 x86 CPU 容量并不总是处于峰值负载。因此,该容量可在可用时用于培训。 “他们真正的问题是推理,”Ditzel 补充道。 “这就是推动他们做广告的原因。他们需要在 10 毫秒或更短的时间内得到答复。”
因此,加速在线广告的推荐推理引擎成为数据中心芯片的重点。超大规模者对加速此类模型的要求非常明确。
“我们的客户需要 100 兆字节的片上内存——他们想用推理做的所有事情都适合 100 兆字节,”他说。客户还需要一个用于片外存储器的外部接口。 “真正的问题是您可以在加速卡上容纳多少,”Ditzel 解释说。 “将卡视为计算单位,而不是芯片。一旦您可以在卡上获得内存,您就可以比通过 PCIe 总线访问主机更快地访问内容。”
点击查看全尺寸图片

Esperanto 将六张双 M.2 卡安装到 Glacier Point 加速器卡上,每张卡带有一个芯片。 (来源:世界语)
片上存储器系统具有 L1、L2 和 L3 缓存以及一个完整的主存储器系统,其寄存器文件的总大小刚超过 100 MB。卡上存储系统可以在 100 GB 左右保存模型中的大部分权重和激活。
众所周知,推荐模型难以加速,这也是它们仍在现有 CPU 服务器上运行的原因之一。
“当你从 1 亿客户中挑选他们最近购买的东西时,你必须访问这个......卡上的内存,并且你正在执行各种随机内存访问,所以缓存不会工作。你真的需要更多的经典电脑,”Ditzel 说。 “x86 服务器处理大量内存,它们具有预取功能,通用 CPU 可以很好地处理该工作负载。因此,任何加速器都很难涉足推荐业务。”
还需要支持 INT8 以及 FP16 和 FP32 数据类型。对浮点数学的要求源于保持尽可能高的预测精度的需要,以及不倾向于移植或重写程序以实现较低精度的数学。 Ditzel 表示,领先的 x86 服务器芯片制造商最近才为服务器 CPU 添加了 8 位矢量扩展。
“在 [超大规模数据中心] 的数百万 x86 服务器上进行的大部分推理仍然是 32 位浮点数,”他说。
双 M.2 卡上的世界语芯片旨在装入现有 x86 CPU 服务器基础架构中的加速器插槽。这导致功率限制为 120 W,需要空气冷却。
Ditzel 表示,世界语的设计并不直接与谷歌 TPU 或亚马逊网络服务的 Inferentia 等内部努力竞争。超大规模者“正试图让整个社区为他们构建加速器芯片。这些公司中有很多都相信开放计算和 [开放计算项目]。”因此,“他们购买 OCP 服务器,并且希望将标准化的东西放入其中。如果有竞争,他们就会喜欢它……他们正在努力鼓励竞争并向人们展示什么是可能的。”
