

调试基于 Zephyr 的物联网应用的最佳实践
Linux 基金会 Zephyr 开源项目已经成长为许多物联网项目的支柱。 Zephyr 提供一流的小型、可扩展的实时操作系统 (RTOS),针对资源受限的设备在多个架构中进行了优化。该项目目前有 1,000 名贡献者和 50,000 次提交,为多种架构构建高级支持,包括 ARC、Arm、Intel、Nios、RISC-V、SPARC 和 Tensilica,以及 250 多个板。
与 Zephyr 合作时,有一些重要的考虑因素要保持事物的连接和可靠运行。开发人员无法在他们的办公桌上解决所有类别的问题,有些问题只有在设备数量增加时才会变得明显。随着网络和网络堆栈的发展,您需要确保升级不会带来不必要的问题。
例如,考虑我们部署 GPS 跟踪器来跟踪农场动物的情况。该设备是一种占地面积小、基于传感器的项圈。在任何一天,动物从移动网络漫游到移动网络;从一个国家到另一个国家;从一个位置到另一个位置。这种运动很快暴露了错误配置和意外行为,这些错误配置和意外行为可能导致断电,从而造成巨大的经济损失。我们不需要只知道一个问题,我们需要知道它为什么会发生以及如何解决它。使用联网设备时,远程监控和调试对于即时了解问题所在、解决该情况的最佳步骤以及最终如何建立和维护正常操作至关重要。
我们使用 Zephyr 和基于云的设备可观察性平台 Memfault 的组合来支持设备监控和更新。根据我们的经验,您可以利用这两者来建立使用重启、看门狗、故障/断言和连接指标进行远程监控的最佳实践。
设置可观察性平台
Memfault 允许开发人员远程监控、调试和更新固件,这使我们能够:
- 避免生产冻结,以支持最小可行产品和第 0 天更新
- 持续监控整体设备运行状况
- 在大多数(如果有)最终用户注意到问题之前推送更新和补丁
Memfault 的 SDK 可轻松集成以收集数据包以进行云分析和问题重复数据删除。它的工作原理类似于典型的 Zephyr 模块,您可以将其添加到清单文件中。
# west.yml [ ... ] - 名称:memfault-firmware-sdk 网址:https://github.com/memfault/memfault-firmware-sdk 路径:modules/memfault-firmware-sdk 修订版:大师 #prj.conf CONFIG_MEMFAULT=y CONFIG_MEMFAULT_HTTP_ENABLE=y
第一个重点领域:重启
假设您看到设备上的重置数量大幅增加。这通常是拓扑中的某些内容已更改或设备由于硬件缺陷而开始出现问题的早期指标。这是开始了解设备运行状况时可以收集的最小信息,它有助于从两部分考虑:硬件重置和软件重置。
