

如何使用就绪/有效握手在块 RAM 中创建 AXI FIFO
当我第一次必须创建逻辑来连接 AXI 模块时,我对 AXI 接口的特殊性有点恼火。代替常规的忙/有效、满/有效或空/有效控制信号,AXI 接口使用名为“就绪”和“有效”的两个控制信号。我的沮丧很快变成了敬畏。
AXI 接口具有内置流量控制,无需使用额外的控制信号。这些规则很容易理解,但在 FPGA 上实现 AXI 接口时必须考虑一些陷阱。本文将向您展示如何在 VHDL 中创建 AXI FIFO。
AXI 解决了延迟一个周期的问题
防止过度读取和覆盖是创建数据流接口时的常见问题。问题是当两个时钟逻辑模块进行通信时,每个模块只能以一个时钟周期延迟读取其对应模块的输出。

上图显示了顺序模块写入使用 write enable/full 的 FIFO 的时序图 信令方案。接口模块通过断言 wr_en 将数据写入 FIFO 信号。 FIFO 将断言 full 当其他数据元素没有空间时发出信号,提示数据源停止写入。
不幸的是,只要接口模块只使用时钟逻辑,它就无法及时停止。 FIFO 提高 full 标志正好在时钟的上升沿。同时,接口模块尝试写入下一个数据元素。它无法对 full 进行采样和反应 在为时已晚之前发出信号。
一种解决方案是包含一个额外的 almost_empty 信号,我们在 How to create a ring buffer FIFO in VHDL 教程中做到了这一点。 empty 之前的附加信号 信号,让接口模块有时间做出反应。
就绪/有效握手
AXI 协议在每个方向上仅使用两个控制信号实现流控制,一个称为 ready 和另一个 valid . ready 信号由接收器控制,逻辑 '1' 此信号上的值表示接收器已准备好接受新数据项。 valid 另一方面,信号由发送方控制。发送方应设置valid 到 '1' 当数据总线上呈现的数据有效采样时。
重要的部分来了: 只有当 ready 和 valid 是 '1' 在同一个时钟周期。接收者通知它何时准备好接受数据,发送者只需在有东西要传输时将数据放在那里。当双方同意,即发送方准备好发送而接收方准备接收时,就会发生传输。

上面的波形显示了一个数据项的示例事务。采样发生在时钟上升沿,时钟逻辑通常就是这种情况。
实施
有多种方法可以在 VHDL 中实现 AXI FIFO。它可以是移位寄存器,但我们将使用环形缓冲区结构,因为它是在块 RAM 中创建 FIFO 的最直接方法。您可以使用变量和信号在一个巨大的流程中创建所有功能,也可以将功能拆分为多个流程。
此实现对大多数必须更新的信号使用单独的进程。只有需要同步的进程对时钟敏感,其他的使用组合逻辑。
实体
实体声明包括一个通用端口,用于设置输入和输出字的宽度,以及在 RAM 中预留空间的插槽数。 FIFO 的容量等于 RAM 深度减一。一个槽始终保持为空,以区分 FIFO 是满还是空。
entity axi_fifo is
generic (
ram_width : natural;
ram_depth : natural
);
port (
clk : in std_logic;
rst : in std_logic;
-- AXI input interface
in_ready : out std_logic;
in_valid : in std_logic;
in_data : in std_logic_vector(ram_width - 1 downto 0);
-- AXI output interface
out_ready : in std_logic;
out_valid : out std_logic;
out_data : out std_logic_vector(ram_width - 1 downto 0)
);
end axi_fifo;
端口声明中的前两个信号是时钟和复位输入。该实现采用同步复位,对时钟上升沿敏感。
有一个使用就绪/有效控制信号和通用宽度输入数据信号的 AXI 风格输入接口。最后是 AXI 输出接口,其信号与输入信号相似,只是方向相反。属于输入输出接口的信号以in_为前缀 或 out_ .
