

利用 FPGA 进行深度学习
我最近参加了在硅谷举行的 2018 Xilinx 发展论坛 (XDF)。在这个论坛上,我认识了一家名为 Mipsology 的公司,这是一家人工智能 (AI) 领域的初创公司,声称已经解决了与现场可编程门阵列 (FPGA) 相关的 AI 相关问题。 Mipsology 成立时的宏伟愿景是加速任何神经网络 (NN) 的计算,并在 FPGA 上实现最高性能,而不受其部署固有的限制。
Mipsology 展示了每秒执行超过 20,000 张图像的能力,在赛灵思新发布的 Alveo 板上运行,并处理一系列神经网络,包括 ResNet50、InceptionV3、VGG19 等。
介绍神经网络和深度学习
神经网络以人脑中的神经元网络为基础,是深度学习 (DL) 的基础,深度学习是一种可以自行学习任务的复杂数学系统。通过查看许多示例或关联,NN 可以学习 连接和关系比传统识别程序更快。基于学习配置神经网络执行特定任务的过程 数百万相同类型的样本称为训练 .
例如,神经网络可能会听取许多人声样本并使用深度学习来学习“识别”特定单词的声音。然后,该神经网络可以筛选新的声音样本列表,并使用一种称为 推理 的技术正确识别包含它所学单词的样本 .
尽管很复杂,但深度学习基于执行简单的运算——主要是加法和乘法——数十亿或数万亿。执行此类操作的计算需求令人生畏。更具体地说,执行 DL 推理的计算需求大于 DL 训练的计算需求。 DL 训练必须只执行一次,而神经网络一旦训练完毕,必须对其接收到的每个新样本进行一次又一次的推理。
加速深度学习推理的四种选择
随着时间的推移,工程社区求助于四种不同的计算设备来处理神经网络。按照处理能力和功耗的递增顺序以及灵活性/适应性的递减顺序,这些设备包括:中央处理单元 (CPU)、图形处理单元 (GPU)、FPGA 和专用集成电路 (ASIC)。下表总结了四种计算设备之间的主要差异。
<中心> 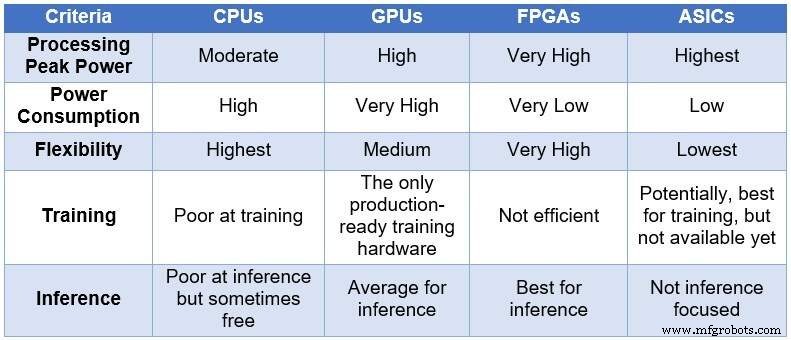
深度学习计算的 CPU、GPU、FPGA 和 ASIC 的比较(来源:Lauro Rizzatti)
CPU 基于冯诺依曼架构。虽然灵活(这是它们存在的原因),但 CPU 会受到长延迟的影响,因为内存访问需要消耗几个时钟周期来执行一个简单的任务。当应用于从最低延迟中受益的任务时,例如神经网络计算,特别是深度学习训练和推理,它们是最糟糕的选择。
GPU 以降低灵活性为代价提供高计算吞吐量。此外,GPU 会消耗大量电力,需要冷却,因此不太适合部署在数据中心。
虽然定制 ASIC 似乎是一个理想的解决方案,但它们也有自己的问题。开发 ASIC 需要数年时间。 DL 和 NN 正在迅速发展,不断取得突破,使去年的技术变得无关紧要。此外,为了与 CPU 或 GPU 竞争,ASIC 需要使用最薄的工艺节点技术来使用大面积的硅片。这使得前期投资成本高昂,而且没有任何长期相关性的保证。综上所述,ASIC 对于特定任务是有效的。
FPGA 设备已成为推理的最佳选择。它们快速、灵活、节能,为数据中心的数据处理提供了良好的解决方案,尤其是在快速发展的深度学习世界、网络边缘和人工智能科学家的办公桌下。
当今可用的最大 FPGA 包括数百万个简单的布尔运算符、数以千计的存储器和 DSP 以及几个 CPU ARM 内核。所有这些资源并行工作——每个时钟滴答触发多达数百万个同时操作——导致每秒执行数万亿次操作。 DL 所需的处理很好地映射到 FPGA 资源上。
与用于深度学习的 CPU 和 GPU 相比,FPGA 还具有其他优势,包括:
它们不限于某些类型的数据。它们可以处理非标准的低精度,更适合为深度学习提供更高的吞吐量。
与 CPU 或 GPU 相比,它们使用的功率更少——对于相同的 NN 计算,平均功率通常低 5 到 10 倍。他们在数据中心的经常性成本较低。
它们可以重新编程以适应任何任务,但足够通用以适应各种任务。 DL 发展迅速,相同的 FPGA 将满足新的需求,而无需下一代芯片(ASIC 的典型特征),从而降低拥有成本。
它们的范围从大型设备到小型设备。它们可用于数据中心或物联网 (IoT) 节点。唯一的区别是它们包含的块数。
闪光的不是金子
FPGA 的高计算能力、低功耗和灵活性是有代价的——编程难度。
物联网技术