硬件复位通常是由于硬件看门狗和掉电。软件复位可由固件更新、断言或用户启动引起。
在确定发生了哪些类型的重置后,我们可以了解是否存在影响整个队列的问题,或者是否仅限于一小部分设备。
记录重启原因
无效 fw_update_finish(void) { // ... memfault_reboot_tracking_mark_reset_imminent(kMfltRebootReason_FirmwareUpdate, ...); sys_reboot(0); } Zephyr 有一种注册区域的机制,这些区域将在 Memfault 挂钩的重置中保留。如果您要重新启动平台,我们建议您在开始之前进行保存。当您重启平台时,记录重启的原因——在本例中为固件更新——然后将其称为 Zephyr sys_reboot。
在 Zephyr 上捕获设备重置
注册用于读取启动信息的 init 处理程序
静态 int record_reboot_reason() { // 1. 读取硬件复位原因寄存器。 (查看 MCU 数据表中的寄存器名称) // 2. 从 noinit RAM 中捕获软件复位原因 // 3. 将数据发送到服务器进行聚合 } SYS_INIT(record_reboot_reason, APPLICATION, CONFIG_KERNEL_INIT_PRIORITY_DEFAULT); 您可以设置一个宏,通过 MCU 复位原因寄存器在复位前捕获系统信息。当设备重新启动时,Zephyr 将使用 system_int 宏注册处理程序。 MCU 复位原因寄存器的名称都略有不同,都很有用,因为您可以查看是否有任何硬件问题或缺陷。
示例:电源问题
让我们看一个示例,说明远程监控如何通过查看重新启动和电源供应情况来深入了解车队的健康状况。在这里,我们可以看到少数设备的重启次数超过 12,000 次(图 1)。
点击查看全尺寸图片

图 1:电源问题示例,超过 15 天的重启图表。 (来源:作者)
- 每天重启 12K 设备 - 太多
- 10 台设备贡献了 99% 的重启
- 导致设备不断重启的不良机械部件
在这种情况下,某些设备每天重启 1000 次,这可能是由于机械问题(部件损坏、电池接触不良或各种慢性速率问题)。
设备投入生产后,您可以通过固件更新来处理其中的许多问题。推出更新可让您解决硬件缺陷并避免尝试恢复和更换设备。
第二个重点领域:看门狗
在使用连接的堆栈时,看门狗是使系统恢复到干净状态的最后一道防线,而无需手动重置设备。挂起的原因有很多,例如