一个 AXI FIFO 的输出可以直接连接到另一个 AXI FIFO 的输入,接口完美地结合在一起。虽然,比堆叠它们更好的解决方案是增加 ram_depth 如果您想要更大的 FIFO,则为通用。
信号声明
VHDL 文件声明区域中的前两个语句声明 RAM 类型及其信号。 RAM 是根据通用输入动态调整大小的。
-- The FIFO is full when the RAM contains ram_depth - 1 elements type ram_type is array (0 to ram_depth - 1) of std_logic_vector(in_data'range); signal ram : ram_type;
第二个代码块声明了一个新的整数子类型和来自它的四个信号。 index_type 大小可以准确地表示 RAM 的深度。 head 信号始终指示将在下一次写操作中使用的 RAM 插槽。 tail 信号指向将在下一次读取操作中访问的插槽。 count 的值 信号总是等于当前存储在 FIFO 中的元素数量,而 count_p1 是延迟一个时钟周期的同一信号的副本。
-- Newest element at head, oldest element at tail subtype index_type is natural range ram_type'range; signal head : index_type; signal tail : index_type; signal count : index_type; signal count_p1 : index_type;
然后是两个名为 in_ready_i 的信号 和 out_valid_i .这些只是实体输出 in_ready 的副本 和 out_valid . _i 后缀只是表示内部 ,这是我编码风格的一部分。
-- Internal versions of entity signals with mode "out" signal in_ready_i : std_logic; signal out_valid_i : std_logic;
最后,我们声明一个用于指示同时读取和写入的信号。我将在本文后面解释它的目的。
-- True the clock cycle after a simultaneous read and write signal read_while_write_p1 : std_logic;
子程序
在信号之后,我们声明一个函数来增加我们自定义的 index_type . next_index 函数查看 read 和 valid 参数来确定是否有正在进行的读或读/写事务。如果是这种情况,索引将被递增或包装。如果不是,则返回不变的索引值。
function next_index(
index : index_type;
ready : std_logic;
valid : std_logic) return index_type is
begin
if ready = '1' and valid = '1' then
if index = index_type'high then
return index_type'low;
else
return index + 1;
end if;
end if;
return index;
end function;
为了避免重复输入,我们创建了更新 head 的逻辑 和 tail 在一个过程中发出信号,而不是作为两个相同的过程。 update_index 程序接受时钟和复位信号,index_type的信号 , 一个 ready 信号和一个 valid 信号作为输入。
procedure index_proc(
signal clk : in std_logic;
signal rst : in std_logic;
signal index : inout index_type;
signal ready : in std_logic;
signal valid : in std_logic) is
begin
if rising_edge(clk) then
if rst = '1' then
index <= index_type'low;
else
index <= next_index(index, ready, valid);
end if;
end if;
end procedure;
这个完全同步的过程使用 next_index 更新index的函数 当模块未复位时发出信号。重置时,index 信号将被设置为它可以表示的最低值,因为 index_type 和 ram_type 被宣布。我们本可以使用 0 作为重置值,但我尽量避免硬编码。
将内部信号复制到输出
这两个并发语句将输出信号的内部版本复制到实际输出。我们需要对内部副本进行操作,因为 VHDL 不允许我们以 out 模式读取实体信号 模块内部。另一种方法是声明 in_ready 和 out_valid 使用模式 inout ,但大多数公司编码标准限制使用 inout 实体信号。
in_ready <= in_ready_i; out_valid <= out_valid_i;
更新头部和尾部
我们已经讨论过 index_proc 用于更新 head 的过程 和 tail 信号。通过将适当的信号映射到该子程序的参数,我们得到了两个相同的过程,一个用于控制FIFO输入,一个用于输出。
-- Update head index on write PROC_HEAD : index_proc(clk, rst, head, in_ready_i, in_valid); -- Update tail index on read PROC_TAIL : index_proc(clk, rst, tail, out_ready, out_valid_i);
由于 head 和 tail 由复位逻辑设置为相同的值,FIFO 最初将为空。这就是这个环形缓冲区的工作原理,当两者都指向同一个索引时,这意味着 FIFO 是空的。
推断块 RAM
在大多数 FPGA 架构中,块 RAM 原语是完全同步的组件。这意味着,如果我们希望综合工具从我们的 VHDL 代码中推断出块 RAM,我们需要将读取和写入端口置于时钟进程内。此外,不能有与块 RAM 相关的复位值。
PROC_RAM : process(clk)
begin
if rising_edge(clk) then
ram(head) <= in_data;
out_data <= ram(next_index(tail, out_ready, out_valid_i));
end if;
end process;
没有读取启用 或写启用 在这里,这对于 AXI 来说太慢了。相反,我们不断地写入 head 指向的 RAM 插槽 指数。然后,当我们确定发生了写事务时,我们只需推进 head 锁定写入值。
