

研究人员展示了降低精度训练的 AI 芯片
在 ISSCC,IBM Research 展示了一款测试芯片,该芯片代表了其多年来在低精度 AI 训练和推理算法方面的工作的硬件体现。 7nm 芯片支持 16 位和 8 位训练,以及 4 位和 2 位推理(32 位或 16 位训练和 8 位推理是当今的行业标准)。
降低精度可以减少 AI 计算所需的计算量和功率,但 IBM 有一些其他架构技巧也有助于提高效率。面临的挑战是在不对计算结果产生负面影响的情况下降低精度,这是 IBM 在算法级别上多年来一直在努力的事情。
IBM 的 AI 硬件中心成立于 2019 年,旨在支持该公司将 AI 计算性能每年提高 2.5 倍的目标,以及到 2029 年将性能效率 (FLOPS/W) 提高 1000 倍的宏伟总体目标。 AI 模型的大小以及训练它们所需的计算量正在快速增长。尤其是自然语言处理 (NLP) 模型现在是万亿参数的庞然大物,训练这些野兽所产生的碳足迹并没有被忽视。
IBM Research 的这款最新测试芯片显示了 IBM 迄今为止取得的进展。对于 8 位训练,4 核芯片能够达到 25.6 TFLOPS,而对于 4 位整数计算的推理性能为 102.4 TOPS(这些数字是针对 1.6GHz 的时钟频率和 0.75V 的电源电压)。将时钟频率降至 1GHz 并将电源电压降至 0.55V,可将电源效率提升至 3.5 TFLOPS/W (FP8) 或 16.5 TOPS/W (INT4)。
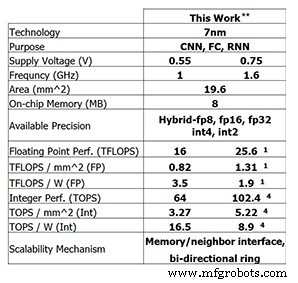
IBM Research 测试芯片的性能(图片:IBM Research)**报告的性能为 0% 稀疏度。 (1) FP8。 (4) INT4。
低精度训练
这种性能建立在多年在低精度训练和推理技术上的算法工作之上。该芯片是第一个支持 IBM 的特殊 8 位混合浮点格式(混合 FP8)的芯片,该格式首次在 NeurIPS 2019 上展示。这种新格式专为允许 8 位训练而开发,将 16 位所需的计算量减半训练,而不会对结果产生负面影响(在此处阅读有关 AI 处理的数字格式的更多信息)。
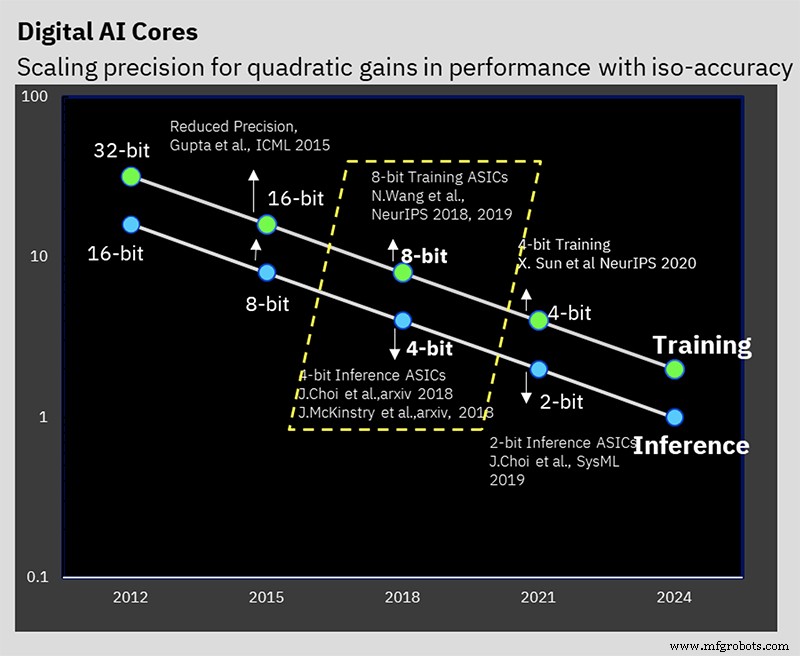
IBM Research 一直致力于解决在保持准确性的同时降低精度的问题(图片:IBM)
“多年来,我们在各种研究中了解到,低精度训练非常具有挑战性,但如果您拥有正确的数字格式,则可以进行 8 位训练,”IBM 研究员兼加速器架构高级经理 Kailash Gopalakrishnan IBM Research 的机器学习告诉 EE Times . “理解正确的数字格式并将它们放在深度学习中的正确张量上是其中的关键部分。”