尽管如此,这家初创公司坚持认为大数据中心运营商需要外部供应商来提供加速器芯片。 “它仍然总是一个制造与购买的决定。”例如,一位世界语客户无法获得另一个部门使用的内部开发芯片。 “如果你打败了他们,就可以进入这些公司中的任何一家。”
新方法
Esperanto 采取了与竞争对手巨大的耗电芯片加速器相反的方法,提供了一种可以多次使用的低功耗芯片。该方法解决了内存带宽要求,因为可以将更多引脚用于内存 I/O,而无需求助于昂贵的 HBM。
世界语的硬件也被设计为通用计算机; Ditzel 表示,尽管专注于推荐模型,但该芯片可以加速并行处理。一张六片加速卡大约有6000个并行内核,每个内核可以执行两个线程,可以“任意抛”。
世界语袖子的另一个技巧是积极的节能设计。客户要求将总功率预算设置为 120 W,而 Glacier Point 卡上的最大空间为 6 个芯片,即每个芯片 20 W。相比之下,人工智能推理加速器的运行速度是这个数量的十倍以上。
世界语从几个角度解决了这个问题。时钟频率降低到大约 1 GHz 的最佳水平。电源电压降至 0.4 V 左右,超出了 SRAM 的限制。通过使用具有最小商业可行性指令集的精益 RISC-V 内核来减少晶体管数量,有助于开关电容。选择了先进但稳定的工艺技术,台积电7nm。
点击查看全尺寸图片
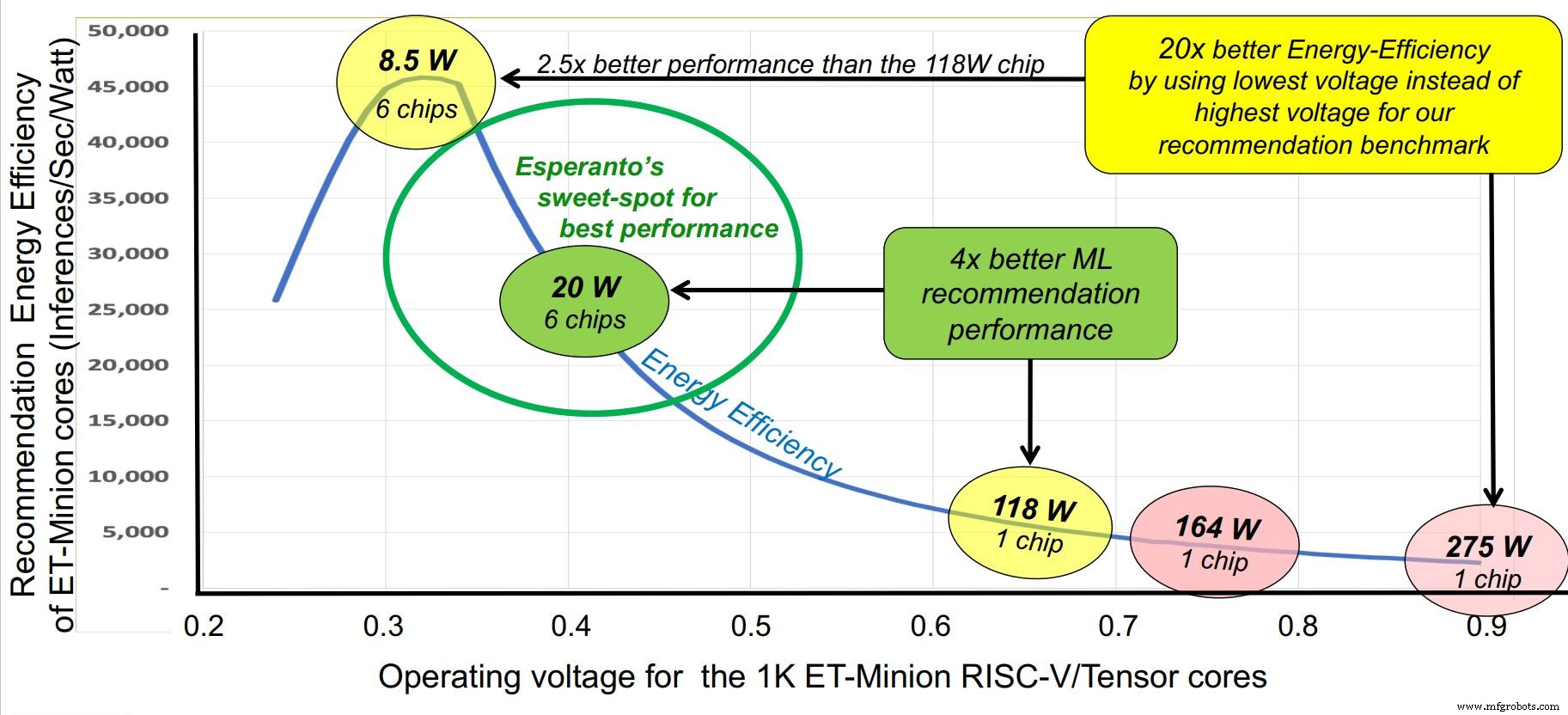
世界语确定了在 1 GHz 左右运行的“最佳位置”。 (来源:世界语)
核心设计
Esperanto 的芯片包括 1,088 个 ET-Minion 内核,用于处理 AI 工作负载。核心是 64 位有序 RISC-V 处理器,世界语自己的 AI 优化矢量和张量单元占据了大部分芯片空间。浮点 MAC 在配置中占主导地位。不同寻常的是,整数 MAC 的处理宽度是浮点数的两倍(根据客户要求,Ditzel 指出)。还支持向量超越指令,例如深度学习模型中常见的 sigmoid 函数。由于内核在单个低电压域中运行,因此在小型 L1 缓存中使用更多晶体管与 SRAM 以确保稳健的性能。
点击查看全尺寸图片
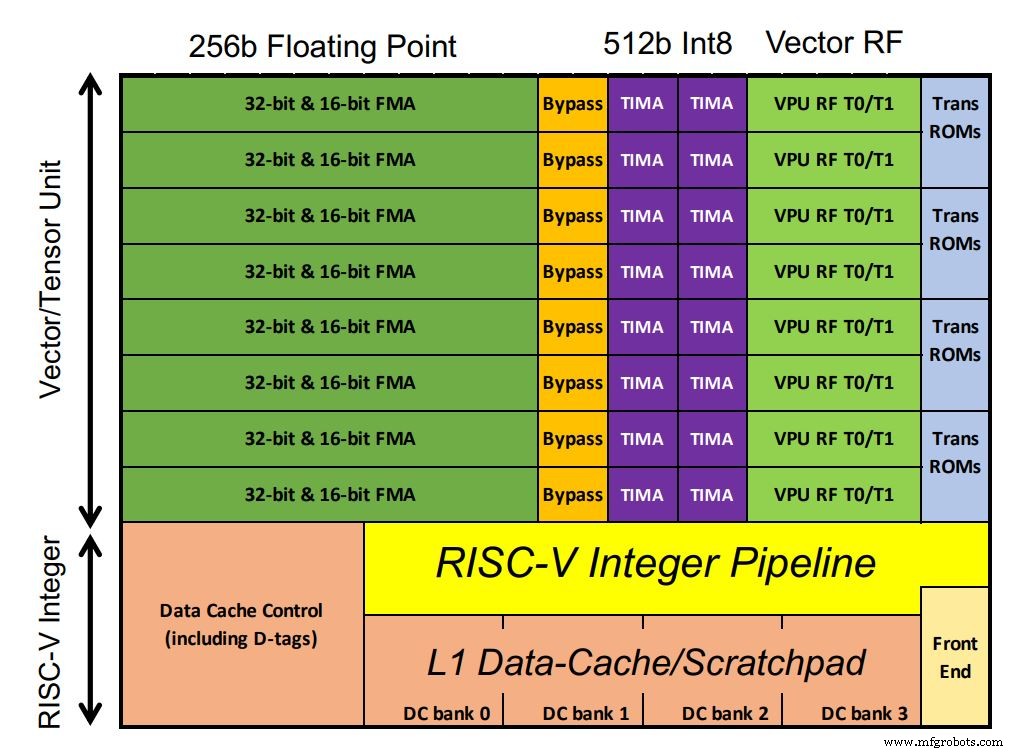
Esperanto 的芯片包含 1,088 个 ET-Minion 内核(点击图片放大)(来源:世界语)