- send() 上的连接堆栈块
- 无限重试循环
- 任务之间的死锁
- 腐败
硬件看门狗是 MCU 中的专用外设,必须定期“馈送”以防止它们重置设备。软件看门狗在固件中实现,并在硬件看门狗之前触发,以捕获导致硬件看门狗的系统状态
Zephyr 有一个硬件看门狗 API,所有 MCU 都可以通过通用 API 来设置和配置平台中的看门狗。 (更多细节见 Zephyr API:zephyr/include/drivers/watchdog.h)
// ... 无效 start_watchdog(void) { // 查询设备树以获取可用的硬件看门狗 s_wdt =device_get_binding(DT_LABEL(DT_INST(0, nordic_nrf_watchdog))); 结构 wdt_timeout_cfg wdt_config ={ /* 当看门狗定时器到期时复位 SoC。 */ .flags =WDT_FLAG_RESET_SOC, /* 在最大窗口后过期看门狗 */ .window.min =0U, .window.max =WDT_MAX_WINDOW, }; s_wdt_channel_id =wdt_install_timeout(s_wdt, &wdt_config); const uint8_t 选项 =WDT_OPT_PAUSE_HALTED_BY_DBG; wdt_setup(s_wdt, options); // TODO:启动软件看门狗 } 无效 feed_watchdog(void) { wdt_feed(s_wdt, s_wdt_channel_id); // TODO:饲料软件看门狗 } 让我们使用 Nordic nRF9160 的这个例子来完成几个步骤。
- 转到设备树并设置 Nordic nRF watchtime 文件夹。
- 通过公开的 API 设置看门狗的配置选项。
- 安装看门狗。
- 在行为按预期运行时定期为看门狗提供信息。有时这是从最低优先级的任务中完成的。如果系统卡住,它将触发重新启动。
在 Zephyr 上使用 Memfault,您可以利用由定时器外设提供支持的内核定时器。您可以将软件看门狗超时设置为早于硬件看门狗(例如,将硬件看门狗设置为 60 秒,将软件看门狗设置为 50 秒)。如果回调被调用,则将触发断言,这将带您完成 Zephyr 故障处理程序,并获取有关系统卡住的那个时间点发生的情况的信息。
示例:SPI 驱动程序卡住
让我们再次看一个没有在开发中发现但在现场出现的问题的例子。在图 2 中,您可以看到 SPI 驱动芯片的时序、事实和退化。
