

神经形态计算开发套件首次亮相
神经拟态计算 IP 供应商 BrainChip 在最近的 Linley Fall Processor Conference 期间为其 Akida 神经拟态处理器推出了两个开发套件。两个套件均采用该公司的 Akida 神经形态 SoC:x86 Shuttle PC 开发套件和基于 Arm 的 Raspberry Pi 套件。 BrainChip 正在向使用其尖峰神经网络处理器的开发人员提供工具,以期获得其 IP 的许可。 Akida 硅也可用。
BrainChip 的神经形态技术支持超低功耗 AI,用于分析边缘系统中的数据,在这些系统中寻求极低功耗、实时处理传感器数据。该公司开发了一种神经处理单元 (NPU),旨在处理尖峰神经网络 (SNN),这是一种不同于主流深度学习方法的受大脑启发的神经网络。与大脑一样,SNN 依赖于在空间和时间上传达信息的“尖峰”。也就是说,大脑可以识别峰值的序列和时间。称为“事件域”,峰值通常由传感器数据的变化(例如,基于事件的相机中像素颜色的变化)引起。
与 SNN 一起,BrainChip 的 NPU 还可以处理卷积神经网络 (CNN),就像通常用于计算机视觉和关键字识别算法的卷积神经网络一样,其功耗低于其他边缘实现。这是通过将 CNN 转换为 SNN 并在事件域中运行推理来完成的。该方法还允许在边缘进行片上学习,这种 SNN 的质量将扩展到转换后的 CNN。

BrainChip 的开发板可用于 x86 穿梭 PC 或 Raspberry Pi。 (来源:BrainChip)
BrainChip 联合创始人兼首席开发官 Anil Mankar 告诉 EE Times .
从 CNN 到事件域的转换由 BrainChip 的软件工具流 MetaTF 执行。数据可以转化为峰值,训练好的模型可以转化为在 BrainChip 的 NPU 上运行。
“我们的运行时软件消除了对‘什么是 SNN?’和‘什么是事件域?’的恐惧,”Mankar 说。 “我们竭尽全力隐藏这一点。
“熟悉 TensorFlow 或 Keras API 的人……可以使用他们在 [其他硬件]、相同网络、相同数据集上运行的应用程序,通过我们的量化感知训练,并在我们的硬件上运行它并自行测量功率,看看准确度是多少。”
CNN 特别擅长从大数据集中提取特征,Mankar 解释说,转换到事件域可以保留这种优势。大多数层的卷积操作都是在事件域中实现的,但替换了最后一层。用识别传入尖峰的层替换它,使原本普通的 CNN 能够通过边缘尖峰时间依赖的可塑性进行学习,从而消除在云中的重新训练。