每个内核能够达到 128 GOPS/GHz。自定义多周期张量指令执行大型矩阵乘法,由一个单独的控制器接管并使用完整的 512 位宽度运行多达 512 个周期。这允许单个张量指令在控制器获取下一条 RISC-V 指令之前执行超过 64,000 次算术运算。这减少了指令带宽,因为大部分工作负载使用张量指令。因此,每512个时钟周期只需要一条指令。
八个 ET-Minion 核心构成了一个“邻居”,修改后的指令利用了它们的物理接近性。另一个称为“协同加载”的功能允许内核直接相互传输数据,而无需缓存提取。这种配置可以节省电力。八个内核还共享一个大型 L2 缓存以提高能效。
再次缩小,四个 8 核邻域构成了一个“Minion Shire”,每个芯片上有 34 个郡,总共 1,088 个内核。 (Ditzel 说,也可以仅使用 1,024 个内核进行计算以提高产量)。四个 ET-Maxion 内核,每个内核的性能与 Arm A-72 大致相当,旨在用于未来的独立操作,而不是当前的加速器配置。
通过为每个 Shire 提供自己的电压源,从而可以对各个电压进行微调,从而减轻阈值电压变化。
内存系统
每个芯片有四个 64 位 DDR 接口——实际上,每个接口代表四个 16 位通道——总共 96 个 16 位通道。该设计使用为智能手机开发的低功耗内存 LPDDR4x。每比特能量大致相当于 HBM,但将六芯片加速卡的整个内存接口的总能量保持在 1,536 位会产生更高的总内存带宽。
世界语将其芯片安装在双插槽 M.2 卡上;六个适合 OCP Glacier Point v2 加速器卡(三个正面,三个背面)。以 1 GHz 运行的芯片可提供大约 800 TOPS。它们还可以安装在薄型(半高、半长)PCIe 卡上,从而将每个芯片的功率预算增加到 60 W 左右。这些芯片可以在 300 MHz 到 2 GHz 之间运行,具体取决于应用。
根据硬件仿真结果,Ditzel 断言 Glacier Point 卡上的六个世界语芯片可以胜过竞争对手。当考虑内存系统设计和每瓦性能数据时,这家初创公司在推荐基准测试中的优势非常明显,这是专注于低电压设计的结果。
未来的版本可能包括用于边缘应用的 ET-SoC-1 的缩小版本。 Ditzel 表示当前版本应该会在“未来几个月内”推出。
>> 本文最初发表在我们的姊妹网站 EE次。
相关内容:
- 支持 AI 的 SoC 可处理多个视频流
- Xilinx 旨在通过“可组合”硬件实现数据中心卸载
- 减少 NNA 功能覆盖的操作集计算 (ROSC)
- 混合架构可加速 AI、视觉工作负载
- 硬件加速器为 AI 应用服务
有关 Embedded 的更多信息,请订阅 Embedded 的每周电子邮件通讯。
嵌入式