

广泛的信号处理链如何让语音助手“正常工作”
智能音箱和声控设备越来越受欢迎,亚马逊的 Alexa 和谷歌的助手等语音助手越来越能理解我们的要求。
这种界面的主要吸引力之一是它“很好用”——没有用户界面可以学习,我们可以越来越多地用自然语言与小工具交谈,就好像它是一个人一样,并得到有用的回应。但要实现这种能力,需要进行大量复杂的处理。
在本文中,我们将着眼于语音控制解决方案的架构,并讨论幕后发生的事情以及所需的硬件和软件。
信号流和架构
声控设备虽然种类繁多,但基本原理和信号流程大同小异。让我们考虑一个智能音箱,比如亚马逊的 Echo,看看所涉及的主要信号处理子系统和模块。
图 1 显示了智能音箱中的整体信号链。
点击查看大图
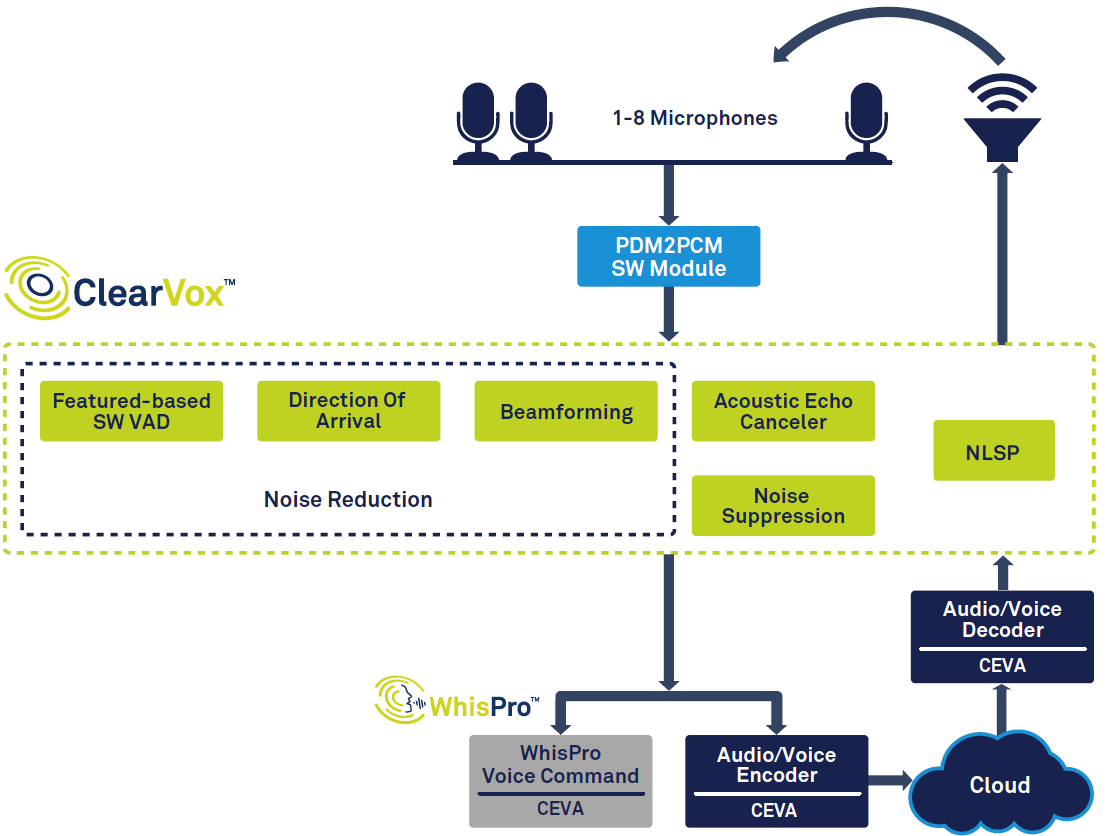
图 1:语音助手的信号链,基于 CEVA 的 ClearVox 和 WhisPro。 (来源:CEVA)
从图的左侧开始,您可以看到,一旦使用语音活动检测 (VAD) 检测到语音,就会对其进行数字化,并通过多个信号处理阶段,以提高所需主说话人语音的清晰度到达方向。然后将经过数字化处理的语音数据传递到后端语音处理,这可能部分发生在边缘(在设备上),部分发生在云中。最后,如果需要,扬声器会创建并输出响应,这需要解码和数模转换。
对于其他应用,可能存在一些差异和不同的优先级——例如,需要优化车载语音接口以处理汽车中的典型背景噪音。在对更小的设备(如入耳式“耳戴式设备”和低成本家用电器)的需求推动下,降低功耗和降低成本也是一个总体趋势。
前端信号处理
一旦检测到语音并将其数字化,就需要执行多项信号处理任务。除了外部噪音,我们还需要考虑听音设备产生的声音,例如输出音乐的智能扬声器或与线路另一端说话的人的对话。为了抑制这些声音,该设备使用了声学回声消除 (AEC),因此用户可以插入和打断智能扬声器,即使它已经在播放音乐或说话。一旦这些回声被去除,噪声抑制算法就会被用来清除外部噪声。
虽然有许多不同的应用,但我们可以将它们概括为语音控制设备的两组:近场和远场拾音。耳麦、耳塞、耳戴式设备和可穿戴设备等近场设备靠近用户的嘴边持有或佩戴,而智能扬声器和电视等远场设备则设计用于从房间的另一端聆听用户的声音。
近场设备通常使用一个或两个麦克风,但远场设备通常使用三到八个麦克风。原因是远场设备比近场设备面临更多挑战:随着用户移得更远,他们到达麦克风的声音逐渐变得更安静,而背景噪音保持在同一水平。同时,该设备还必须从墙壁和其他表面的反射(即混响)中分离出直接语音信号。
为了解决这些问题,远场设备采用了一种称为波束成形的技术。这使用多个麦克风,并根据到达每个麦克风的声音信号之间的时间差来计算声源的方向。这使设备能够忽略反射和其他声音,而只听用户——以及跟踪他们的动作,并在多人交谈时放大正确的声音。