Hybrid FP8 实际上是两种不同格式的组合。一种格式用于深度学习的前向传递中的权重和激活,另一种格式用于后向传递。推理仅使用前向传递,而训练需要前向和后向阶段。
“我们了解到,在深度学习的前向传递中,就权重和激活的表示而言,您需要更高的保真度、更高的精度,”Gopalakrishnan 说。 “另一方面[后向阶段],梯度具有高动态范围,这就是我们认识到需要[更大]指数的地方……这是深度学习中某些张量需要的权衡更高的精度,更高的保真度表示,而其他张量需要更宽的动态范围。这就是我们在 2019 年底推出的混合 FP8 格式的起源,现在已经转化为硬件。”
IBM 的工作确定,在前向阶段拆分指数和尾数之间的 8 位的最佳方法是 1-4-3(一个符号位、一个四位指数和一个三位尾数),另一种方法是 5-后向阶段的位指数版本,动态范围为 2 32 .具有混合 FP8 功能的硬件旨在支持这两种格式。
层级积累
研究人员称之为“分层累积”的一项创新允许累积随着权重和激活而降低精度。典型的 FP16 训练方案在 32 位算法中积累以保持精度,但 IBM 的 8 位训练可以在 FP16 中积累。保持在 FP32 中的积累首先会限制迁移到 FP8 所获得的优势。
“在浮点运算中发生的事情是,如果你将一大组数字相加,假设它是一个 10,000 长度的向量,并且你将所有这些相加,浮点表示本身的准确性开始限制你的精度总和,”Gopalakrishnan 解释说。 “我们得出的结论是,最好的方法不是按顺序进行加法,但我们倾向于将长期积累分解成组,我们称之为块。然后我们将这些块相互添加,这样可以最大限度地减少出现此类错误的可能性。”
低精度推理
目前大多数 AI 推理使用 8 位整数格式 (INT8)。 IBM 的工作表明,就低精度而言,4 位整数是最先进的,同时不会损失显着的预测精度。在量化(将模型转换为较低精度数字的过程)之后,执行量化感知训练。这实际上是一种重新训练方案,可以减轻量化导致的任何错误。这种重新训练可以最大限度地减少精度损失; IBM 可以“轻松”量化为 4 位整数算法,准确度仅损失 0.5%,Gopalakrishnan 表示这对于大多数应用程序来说“非常可接受”。
片上环
除了专注于低精度算法之外,还有其他硬件创新有助于提高芯片的效率。
一种是片上环形通信,一种针对深度学习进行优化的片上网络,允许每个内核向其他内核多播数据。多播通信对于深度学习至关重要,因为核心需要共享权重并将结果传达给其他核心。它还允许从片外存储器加载的数据广播到多个内核。这减少了需要读取内存的次数,以及整体发送的数据量,最大限度地减少了所需的内存带宽。
IBM Research 机器学习和加速器架构研究人员 Ankur Agrawal 说:“我们意识到我们可以比环更快地运行内核,因为环涉及很多长线。” “我们将环的运行频率与内核的运行频率分离……这使我们能够独立地优化环相对于内核的性能。”
电源管理
