

FRACAS:将设备故障转化为业务胜利
在维护中,故障通常被视为负面结果,团队经常感受到停机指标的压力。然而,这种心态可能会适得其反且不公平。许多因素(例如资产寿命、设计限制或用户错误)无法立即控制。从战略角度来看,失败成为洞察力的宝贵来源。
“你需要失败才能改进,”Fiix 解决方案工程师、前工业和维护工程师 ThibautDrevet 说。 “失败可以帮助您了解正在维护的系统、它们如何运行以及如何维护它们。”
本文介绍了 FRACAS(故障报告、分析和纠正措施系统)如何将每次故障转化为推动业务成果的学习机会。
FRACAS 是什么?
FRACAS 是一个闭环报告框架,通过三个核心阶段捕获、解释和消除设备故障:
- 故障报告 - 识别确切的资产和故障事件。
- 故障分析 - 从事件中汲取教训。
- 纠正失败 - 实施更改以防止再次发生。
通过汇总一段时间内的性能数据,FRACAS 可以查明重复出现的故障模式,并为整个可靠性策略(从设计到维护计划)提供信息。
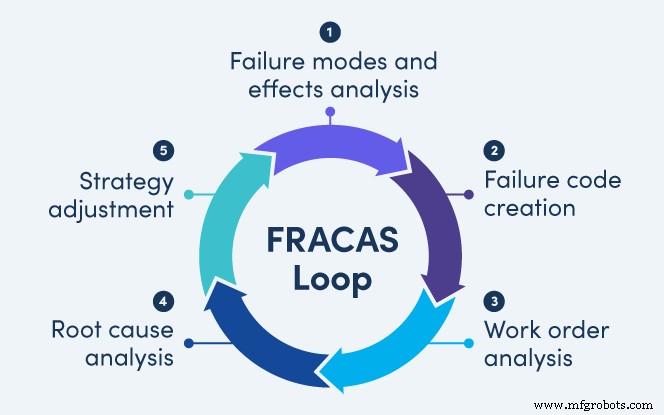
构建 FRACAS:连续循环
FRACAS 循环是一组可重复的活动,可让您不断学习和提高:
- 故障模式和影响分析 (FMEA)
- 创建失败代码
- 工单分析
- 根本原因分析 (RCA)
- 策略调整
故障模式和影响分析 (FMEA)
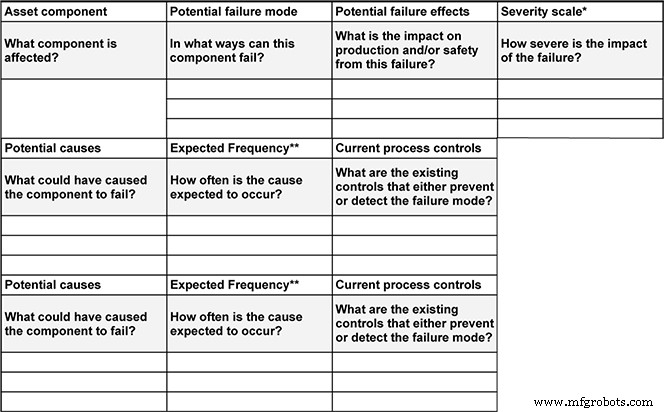
FMEA 是一种先发制人的工具,列出了每种可能的故障模式、其影响以及缓解步骤。典型的 FMEA 包含十个关键要素:
- 资产组件
- 潜在的故障模式
- 潜在的故障影响
- 失败的严重程度
- 潜在原因
- 预期失败频率
- 当前的检测和预防流程
- 可检测性
- 总体风险
- 建议采取的措施
FMEA 是 FRACAS 的基础。它根据资产重要性、影响和可用资源确定行动的优先顺序,并随着新数据的出现而发展。
创建故障代码
故障代码将复杂的事件提炼为简洁的标识符,例如“轴承、磨损、缺乏润滑。”
- 对每个部分使用清晰的命名约定以避免混淆。
- 为了清晰起见,按状况(磨损、过热等)对缺陷进行分组。
- 将预加载的代码限制为最常见的代码 - 超过 10 个代码会分散注意力。
- 与技术人员一起验证代码列表以确保相关性。
跟踪代码显示趋势,使您能够首先定位代价最高的故障。
工单分析
单一事件令人滋扰;重复的模式表明存在系统性问题。通过查看故障代码和完成注释,您可以发现高频问题。
示例:四台机器在六个月内记录了 12 次故障,其中 10 次归因于轴承不对中导致卡死。在接下来的六个月内将这一数字减少到两次,这表明纠正措施正在发挥作用。
我们的工单数据指南 中介绍了其他分析方法 .