对于智能音箱,另一个关键任务是识别“触发”词,例如“Alexa”。由于说话者一直在听,这种触发识别会引发隐私问题——如果用户的音频总是被上传到云端,即使他们没有说出触发词,他们是否对亚马逊或谷歌听到他们所有的谈话感到舒服?相反,最好在智能扬声器本身本地处理触发器识别以及许多流行的命令,例如“调高音量”,只有在用户启动更复杂的命令后才会将音频发送到云端。
最后,干净的语音样本必须经过编码才能最终发送到云端后端进行进一步处理。
专业解决方案
从上面的描述中可以清楚地看出,前端语音处理必须能够处理很多任务。它必须快速准确地做到这一点,对于电池供电的设备,必须将功耗保持在最低水平——即使设备一直在侦听触发词。
为了满足这些需求,通用数字信号处理器 (DSP) 或微处理器在成本、处理性能、尺寸和功耗方面不太可能胜任。相反,更好的解决方案可能是具有专用音频处理功能和优化软件的专用 DSP。选择已经针对语音输入任务进行优化的硬件/软件解决方案还可以降低开发成本并大幅缩短上市时间,并降低总体成本。
例如,CEVA 的 ClearVox 是一套语音输入处理算法软件套件,可以应对不同的声学场景和麦克风配置,包括扬声器的语音到达方向、多麦克风波束成形、噪声抑制和声学回声消除。 ClearVox 经过优化,可在 CEVA 声音 DSP 上高效运行,提供经济高效的低功耗解决方案。
除了语音处理,边缘设备还需要处理触发词检测的能力。 CEVA 的 WhisPro 等专用解决方案是实现所需精度和低功耗的绝佳方式(见图 2)。 WhisPro 是一个基于神经网络的语音识别软件包,专供 CEVA 的 DSP 使用,它使 OEM 能够将语音激活添加到他们的语音产品中。它可以处理所需的永远在线聆听,而主处理器在需要时保持休眠状态,从而显着降低整体系统功耗。
点击查看大图
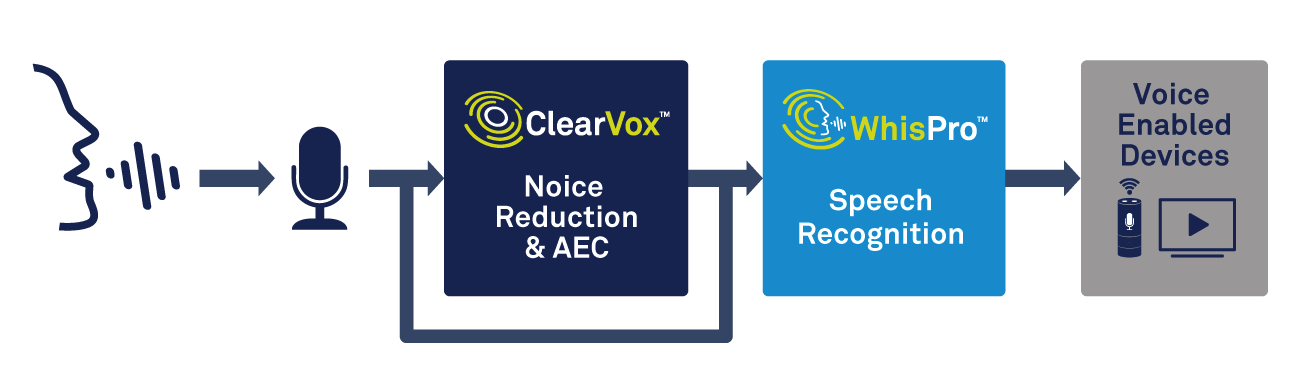
图 2:使用语音处理和语音识别进行语音激活。 (来源:CEVA)
WhisPro 可以达到95%以上的识别率,并且可以支持多个触发词,以及自定义触发词。任何使用过智能扬声器的人都可以作证,让它对唤醒词做出可靠的响应——即使是在嘈杂的环境中——有时也会令人沮丧。正确使用此功能可以极大地改变消费者对语音控制产品质量的看法。
语音识别:本地或云端
一旦语音被数字化和处理,我们就需要某种自动语音识别 (ASR) 功能。 ASR 技术的范围很广,从需要用户说出特定关键字的简单关键字检测,到复杂的自然语言处理 (NLP),用户可以像对另一个人一样正常说话。
关键字检测有很多用途,即使它的词汇量非常有限。例如,一个简单的智能家居设备(例如电灯开关或恒温器)可能只响应一些命令,例如“开”、“关”、“更亮”、“变暗”等。这种级别的 ASR 可以在本地边缘轻松处理,无需互联网连接 - 从而降低成本,确保快速响应,并避免安全和隐私问题。