同样,out_data 在每个时钟周期更新。 tail 当读取发生时,指针只是移动到下一个插槽。请注意,next_index 函数用于计算读取端口的地址。我们必须这样做以确保 RAM 在读取后反应足够快并开始输出下一个值。
计算FIFO中的元素个数
计算 RAM 中的元素数量只需减去 head 从 tail .如果 head 已经包装好了,我们必须用 RAM 中的插槽总数来抵消它。我们可以通过 ram_depth 访问这些信息 来自通用输入的常量。
PROC_COUNT : process(head, tail)
begin
if head < tail then
count <= head - tail + ram_depth;
else
count <= head - tail;
end if;
end process;
我们还需要跟踪 count 的先前值 信号。下面的过程创建了一个延迟一个时钟周期的版本。 _p1 后缀是表示这一点的命名约定。
PROC_COUNT_P1 : process(clk)
begin
if rising_edge(clk) then
if rst = '1' then
count_p1 <= 0;
else
count_p1 <= count;
end if;
end if;
end process;
更新准备好了 输出
in_ready 信号应为 '1' 当此模块准备好接受另一个数据项时。只要 FIFO 未满就应该是这种情况,而这正是这个过程的逻辑所说的。
PROC_IN_READY : process(count)
begin
if count < ram_depth - 1 then
in_ready_i <= '1';
else
in_ready_i <= '0';
end if;
end process;
检测同时读写
由于我将在下一节中解释的一个极端情况,我们需要能够识别同时读取和写入操作。每次在同一个时钟周期内有有效的读写事务,这个过程都会设置read_while_write_p1 向 '1' 发出信号 在下一个时钟周期。
PROC_READ_WHILE_WRITE_P1: process(clk)
begin
if rising_edge(clk) then
if rst = '1' then
read_while_write_p1 <= '0';
else
read_while_write_p1 <= '0';
if in_ready_i = '1' and in_valid = '1' and
out_ready = '1' and out_valid_i = '1' then
read_while_write_p1 <= '1';
end if;
end if;
end if;
end process;
更新有效 输出
out_valid 信号向下游模块指示 out_data 上呈现的数据 是有效的,可以随时采样。 out_data 信号直接来自 RAM 输出。实现 out_valid 由于 Block RAM 输入和输出之间存在额外的时钟周期延迟,因此信号有点棘手。
该逻辑是在一个组合过程中实现的,因此它可以对不断变化的输入信号做出无延迟的反应。该过程的第一行是设置 out_valid 的默认值 向 '1' 发出信号 .如果两个后续 If 语句均未触发,则这将是当前值。
PROC_OUT_VALID : process(count, count_p1, read_while_write_p1)
begin
out_valid_i <= '1';
-- If the RAM is empty or was empty in the prev cycle
if count = 0 or count_p1 = 0 then
out_valid_i <= '0';
end if;
-- If simultaneous read and write when almost empty
if count = 1 and read_while_write_p1 = '1' then
out_valid_i <= '0';
end if;
end process;
第一个 If 语句检查 FIFO 是否为空或在前一个时钟周期中为空。很明显,当FIFO中有0个元素时,它是空的,但是我们还需要检查上一个时钟周期的FIFO的填充程度。
考虑下面的波形。最初,FIFO 是空的,如 count 所示 信号为 0 .然后,在第三个时钟周期发生写入。 RAM 插槽 0 在下一个时钟周期更新,但在 out_data 上出现数据之前需要一个额外的周期 输出。 or count_p1 = 0 的用途 声明是确保 out_valid 仍然是 '0' (以红色圈出)而值通过 RAM 传播。

最后一个 If 语句防止另一个极端情况。我们刚刚讨论了如何通过检查当前和以前的 FIFO 填充级别来处理空时写入的特殊情况。但是如果我们在 count 时同时执行读写操作会发生什么? 已经是 1 ?
下面的波形显示了这种情况。最初,FIFO 中存在一个数据项 D0。它已经存在了一段时间,所以 count 和 count_p1 是 0 .然后在第三个时钟周期同时进行读取和写入。一个项目离开 FIFO,一个新项目进入,使计数器保持不变。
![]()
在读取和写入的时刻,RAM 中没有准备好输出的下一个值,如果填充水平高于 1 就会出现。在输入值出现在输出上之前,我们必须等待两个时钟周期。如果没有任何附加信息,就无法检测到这种极端情况,以及 out_valid 的值 在下一个时钟周期(标记为纯红色)将错误地设置为 '1' .
这就是为什么我们需要 read_while_write_p1 信号。它检测到有同时读取和写入,我们可以通过设置 out_valid 来考虑这一点 到 '0' 在那个时钟周期内。
在 Vivado 中综合
要将设计实现为 Xilinx Vivado 中的独立模块,我们首先必须为通用输入赋值。这可以在 Vivado 中通过使用 Settings 来实现 → 一般 → 泛型/参数 菜单,如下图所示。
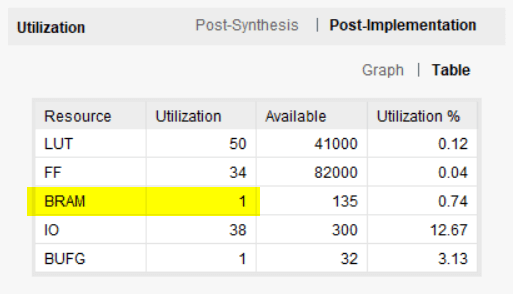
已选择通用值以匹配作为目标器件的 Xilinx Zynq 架构中的 RAMB36E1 原语。实施后的资源使用情况如下图所示。 AXI FIFO 使用一个块 RAM 和少量 LUT 和触发器。
AXI 已准备就绪/有效
AXI 代表高级可扩展接口,它是 ARM 高级微控制器总线架构 (AMBA) 标准的一部分。 AXI 标准不仅仅是读取/有效握手。如果您想了解更多关于 AXI 的信息,我推荐这些资源以供进一步阅读:
- 维基百科:AXI
- ARM AXI 介绍
- Xilinx AXI 介绍
- AXI4 规范
VHDL