IBM 的另一项创新是引入了频率缩放方案以最大限度地提高效率。
“深度学习工作负载有点特殊,因为即使在编译阶段,您也知道在这个非常大的工作负载中将遇到哪些计算阶段,”Agrawal 说。 “我们可以进行一些预配置,以确定在计算的不同部分中功率分布会是什么样子。”
深度学习的功率分布通常具有很大的峰值(对于卷积等计算量大的操作)和低谷(可能对于激活函数)。
IBM 的方案非常积极地设置芯片的初始工作电压和频率,这样即使在最低功耗模式下,芯片也几乎处于其功率包络的极限。然后,当需要更多功率时,降低工作频率。
“最终的结果是芯片在整个计算过程中都以接近峰值功率运行,即使在不同阶段也是如此,”Agrawal 解释说。 “总的来说,通过没有这些低功耗阶段,您可以更快地完成所有工作。通过在所有操作阶段将功耗几乎保持在峰值功耗,您已将功耗的任何下降转化为性能提升。”
不使用电压缩放,因为它更难即时进行;对于深度学习计算来说,稳定在新电压下所需的时间太长。因此,IBM 通常选择在该工艺节点的尽可能低的电源电压下运行芯片。
测试芯片
IBM 的测试芯片有四个内核,部分是为了测试所有不同的功能。 Gopalakrishnan 描述了如何特意选择核心尺寸以达到最佳;将数千个小内核连接在一起的架构很复杂,而在大内核之间划分问题也很困难。该中级内核旨在满足 IBM 及其 AI 硬件中心合作伙伴的需求,在尺寸方面找到了最佳位置。
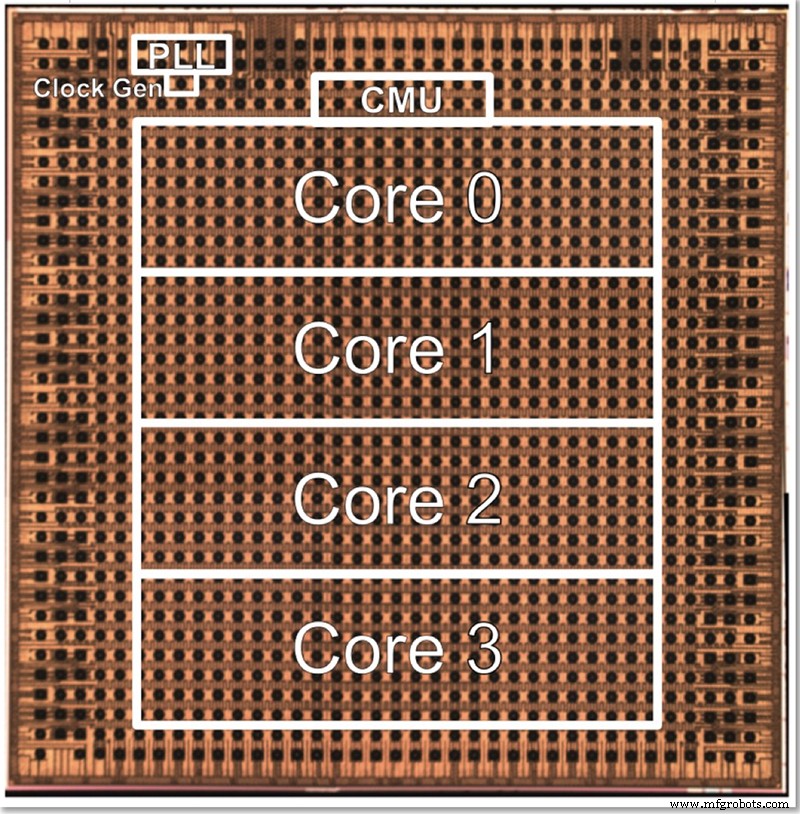
IBM 4 核低精度测试芯片的裸片照片(图片来源:IBM)
可以通过更改内核数量来扩大或缩小架构。最终,Gopalakrishnan 设想 1-2 核芯片适用于边缘设备,而 32-64 核芯片可以在数据中心工作。他说,它支持多种格式(FP16、混合 FP8、INT4 和 INT2)的事实也使其对于大多数应用程序来说足够通用。
“不同的[应用]领域会对能源效率和精度等有不同的要求,”他说。 “我们精准的瑞士军刀,每一个都经过单独优化,使我们能够在各个领域瞄准这些核心,而不必在该过程中放弃任何能源效率。”
除了硬件,IBM Research 还开发了一个工具堆栈(“Deep Tools”),其编译器可实现芯片的高利用率(60-90%)。
EE 时代 ’之前接受 IBM Research 的采访透露,基于这种架构的低精度 AI 训练和推理芯片应该会在两年左右上市。
>> 本文最初发表于我们的姊妹网站 EE Times。
相关内容:
- AI 芯片通过减少模型来保持准确性
- 在边缘训练 AI 模型
- 边缘 AI 的竞赛正在进行
- 边缘 AI 挑战内存技术
- 工程团队寻求将 1mW AI 推向边缘
- 用于小规模任务的神经网络应用
- AI IC 研究探索替代架构
有关 Embedded 的更多信息,请订阅 Embedded 的每周电子邮件通讯。
嵌入式