另一个例子是,可以通过说“奶酪”或“微笑”来告诉许多 Android 智能手机拍照,而将命令发送到云端只会花费太长时间。这是假设可以使用互联网连接,但对于智能手表或耳戴式设备等设备而言,情况并非总是如此。
另一方面,许多应用程序需要 NLP。如果您想向您的 Echo 扬声器询问天气,或者为您寻找今晚的酒店,那么您可以用多种不同的方式来表达您的问题。该设备需要能够理解命令中可能存在的细微差别和口语,并可靠地计算出所询问的内容。简而言之,它需要能够将语音转化为意义,而不仅仅是语音转化为文本。
以我们的酒店查询为例,您可能想询问的可能因素范围很广:价格、位置、评论等等。 NLP 系统必须解释所有这些复杂性,以及一个问题的许多不同表达方式,以及请求中缺乏明确性——说“给我找一个物有所值的中央酒店”对不同的人来说意味着不同的东西人们。获得准确的结果还需要设备考虑问题的上下文,并识别用户何时提出相关的后续问题,或在一个查询中询问多条信息。
这可能需要大量的处理,通常使用人工智能 (AI) 和神经网络,这对于仅在边缘进行处理通常是不切实际的。带有嵌入式处理器的低成本设备将没有足够的能力来处理所需的任务。在这种情况下,正确的选择是将数字化语音发送到云端进行处理。在那里,它可以被解释,并将适当的响应发送回语音控制设备。
您可以看到设备上的边缘处理和云中的远程处理之间存在权衡。在本地处理所有事情可能会更快,并且不依赖于互联网连接,但将难以处理更广泛的问题和信息获取。这意味着对于通用设备,例如家庭中的智能音箱,至少需要将一些处理推送到云端。
为了解决云处理的缺点,本地处理器的功能正在取得进展,在不久的将来,我们可以期待在边缘设备中看到 NLP 和 AI 的重大改进。新技术正在减少所需的内存量,处理器继续变得更快、更省电。
例如,CEVA 的 NeuPro 系列低功耗 AI 处理器为边缘提供了复杂的功能。该系列基于 CEVA 在计算机视觉神经网络方面的经验,为设备端语音处理提供了灵活、可扩展的解决方案。
结论
语音控制界面正迅速成为我们日常生活的重要组成部分,并将在不久的将来添加到越来越多的产品中。更好的信号处理和语音识别功能以及更强大的本地和云端计算资源正在推动改进。
为了满足 OEM 的要求,用于音频处理和语音识别的组件需要在性能、成本和功耗方面应对一些严峻的挑战。对于许多设计师而言,针对手头任务专门优化的解决方案很可能证明是最好的方法——满足最终客户的需求,并缩短上市时间。
无论它们基于何种技术,语音接口都将变得更准确、更容易用日常语言进行对话,而成本下降将使它们对制造商更具吸引力。看看它们接下来的用途将是一段有趣的旅程。
嵌入式