

如何训练基本的感知器神经网络
本文介绍了 Python 代码,可让您为简单的神经网络自动生成权重。
欢迎来到 AAC 的感知器神经网络系列。如果您希望从头开始了解背景知识或继续前进,请查看此处的其余文章:
- 如何使用神经网络进行分类:什么是感知器?
- 如何使用简单的感知器神经网络示例对数据进行分类
- 如何训练基本的感知器神经网络
- 了解简单的神经网络训练
- 神经网络训练理论简介
- 了解神经网络中的学习率
- 使用多层感知器进行高级机器学习
- Sigmoid 激活函数:多层感知器神经网络中的激活
- 如何训练多层感知器神经网络
- 了解多层感知器的训练公式和反向传播
- Python 实现的神经网络架构
- 如何在 Python 中创建多层感知器神经网络
- 使用神经网络进行信号处理:神经网络设计中的验证
- 训练神经网络数据集:如何训练和验证 Python 神经网络
使用单层感知器进行分类
上一篇文章介绍了一个简单的分类任务,我们从基于神经网络的信号处理的角度对其进行了研究。这项任务所需的数学关系非常简单,我可以通过考虑一组特定的权重如何让输出节点对输入数据进行正确分类来设计网络。
这是我设计的网络:
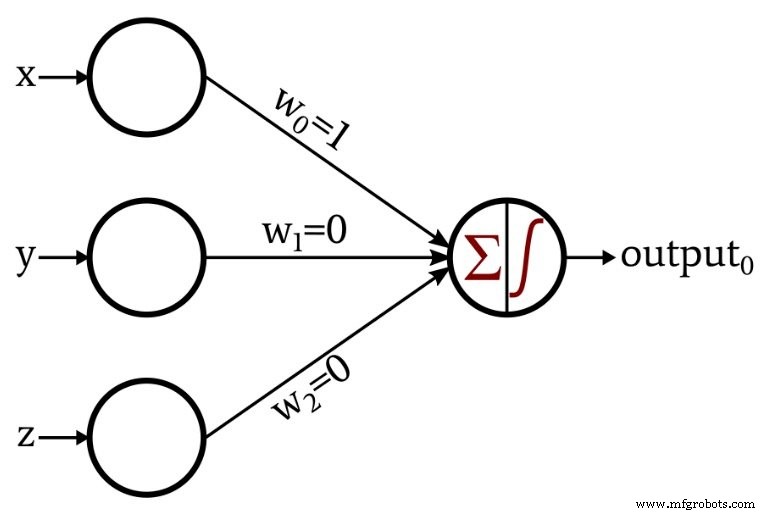
输出节点中的激活函数为单位步:
\[f(x)=\begin{cases}0 &x <0\\1 &x \geq 0\end{cases}\]
当我展示了一个通过称为训练的程序创建自己的权重的网络时,讨论变得更有趣了:
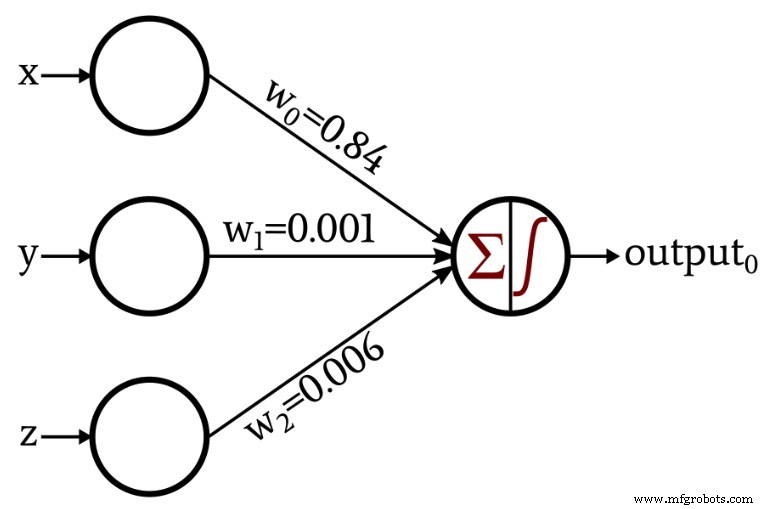
在本文的其余部分,我们将检查我用来获取这些权重的 Python 代码。
Python 神经网络
代码如下:
导入熊猫 将 numpy 导入为 np input_dim =3 学习率 =0.01 权重 =np.random.rand(input_dim) #权重[0] =0.5 #权重[1] =0.5 #权重[2] =0.5 Training_Data =pandas.read_excel("3D_data.xlsx") Expected_Output =Training_Data.output Training_Data =Training_Data.drop(['output'],axis=1) Training_Data =np.asarray(Training_Data) training_count =len(Training_Data[:,0]) 对于范围(0,5)中的时代: 对于范围(0,training_count)中的数据: Output_Sum =np.sum(np.multiply(Training_Data[datum,:], Weights)) 如果 Output_Sum <0: 输出值 =0 别的: 输出值 =1 错误 =Expected_Output[数据] - Output_Value 对于范围内的 n(0, input_dim): 权重[n] =权重[n] + learning_rate*error*Training_Data[datum,n] 打印(“w_0 =%.3f”%(权重[0])) 打印(“w_1 =%.3f”%(权重[1])) 打印(“w_2 =%.3f”%(权重[2]))
让我们仔细看看这些说明。
配置网络和组织数据
input_dim =3
维度是可调的。如果您还记得,我们的输入数据由三维坐标组成,因此我们需要三个输入节点。本程序不支持多输出节点,但我们会在以后的实验中加入可调整的输出维度。
learning_rate =0.01
我们将在以后的文章中讨论学习率。
权重 =np.random.rand(input_dim) #权重[0] =0.5 #权重[1] =0.5 #权重[2] =0.5