点击查看全尺寸图片
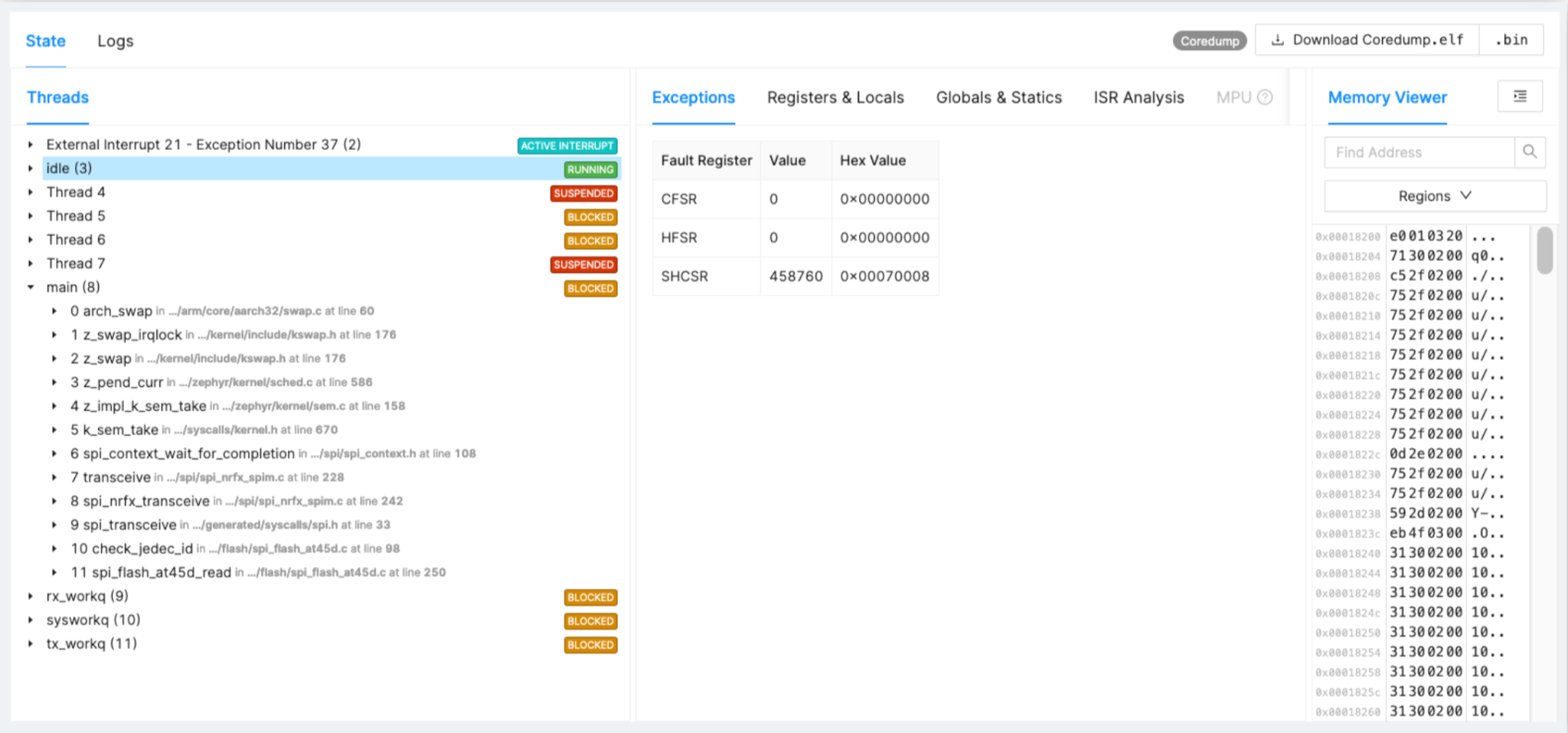
图 2:SPI 驱动程序卡住示例。 (来源:作者)
- SPI 闪存随时间退化,通信时间不正确
- 经过 16 个月的现场部署后,在 1% 的设备上进行了跟踪
- 驱动程序修复并在下一个版本中推出
对于 Flash,在该领域工作一年后,您会发现由于陷入 SPI 事务或各种零碎代码而突然开始出错。拥有完整的跟踪记录可以帮助您找到根本原因并制定解决方案。
下面的看门狗(图 3)正在启动 Zephyr 故障处理程序。
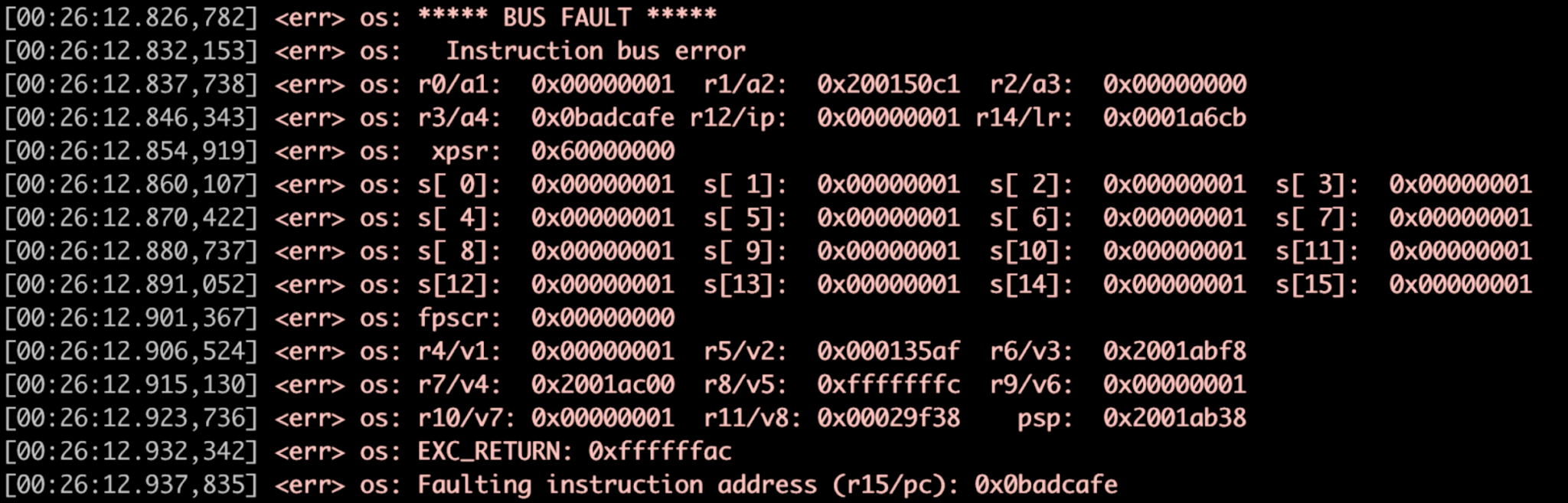
图 3:故障处理程序示例,寄存器转储。 (来源:作者)
第三领域焦点:故障/断言:
要跟踪的第三个组件是故障和断言。如果您曾经进行过一些本地调试或构建过您自己的一些功能,那么您可能会在平台上发生故障时看到类似的关于寄存器状态的屏幕。这些可能是由于:
- 断言,或
- 访问坏内存
- 除以零
- 以错误的方式使用外围设备
以下是在 Zephyr 上的 Cortex M 微控制器上采用的故障处理流程示例。
无效 network_send(void) { const size_t packet_size =1500; void *buffer =z_malloc(packet_size); // 缺少 NULL 检查! memcpy(buffer, 0x0, packet_size); // ... } ↓无效 network_send(void) { const size_t packet_size =1500; void *buffer =z_malloc(packet_size); // 缺少 NULL 检查! memcpy(buffer, 0x0, packet_size); // ... } ↓布尔 memfault_coredump_save(const sMemfaultCoredumpSaveInfo *save_info) { // 保存注册状态 // 保存_kernel 和任务上下文 // 保存选定的 .bss 和 .data 区域 } ↓无效 sys_arch_reboot(int type) { // ... } 当断言或故障启动时,将触发中断,并在 Zephyr 中调用故障处理程序,该处理程序提供崩溃时的寄存器状态。
Memfault SDK 自动拼接到故障处理流程中,将关键信息保存到云端,包括注册状态、内核状态以及崩溃时系统上运行的所有任务的一部分。