虽然原生 SNN(为事件域从头编写的那些)可以使用 1 位精度,但转换后的 CNN 需要 1 位、2 位或 4 位尖峰。 BrainChip 的量化工具可帮助设计人员决定逐层量化的积极程度。 Brainchip 已将 MobileNet V1 量化为 10 对象分类,量化为 4 位后预测准确率为 93.1%。
由于稀疏性,转换到事件域的一个副产品是显着的节能。非零激活图值表示为 1 到 4 位事件,NPU 只对事件进行计算,而不是整个激活图。
开发人员“可以查看权重,看到非零权重,并尽量避免乘以零权重,”Mankar 说。 “但这意味着你必须知道零在哪里,并且需要计算”这些操作。
对于典型的 CNN,激活图会随着每个视频帧而变化,因为 ReLU 函数以零为中心——通常一半的激活将为零。通过不从这些零产生尖峰,事件域中的计算仅限于非零激活。将 CNN 转换为在事件域中运行可以利用稀疏性,快速减少推理所需的 MAC 操作数量,从而降低功耗。
可以转换到事件域的函数包括卷积、逐点卷积、深度卷积、最大池化和全局平均池化。
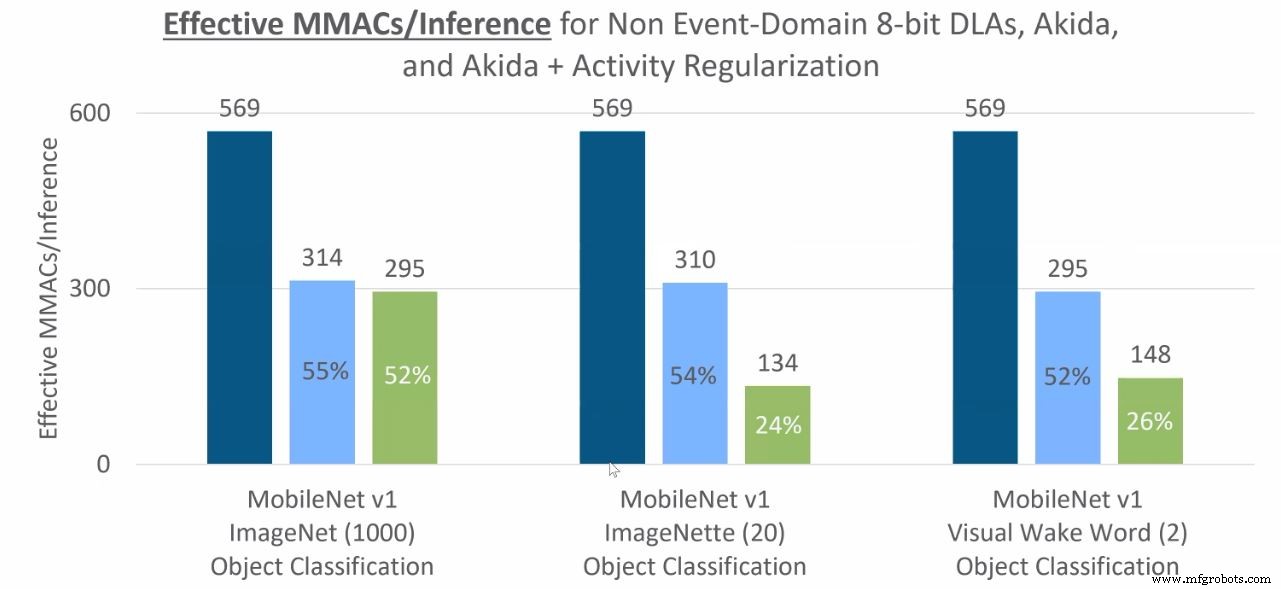
对象分类推理所需的 MAC 操作(深蓝色是非事件域中的 CNN,浅蓝色是事件域/Akida,绿色是进一步活动正则化的事件域)。 (来源:BrainChip)
在一个示例中,在 Akida 开发板上运行的关键字识别模型在 4 位量化后每次推理消耗的能量低至 37 µJ(或每瓦每秒 27,336 次推理)。预测准确率为 91.3%,芯片速度减慢至 5 MHz 以达到观察到的性能。 (见下图)。
传感器不可知
BrainChip 的 NPU IP 和 Akida 芯片与网络类型无关,可以与大多数传感器一起使用。相同的硬件可以使用 CNN 转换或用于嗅觉、味觉和振动/触觉感知的 BrainChip 的 SNN 来处理图像和音频数据。
NPU 集群为四个节点,通过网状网络进行通信。每个 NPU 包括用于参数、激活和内部事件缓冲区的处理和 100 kB 本地 SRAM。 CNN 或 SNN 网络层被分配给多个 NPU 的组合,在没有 CPU 支持的情况下在层之间传递事件。 (虽然 CNN 以外的网络可以转换为事件域,但 Mankar 表示它们需要 CPU 才能在 Akida 上运行。)
