

微软推出 AttnGAN:将文本描述转化为逼真图像的人工智能
- Microsoft 的 AttnGAN 可以从纯文本和字幕生成高保真图像。
- 该系统采用双模型架构:生成图像的生成器和评估其真实性的鉴别器。
- 它在提示之外添加了上下文相关的详细信息,展示了内部“想象力”层。
- 未来的潜在应用包括由脚本引导的全自动动画制作。
虽然之前的努力已经改进了文本到图像的合成,但 Microsoft 的 AttnGAN 通过利用大量标记图像库,根据简洁的文本提示生成逼真的图像,从而推动了该领域的发展。
AttnGAN 由微软研究院开发,可解析提示中的单个单词以指导图像构建。据该团队称,该方法的图像质量比之前最先进的模型高出大约三倍。
机器人的创作过程
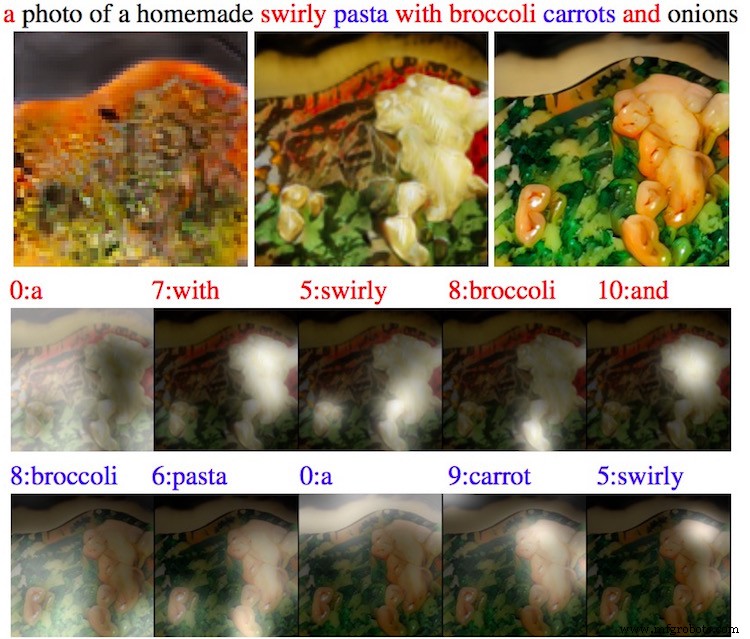
想象一下,有人要求画一只蓝色的鸟,有红色的翅膀和短喙。您将从粗略的轮廓开始,然后填充颜色和细节。 AttnGAN 遵循相同的逻辑,分析每个单词以构建详细、连贯的图像。
该机器人可以渲染任何主题(从小工具到野生动物),并且经常添加未明确提及的与上下文相关的背景元素,展示其“想象”细节的能力。
图像是从头开始逐像素合成的,允许模型创建现实中可能不存在的场景。这种生成任务本质上比仅仅标记现有照片更复杂。
AttnGAN 如何生成图像
- 生成器: 根据文字描述创建图像。
- 鉴别器: 根据描述评估生成图像的真实性。
两个模型都经过联合训练,使生成器能够从鉴别器的反馈中学习并逐渐实现更高的保真度。
训练涉及数千个配对的照片字幕数据集,教 AttnGAN 将特定单词映射到视觉模式。例如,“大象”一词会触发模型生成与典型大象外观相匹配的图像。
该系统将复杂的句子分解为单独的单词,将每个单词与图像的一个区域对齐。在训练过程中,它还会学习“人工常识”来填补缺失的细节,确保构图真实。

在这个例子中,提示只提到了一只鸟。 AttnGAN 智能地将这只鸟放在树枝上,这是从训练数据中学习到的常见现实世界环境。这证明了模型应用上下文知识的能力。
arXiv:1711.10485 – 微软研究论文详细介绍了 AttnGAN。
当被挑战描绘一辆漂浮在湖上的双层巴士时,该模型产生了一个模糊但可识别的混合场景,突出了它在调和提示中的冲突元素方面的努力。
性能和用例
AttnGAN 超越了之前的基准,在 COCO 数据集的 inception 分数上实现了 170.25% 的提升,在 CUB 数据集上实现了 14.14% 的提升。
潜在的应用包括室内设计师的草图助手、声控照片细化,以及进一步开发的完全自动化的剧本动画制作。
其他人工智能艺术生成器
微软并不是唯一一家将艺术与人工智能融合在一起的公司。谷歌的 DeepDream 创建了 2016 年展示的迷幻图像,而其人工智能则制作了音乐和语音合成,例如 Tacotron2。Facebook 和 Nvidia 还发布了汽车、船舶、动物甚至合成名人头像的生成模型。
了解 Google 的类人语音 AI Tacotron2 .
工业技术