在本地或远程调试时需要注意三件事:
- Cortex M 故障状态寄存器告诉您平台断言或故障的原因。
- Memfault 可以恢复系统在崩溃前运行的确切代码行,以及所有其他任务的状态。
- 收集_kernel Zephyr RTOS 中的结构以查看调度程序,如果是连接的应用程序,则查看蓝牙或 LTE 参数的状态。
关注的第四个领域:跟踪设备可观察性的指标
通过跟踪指标,您可以开始构建系统上正在发生的事情的模式,并让您能够在您的设备和设备之间进行比较,以了解哪些变化正在产生影响。
一些有助于跟踪的指标是:
- CPU 利用率
- 连接参数
- 热量使用
使用 Memfault SDK,您可以使用两行代码在 Zephyr 上添加并开始定义指标:
- 定义指标
MEMFAULT_METRICS_KEY_DEFINE( LteDisconnect, kMemfaultMetricType_Unsigned)
- 在代码中更新指标
无效 lte_disconnect(void) { memfault_metrics_heartbeat_add( MEMFAULT_METRICS_KEY(LteDisconnect), 1); //... } Memfault SDK + 云
- 序列化和压缩传输指标
- 按设备和固件版本索引指标
- 公开网络界面,用于按设备和跨舰队浏览指标
可以按设备和固件版本收集和索引数十个指标。几个例子:
- NB-IoT/LTE-M 基本连接: 了解调制解调器如何通过连接或连接来影响电池寿命。
- 在 NB-IoT/LTE-M 中跟踪基站和 PSM: 如果不加以管理,移动信号质量可能会很糟糕,并且会耗尽电池寿命。为网络状态、事件、基站信息、设置、计时器等创建指标。监控变化并使用警报。
- 测试大型机队: 意外的大数据会增加设备连接成本并有助于识别异常值。
示例:NB-IoT/LTE-M 数据大小
点击查看全尺寸图片
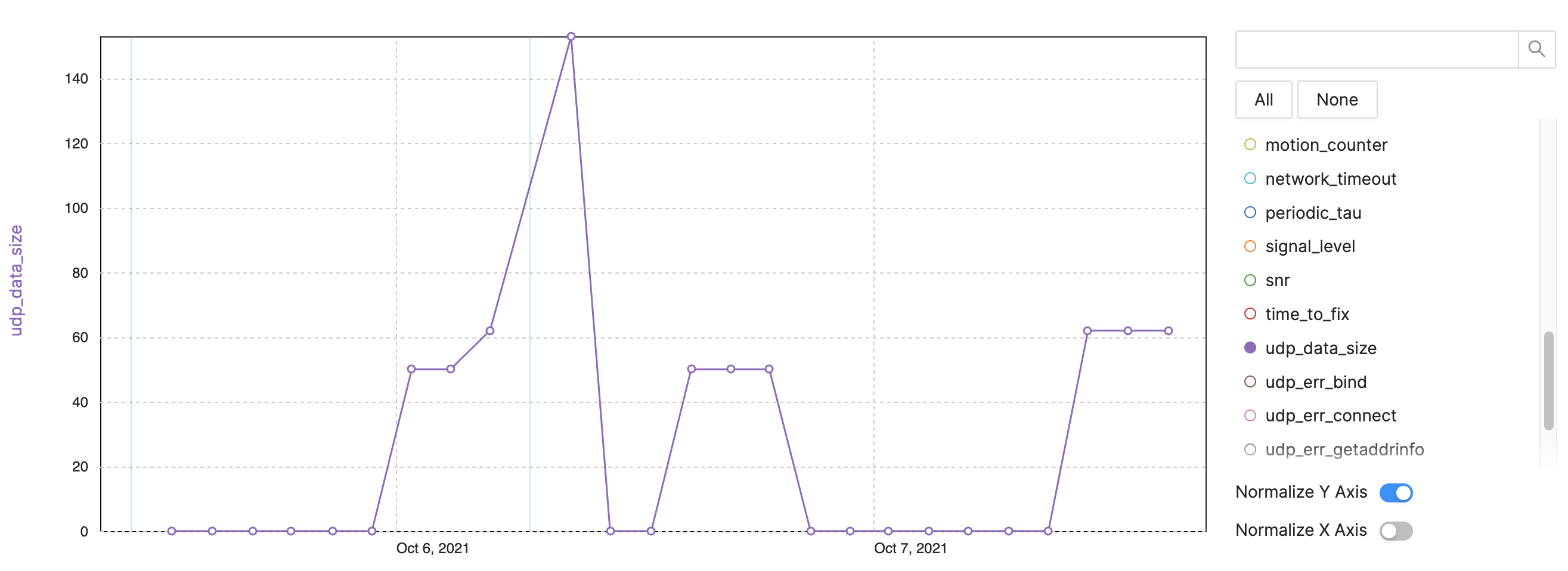
图 4:设备可观察性的跟踪指标 - NB-IoT 示例,LTE-M 数据大小。 (来源:作者)
- UDP 数据大小:每个发送间隔的跟踪字节数(图 4)
- 重启后发送更多数据
- 由于更多信息或跟踪,一些数据包更大
- 跟踪数据消耗问题
结论
利用 Zephyr 和 Memfault,开发人员可以实施远程监控,以更好地观察连接设备的功能。通过关注重启、看门狗、故障/断言和连接指标,开发人员可以优化物联网系统的成本和性能。
观看 2021 年 Zephyr 开发者峰会的录制演示,了解更多信息。
物联网技术