BrainChip 的 NPU IP 最多可以配置为 20 个节点,更大的网络可以在节点更少的设计上多次运行。
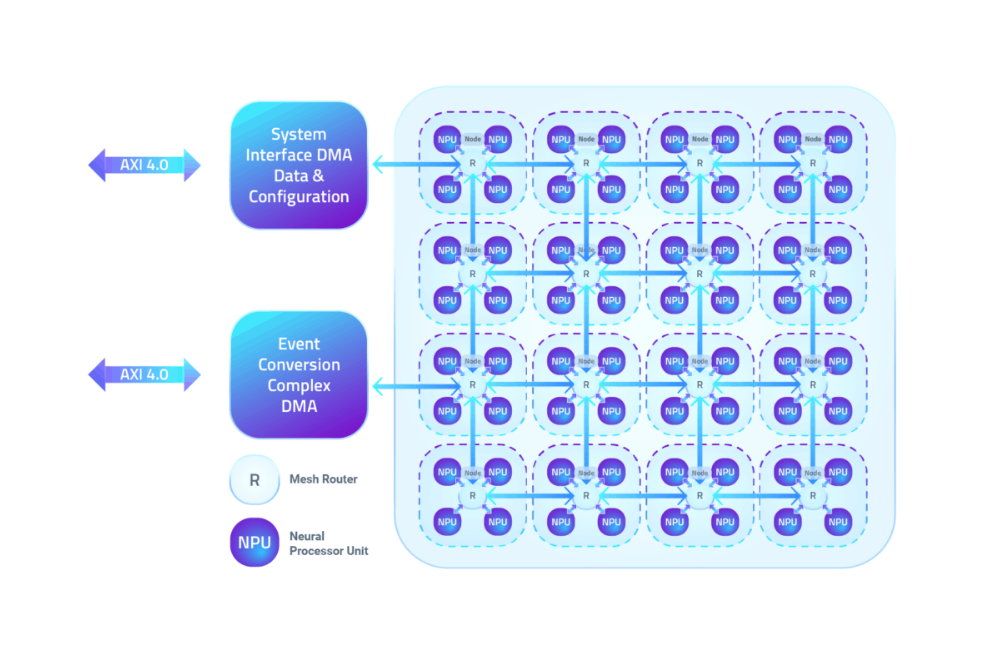
四个 BrainChip NPU 的节点通过网状网络连接。 (来源:BrainChip)
BrainChip 视频显示,Akida 芯片部署在车内系统中,其中一个芯片用于检测驾驶员、识别驾驶员的面部并同时识别他们的声音。关键字识别需要 600 µW,面部识别需要 22 mW,用于检测驾驶员的视觉唤醒词推理为 6-8 mW。
BrainChips 全球销售副总裁 Rob Telson 表示,此类汽车平台的低功耗为其他领域的汽车制造商提供了灵活性,并补充说 Akida 芯片基于台积电的 28 纳米工艺技术。 Telson 补充说,IP 客户可以采用更精细的工艺节点以节省更多电力。
同时,面部识别系统可以在片上学习新面孔,而无需转移到云端。例如,智能门铃可以通过一次性学习在本地识别一个人的脸。 Mankar 指出,如果网络的最后一层分配有足够数量的神经元,识别的面部总数可以从 10 个增加到 50 个以上。
抢先体验的客户
BrainChip 拥有 55 名员工,分布在其位于加利福尼亚州 Aliso Viejo 的总部和位于法国图卢兹、印度海得拉巴和澳大利亚珀斯的设计办公室。公司拥有14项专利,并在澳大利亚证券交易所和美国场外交易市场公开交易。
Telson 说,包括 NASA 在内的大约 15 个早期访问客户。其他包括汽车、军事、航空航天、医疗(嗅觉 Covid-19 检测)和消费电子公司。 BrainChip 定位于智能健康、智慧城市、智能家居和智能交通等消费类应用。
据 Telson 称,另一个早期客户是微控制器专家瑞萨电子,该公司已授权 2 节点 Akida NPU IP 与未来 MCU 集成,旨在物联网部署中的传感器数据分析。
Akida IP 和芯片现已上市。
>> 本文最初发表在我们的姊妹网站 EE Times。
相关内容:
- 初创公司将 1000 个 RISC-V 内核装入 AI 加速器芯片
- AI 芯片面向低功耗边缘设备
- 支持 AI 的 SoC 可处理多个视频流
- 使用带扩展的 CPU 功能将安全性构建到 AI SoC 中
- 微控制器架构为 AI 发展
有关 Embedded 的更多信息,请订阅 Embedded 的每周电子邮件通讯。
嵌入式