根本原因分析 (RCA)
RCA 从故障排除中获取长期价值。重复的简单修复会浪费时间、金钱和零件。
使用未对准的轴承示例,RCA 的五个原因可能会揭示:
- 为什么?由于轴未对准,轴承未对准。
- 为什么?机器组装不正确。
- 为什么?技术人员赶紧组装。
- 为什么?技术人员没有足够的时间。
- 为什么?生产前的维护窗口太窄。
Thibaut 建议为 RCA 组建不同的团队,以避免过早下结论。
策略调整
见解必须转化为行动。调整可以是小调整(添加润滑说明),也可以是大调整(例如聘请专家来执行超出团队专业知识的任务)。
- 让技术人员参与:分享理由和预期收益。庆祝胜利,例如下班后通话次数减少 40%。
- 监控结果:及早发现意外副作用并不断迭代直至成功。
- 逐步扩展:在向整个工厂推广之前在一台机器上测试更改。
关闭循环
实施更改后,重新审视 FRACAS 周期:
- 使用新的故障和缓解措施更新 FMEA。
- 审核失败代码 - 根据需要添加、删除或优化。
- 生成影响报告:跟踪故障频率的减少、成本节约和调度改进。
确保 FRACAS 的高质量数据
可靠的数据是 FRACAS 的命脉。以下是保护它的方法。
创建维护价值文化
数据不准确往往是由于技术人员匆忙造成的。将维护视为生产推动者的文化鼓励仔细的数据输入。
“维护并不是生产的敌人,”蒂博说。 “当每个人都看到它的价值时,技术人员就会花时间记录准确的信息。”
设计清晰、简单的工单
模糊或密集的工作指令会导致错误。通过包括以下内容来简化:
- 用于组件识别的图片和图表。
- 清晰的命名约定。
- 简洁的报告工作流程。
入门资源:
自动化和集成
状态监测软件用实时数据取代了手动仪表读数,消除了记录变化值的风险。
将此数据集成到您的维护平台中可以实现即时警报和综合分析。
定期数据审核
每月抽查和技术人员访谈会发现系统性数据差距。问:
- 是否不需要进行任何检查任务?如果是这样,请将其删除或证明其合理性。
- 技术人员知道要记录什么内容以及原因吗?
- 数据输入过程是否方便用户操作?
推动成果的五份 FRACAS 报告
使用这些报告来识别阻碍生产和盈利能力的故障。
- 启动后失败 – 在生产开始之前查明导致生产停止的问题。
- 按故障代码列出的维护成本 – 汇总劳动力和零件成本,以优先考虑影响较大的故障。
- 按故障代码划分的维护时间 – 确定耗时的重复修复。
- 计划内维护与计划外维护失败 – 突出反应性维护驱动因素。
- 因班次或站点而导致的故障 – 发现可以在其他地方复制的流程或培训差距。
真实世界的 FRACAS 成功案例
FRACAS 可以超越文档,成为一种文化转变。示例:
- 识别与旧零件相关的频繁故障,揭示隐藏成本,从而实现更强大的库存预算。
- 在生产线变更后检测到新的故障模式,从而改进了通信流程,从而减少了多个站点的停机时间。
- 优先处理本季度影响较大的单一故障,从而获得资金来扩大技术团队,解决其他问题。
结论
构建 FRACAS 需要数据、时间和持续的承诺。从小事做起,庆祝早期的胜利,并坚持下去。长期投资回报率(减少停机时间、降低维护成本和更具弹性的运营)将证明这些努力是值得的。
设备保养维修