权重通常初始化为随机值。 numpy random.rand() 函数生成一个长度为 input_dim 的数组 填充了分布在区间 [0, 1) 上的随机值。但是,初始权重值会影响训练过程产生的最终权重值,因此如果您想评估其他变量(例如训练集大小或学习率)的影响,您可以通过设置所有权重为已知常数而不是随机生成的数字。
Training_Data =pandas.read_excel("3D_data.xlsx") 我使用 pandas 库从 Excel 电子表格导入训练数据。下一篇文章将详细介绍训练数据。
Expected_Output =Training_Data.output Training_Data =Training_Data.drop(['output'], axis=1)
训练数据集包括输入值和相应的输出值。第一条指令分离输出值并将它们存储在一个单独的数组中,下一条指令从训练数据集中移除输出值。
Training_Data =np.asarray(Training_Data) training_count =len(Training_Data[:,0])
我将训练数据集(目前是 Pandas 数据结构)转换为 numpy 数组,然后查看其中一列的长度以确定有多少数据点可用于训练。
计算输出值
对于范围(0,5)中的纪元:
一节训练课的长度取决于可用训练数据的数量。但是,您可以通过使用相同的数据集多次训练网络来继续优化权重——训练的好处不会因为网络已经看到这些训练数据而消失。整个训练集的每一次完整遍历称为一个纪元。
对于范围内的数据(0,training_count):
这个循环中包含的过程对训练集中的每一行发生一次,其中“行”是指一组输入数据值和相应的输出值(在我们的例子中,一个输入组由代表 x、y 的三个数字组成, 和一个点在三维空间中的 z 分量)。
Output_Sum =np.sum(np.multiply(Training_Data[datum,:], Weights))
输出节点必须对三个输入节点传递的值求和。我的 Python 实现首先对 Training_Data 数组 执行逐元素乘法。 和权重 数组,然后计算乘法产生的数组中元素的总和。
如果 Output_Sum <0: 输出值 =0 别的: 输出值 =1
if-else 语句应用单位步激活函数:如果总和小于零,则输出节点生成的值为 0;如果总和等于或大于零,则输出值为一。
更新权重
当第一次输出计算完成时,我们有权重值,但它们并不能帮助我们实现分类,因为它们是随机生成的。我们通过反复修改权重使神经网络成为一个有效的分类系统,使它们逐渐反映输入数据和期望输出值之间的数学关系。通过对训练集中的每一行应用以下学习规则来完成权重修改:
\[w_{new} =w+(\alpha\times(output_{expected}-output_{calculated})\times input)\]
符号 \( \alpha \) 表示学习率。因此,为了计算新的权重值,我们将相应的输入值乘以学习率以及预期输出(由训练集提供)与计算输出之间的差值,然后将乘法的结果相加到当前的重量值。如果我们定义 delta (\(\delta\) ) 为 (\(output_{expected} - output_{calculated}\)),我们可以将其重写为
\[w_{new} =w+(\alpha\times\delta\times input)\]
这是我在 Python 中实现学习规则的方式:
error =Expected_Output[数据] - Output_Value 对于范围内的 n(0, input_dim): 权重[n] =权重[n] + learning_rate*error*Training_Data[datum,n]
结论
您现在拥有可用于训练单层、单输出节点感知器的代码。我们将在下一篇文章中探讨有关神经网络训练理论和实践的更多细节。
嵌入式